PDF 复制中的文字重复问题
前两天,编辑 @⽂⼑漢三 在 Slack 上发给我一个 PDF 文件,问我知不知道为什么从里面复制出的中文会出现「重字」现象。他还提到,这个问题只在用系统自带的预览 app 打开时会出现,用其他 PDF 阅读器复制文字是正常的。

文刀拿这个问题来问我,恐怕是因为我之前写过一篇解释 PDF 格式的文章,觉得我大概会知道答案。不过他其实高估了我的知识水平——我刚开始也不知道这是怎么回事。不过,经过一番搜索,我最终初步搞清楚了问题成因。因为这个问题涉及到一些很有意思的细节,这里把探索的过程写出来,供有类似疑问的朋友参考。
出现问题的 PDF 文档是由一篇少数派文章导出而得的。首先尝试复现问题:用预览 app 打开并随手复制一段,确实出现了很多重复的文字,看起来就像是「结巴」了一样,有一种莫名的喜感。换用 PDF Expert 打开再尝试复制,则没有这样的问题。

虽然不知道问题的具体成因,但根据经验,文字复制中的故障往往与编码有关,而 PDF 格式正是编码问题的大户。
我在之前的文章中提到,PDF 格式是「不识字」的。在显示文字时,阅读器只是机械地根据 PDF 语句的指令,将字体资源中特定码位的字形绘制在坐标指定的位置,而并不关心自己画出来的到底是什么字。只有在进行复制、搜索等操作时,PDF 才会根据内嵌的 CMap,将内部字体的编码和 Unicode 编码对应起来。因此,如果 CMap 缺失或损坏,就无法从 PDF 中正常复制文字,但并不影响文档的外观。
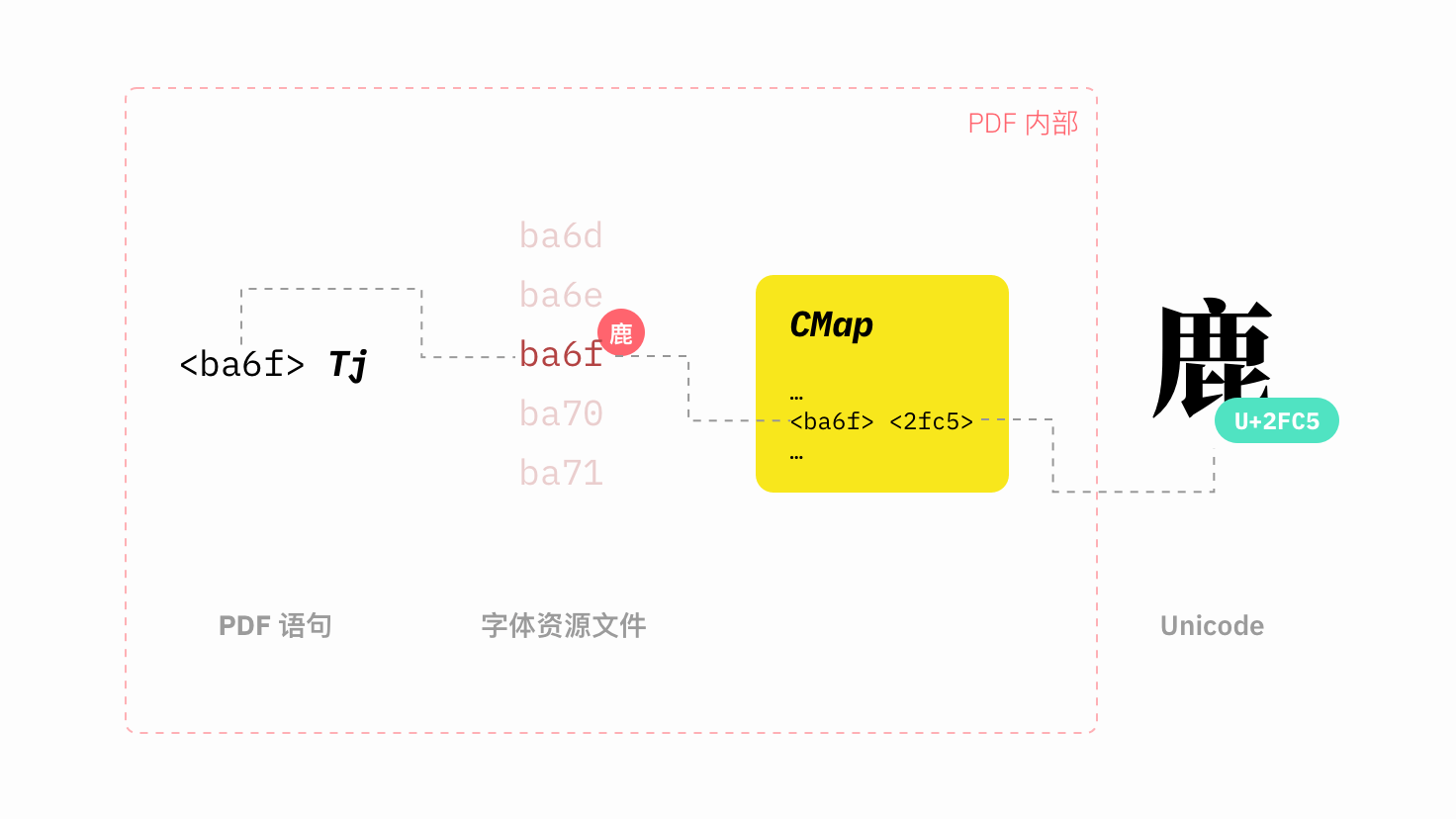
这次的问题会不会也跟 CMap 有关呢?这就要查看 PDF 的源码才能知道。不过,大多数 PDF 都经过压缩,用文本编辑器直接打开是不可读的。为此,我们首先用 qpdf 将其解压:
qpdf --stream-data=uncompress sspai.pdf sspai_unzip.pdf
这样,就可以用任意文本编辑器打开查看代码了。但即使如此,PDF 的源码结构也很混乱,从头翻看很难找到头绪。因此,我们可以找准一个小处入手——例如标题中的这个「工」字。
查询 Unicode 字符表,可以知道「工」字的编码是 U+5DE5。既然 PDF 中有「工」字,那么源码中的某处一定会提到 5de5 这个编码。确实,简单搜索一下就可以找到这么一段:
1 beginbfchar
<0ae1><2f2f 5de5>
endbfchar
其中,beginbfchar 和 endbfchar 正是 CMap 所用的语句。根据 PDF 语法,它表明 PDF 内嵌字体中编码为 0ae1 的字形,对应 Unicode 编码为 U+2F2F 和 U+5DE5 的两个字符。
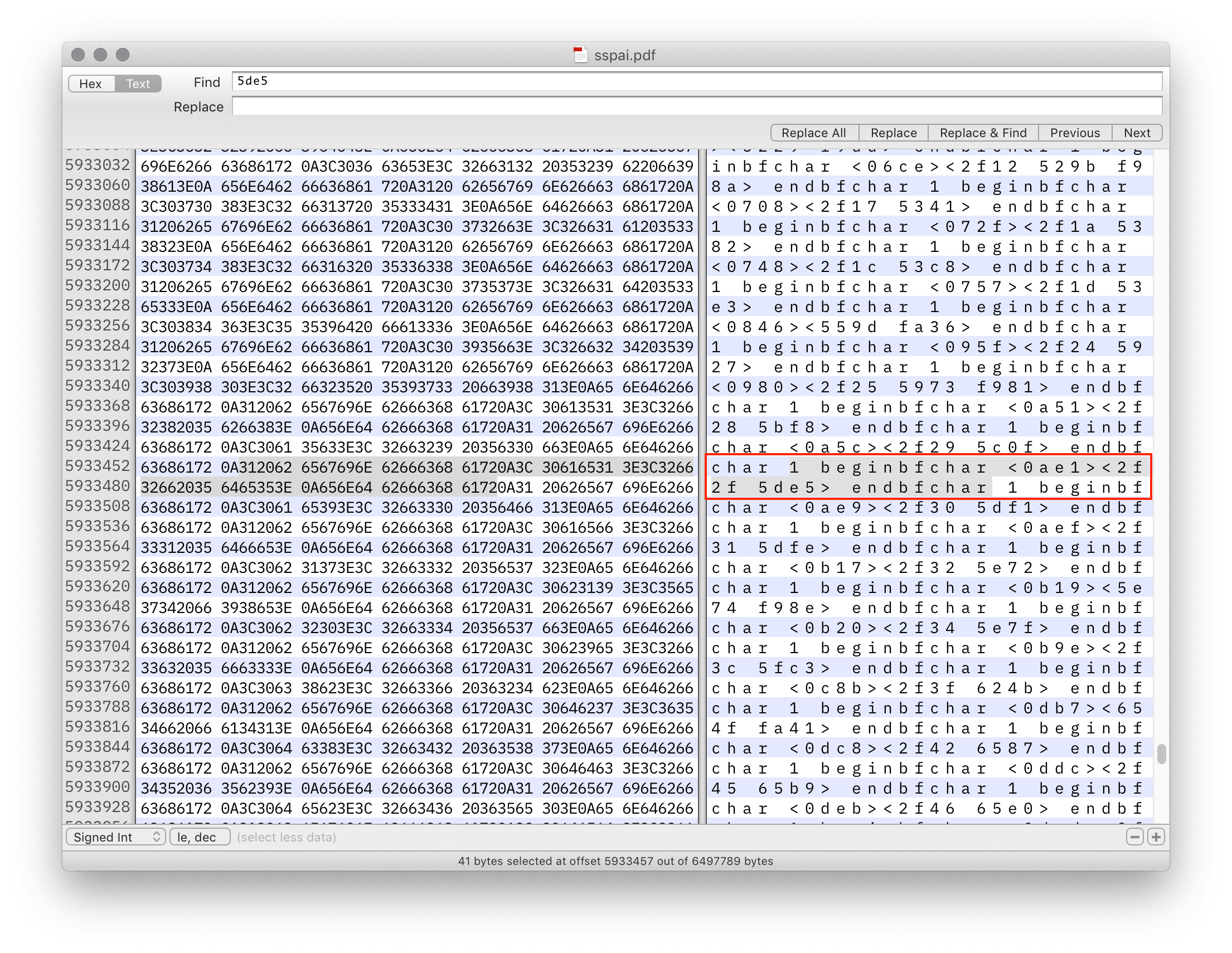
奇怪了,为什么是两个字符?
我们已经知道,U+5DE5 就是汉字「工」,那这个多出来的 U+2F2F 又是什么?再次查询 Unicode 表,会发现 U+2F2F 竟然也是「工」。这两个字符是什么关系?它们是一回事吗?
答案是否定的。仔细看一下两个字符的 Unicode 信息:U+5DE5 的全名是「Ideograph labor, work; worker, laborer CJK」,位于 CJK Unified Ideographs(中日韩统一表意文字)区块。显然,这就是我们日常所用的汉字「工」。
另一方面, U+2F2F 的全名是「Kangxi Radical Work」,其所在区块是「Kangxi Radicals」(康熙字典部首)。换句话说,两个「工」虽然长得一模一样,但身份并不相同,一个是汉字,另一个是部首。
这样一来,我们也就知道预览 app 是怎么复制出「重复」的文字了。
实际上,它并没有复制出来两个一样的「工」字,而是同时复制出来了两个不同的字符——前一个是作为部首的「工」,后一个才是真正的汉字「工」。将预览的复制结果粘贴到文本转 Unicode 编码工具里,就能看得很明显:
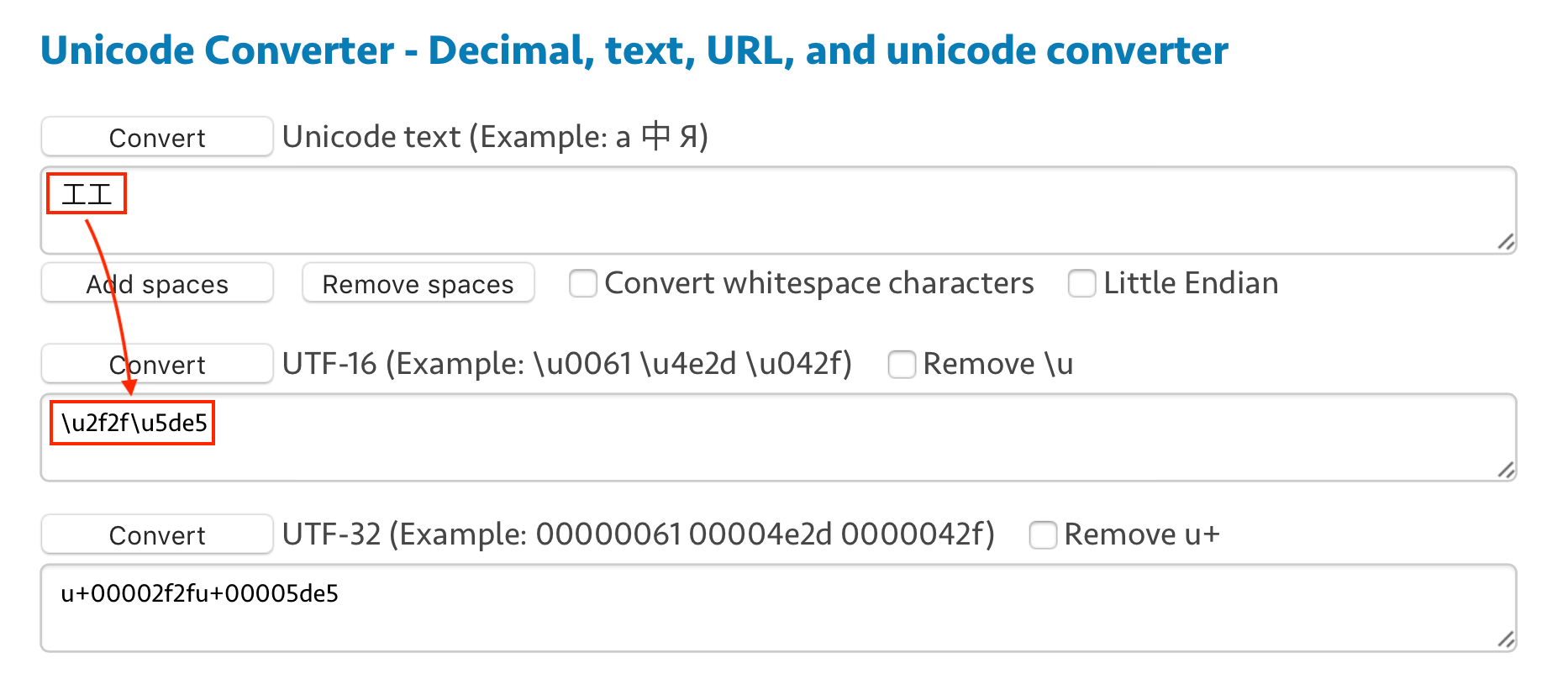
不过,PDF 为什么要在 CMap 中作这样「一对多」的映射呢?的确,从预览 app 的角度看,它或许还有理由感到一点小委屈:我做错了什么,PDF 明明告诉我这是两个字啊?
回答这个问题,就要先了解「康熙字典部首」区块中的字符的用途。对此,这个网页解释得很清楚(原文为繁体中文;粗体为笔者所加):
既然全部部首的字元都在另一个地方编了码,那么为何要再次编码呢?据统一码(即 Unicode——笔者注)的文件指出,本区块的字元只作部首之用,不应该当作一般文字用途,文件更进一步提出,必要时甚至可以用不同的字型格式,表明是属于本区块的字元。换句话说,例如编辑一本字典,部首页、部首标题和「参见某部若干画」等文字,都应使用本区块内的字元;而内文和字头、词条等文字部分,则应使用「中日韩统一表意文字区块」中的字元。这样做的原意,是希望让机器知道该字元现时所充当的角色:是「一般文字」,还是「部首文字」。当然,这些分别对人类来说可能没有作用,但对机器的语意分析是十分重要的。
实际上,类似的需求在使用拉丁字符的语言中同样存在。最典型的是西文排版中所谓「合字」(ligature)的概念,即针对 ff、fi 这样笔画容易「打架」的字符组合,将其当作一个整体来专门设计造型。因此,这些字符组合在 Unicode 中需要有独立的码位,如 ff (U+FB00)、fi (U+FB01) 等(请试着动手复制一下这些字符)。可是,合字在显示时是一个整体,而在复制和搜索时却要看作两个独立的字符。而在 PDF 中,合字的这种双重身份也正是通过 CMap 的「一对多」映射实现的。
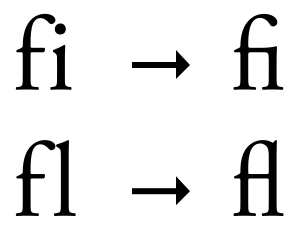
因此,复制文字重复的故障,其责任并不在于 PDF 的编码。「一对多」的映射并不是一种冗余或者混淆,而是为了适应机器和用户的不同需要而必须加入的特殊处理。说到底,还是预览 app 的优化功夫没下到家,没有意识到 PDF 文本在显示、复制、搜索时应该受到不同的对待。这也再次应证了我之前文章中的一个观点:PDF 阅读器很多时候拼的不是功能有多丰富(反正都拼不过亲儿子 Acrobat),而是能不能做好复制、搜索这些基础功能的细节。