挖掘 Safari 阅读列表的潜力
Safari 阅读列表是 macOS 和 iOS 上一个比较容易被忽视的功能。该功能最初出现在 2011 年的 OS X Lion 和 iOS 5 系统中,但除了在次年加入了离线缓存,它基本就在这八年间一成不变,与 Pocket、Instapaper 等专职的稍后读服务相比显得十分简陋。
我自己之前也很少使用阅读列表功能,而是用 Pinboard 结合 Instapaper 解决稍后读的需求。这套组合虽然总体让我满意,但也不是尽善尽美,最明显的不足就在于添加链接时的繁琐。特别是在那些没有分享按钮的界面,每添加一个链接都要经历长按链接—选择「分享」—点击应用图标三个步骤。在需要连续保存很多链接时(例如阅读 newsletter 或播客的 show notes),重复这套繁琐的步骤接近一种折磨。另外,Instapaper 的同步也受到 iOS 对后台进程的限制,在信号不好时添加的链接,往往需要事后手动刷新一次才能反映在其他设备上。
相比之下,作为系统自带功能,Safari 阅读列表具有第三方应用难以企及的特权。「添加到阅读列表」的选项几乎无处不在,并且总是处于第一级菜单的显著位置,新增链接在任何时候不会需要超过两次点击。不仅如此,阅读列表作为一个系统服务,可以始终保持后台运行,并且通过 iCloud 近乎即时地在各设备间同步。
发现了这些优点后,我在近几个月试着更多地利用 Safari 阅读列表。为了扬长避短,我主要在两种场景下使用这一功能:其一,将阅读列表作为暂存空间,用来处理一些不需要长久保存的页面;其二,将阅读列表作为第三方工具的「前端」,利用它保存链接时的便捷,然后通过脚本将其内容自动同步到其他稍后读服务。
将阅读列表作为暂存空间
尽管阅读列表的功能比较贫乏,但这种简洁也让它成为了暂存网页的理想位置。对于那些在浏览时偶尔撞见、想要短暂保存的页面,认认真真添加书签并打上标签显得有点浪费时间;不少网页也不属于文章的范畴,因此稍后读工具也不是合适的归宿。这些时候,阅读列表就成为了比较理想的选择。
阅读列表的使用非常简单,没有什么需要特别说明的地方,不熟悉的用户可以阅读苹果的官方支持文章(iOS 版、Mac 版)来比较全面地了解。不过,阅读列表功能也有一些比较隐蔽的技巧,记忆之后,可以进一步提高将其作为链接暂存工具的效率。
添加阶段:
- 在 iOS 版 Safari 中,添加到阅读列表的最快方式是长按工具栏中的书签图标,然后选择相应选项;在 Mac 上,最快的方法则是使用快捷键 ⇧⌘D。
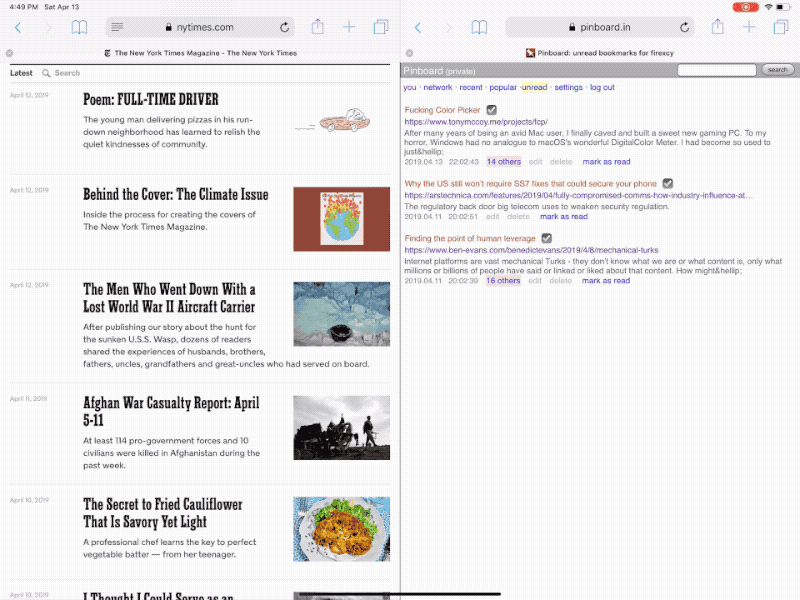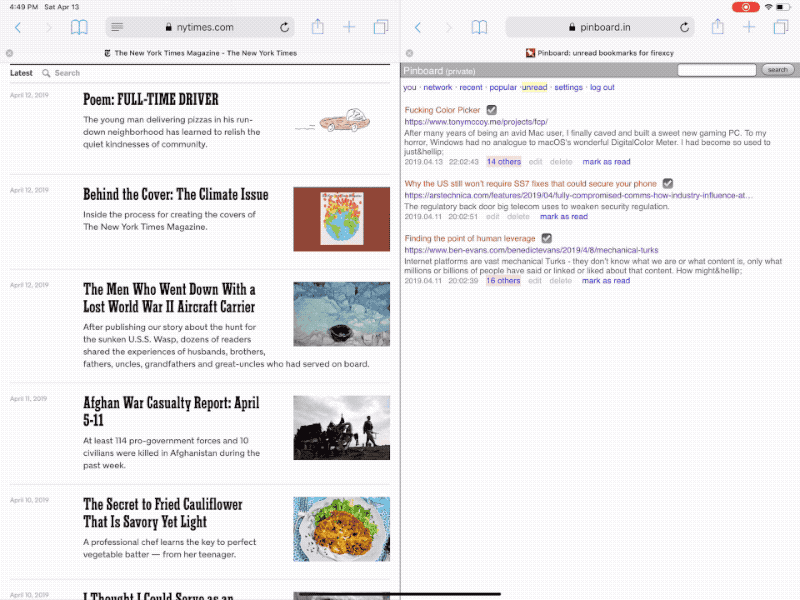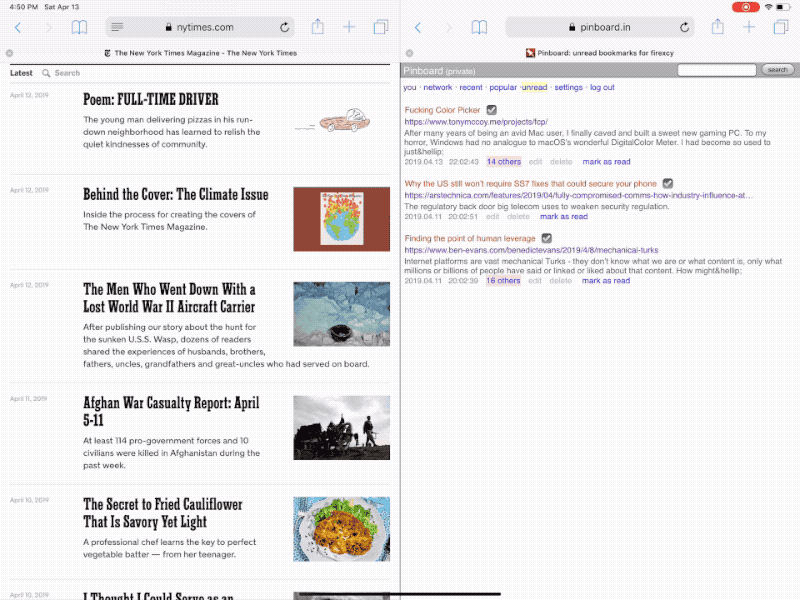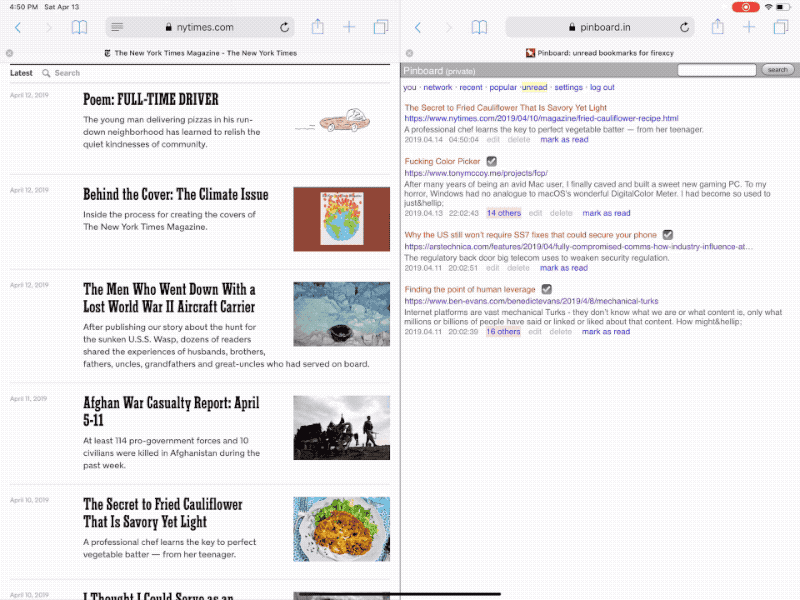
- 在 iPad 上,阅读列表界面支持拖放,并且可以批量操作:既可以从其他应用中选中多个链接拖放添加到阅读列表中,也可以从阅读列表中选择多个项目一并拖出。
- 在 Mac 版 Safari 中,可以通过「书签」-「将这 x 个标签页添加到阅读列表」菜单项将当前打开的所有标签页批量添加到阅读列表;该功能尤其适用于针对特定话题检索资料的使用场景,可以一定程度上弥补 Safari 没有 OneTab 一类插件的不足。
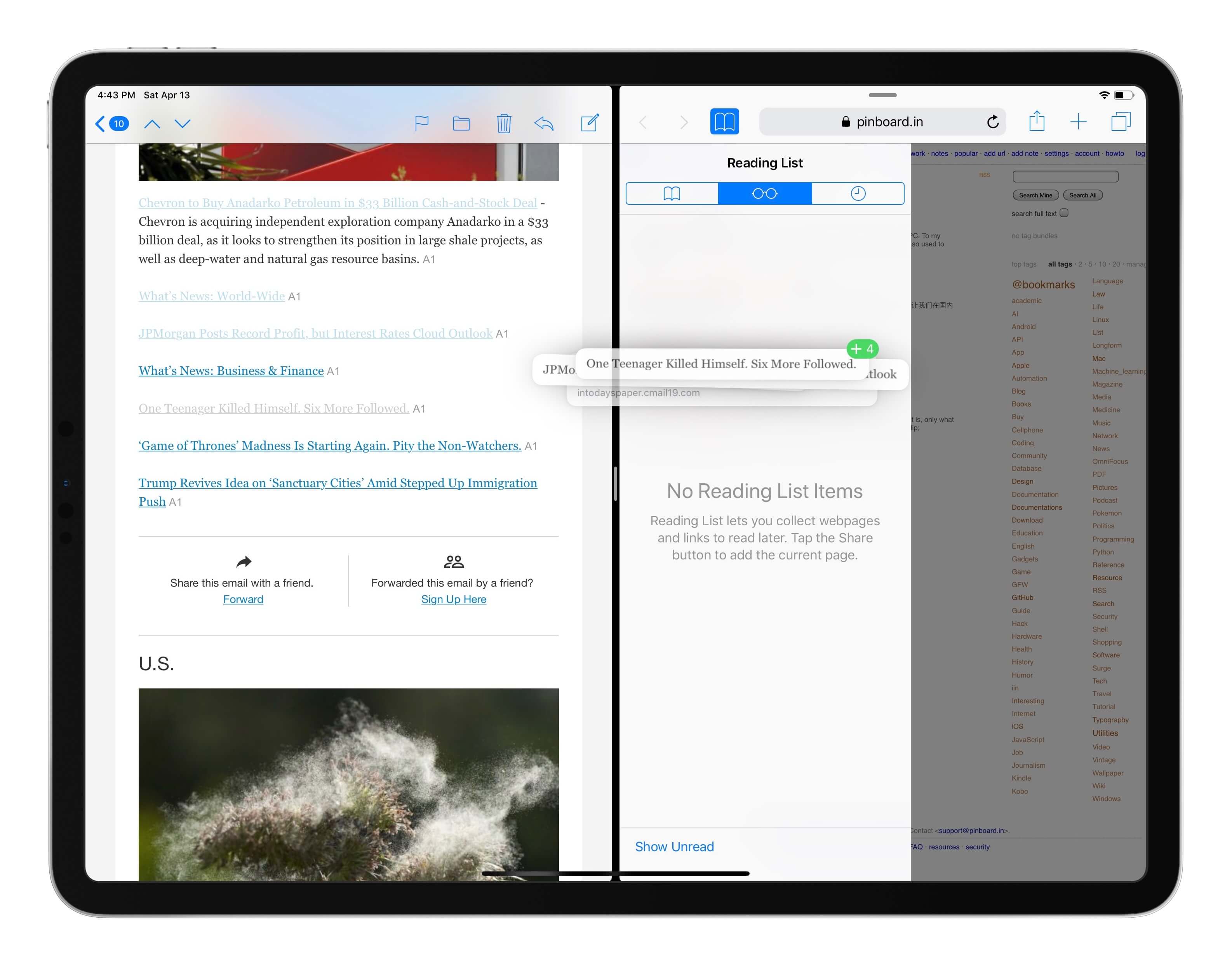
用拖放手势在 iPad 上批量添加阅读列表链接
管理和阅读阶段:
- Safari 阅读列表支持离线缓存,但默认没有开启。
- 在 Mac 上,这一选项位于 Safari 偏好设置中的「高级」选项卡下,通过勾选「自动存储文章以便离线阅读」开启。
- 在 iOS 上,这一选项位于「设置」>「Safari 浏览器」,然后打开「阅读列表」下方的「自动离线存储」。
- iOS 似乎不会很及时地清理阅读列表缓存。手动清理的方法是进入「设置」>「通用」>「iPhone (iPad) 存储」>「Safari 浏览器」,然后向左划动「离线阅读列表」项目。
- 从阅读列表界面的顶部向下划动可以看到搜索框,其搜索范围包括网页标题、链接和摘要。
- 在 Mac 版 Safari 中,右键单击阅读列表的空白位置可以找到清空阅读列表的选项。
- 读到一个网页的底部后,继续向下滚动可以直接跳转到阅读列表中的下一个网页;从网页顶部向上滚动则会跳转到上一个网页。在 Mac 上,还可以通过 ⌥⌘↑/↓ 快捷键切换阅读列表中的项目。
打通阅读列表和第三方服务
前面提到,阅读列表的主要优势在于和系统的紧密整合,但管理和阅读功能则明显逊于第三方服务。因此,一个自然的思路就是将这两者结合起来,将阅读列表作为一个纯粹的链接收集工具,以利用其在添加链接时的便捷性,而管理和阅读则仍然在更专业的应用中进行。
然而,阅读列表体现了苹果软件一贯的封闭性,本身并不提供任何导出功能。好在,阅读列表的实现机制并不复杂,通过简单的脚本即可获取其内容并导出到其他工具中。
阅读列表的工作原理
在介绍具体的方法之前,首先铺垫一下阅读列表的工作原理。在实现层面,Safari 阅读列表是与 Safari 书签一起存放和同步的。实际上,阅读列表不过是收藏夹中一个特殊的文件夹。
在 macOS 上,阅读列表的路径位于 ~/Library/Safari/Bookmarks.plist。原始状态下,该 plist 文件是以二进制格式存储的;我们可以通过
plutil -convert xml1 -o Bookmarks.xml Bookmarks.plist
转换出一份可读的 XML 格式副本以观察其内部结构。
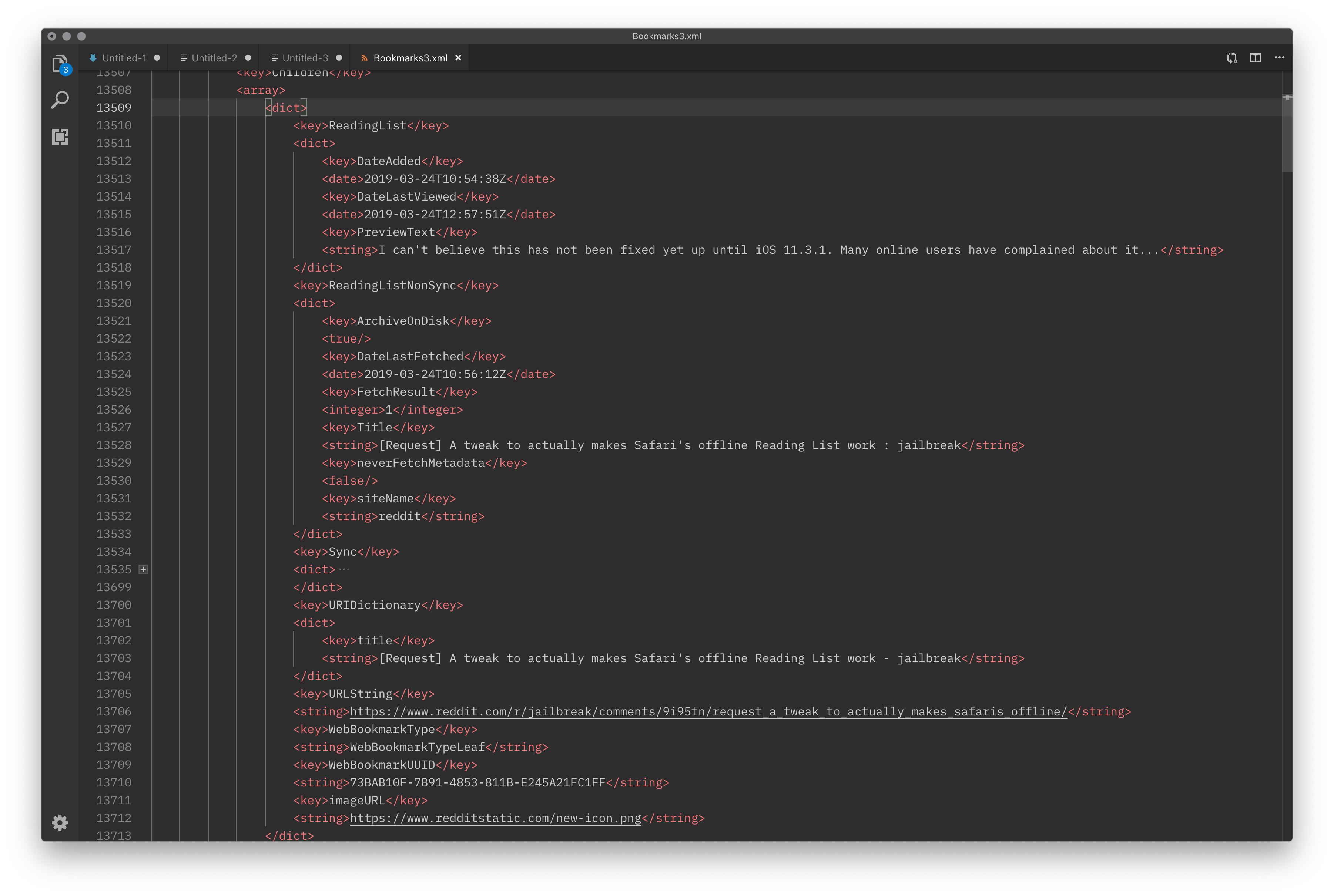
转换为 XML 后的阅读列表文件结构
可以看到,针对每条阅读列表中的链接,Safari 存储的信息包括其标题、URL、摘要、缩略图链接、添加日期和最近打开日期等。从 ReadingListNonSync 这一子键名称及其包含的内容还可以看出,阅读列表中网页的缓存是不会被同步的,每台设备都会自己重新抓取一次网页信息及其缓存。(网页缓存位于 ~/Library/Safari/ReadingListArchives 目录下,以 Web Archive 格式存储。)
iOS 上,阅读列表的存储位置稍有差别,位于 /private/var/mobile/Library/Safari/Bookmarks.db 这一数据库文件中,但仍然和普通书签一起存储。根据数据库各列的名称可以看出,其存储的信息和 macOS 上的 Safari 基本是一一对应的。
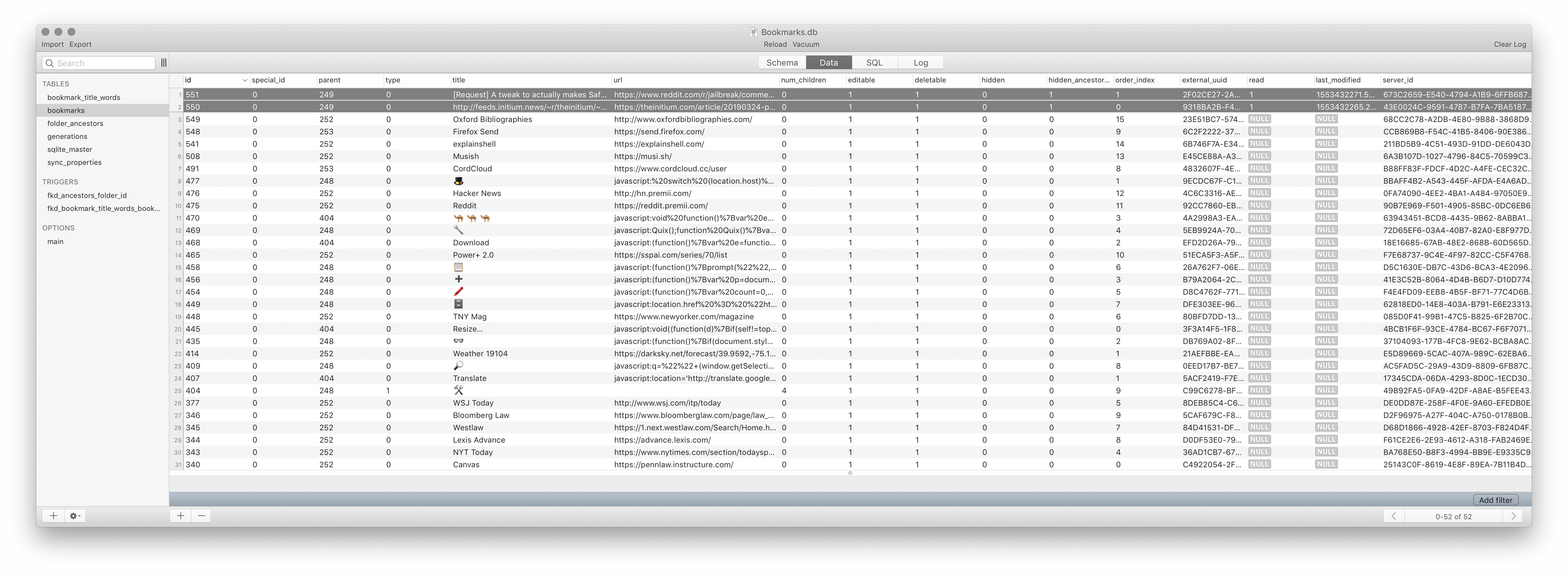
iOS 上的 Safari 书签数据库
可见,要实现将阅读列表和第三方服务打通,只需要 (a) 解析 Bookmarks.plist 文件,将其中的阅读列表链接通过第三方服务的 API 保存到后者中;和 (b) 监控 Bookmarks.plist 文件的变动,在新链接被添加到阅读列表时同步地将其保存到其他服务。
解析 Bookmarks.plist 文件
对于 (a),GitHub 上可以找到现成的解决方案:ReadingListReader。这是一组基于 Python 的脚本,其功能正是解析 Bookmarks.plist 文件并将其导出为 HTML、CSV 格式,或者发送到 Pocket/Instapaper/Pinboard。
以导出到 Pocket 为例。先在 Pocket 网站上新建一个私人应用,保存得到的 Consumer Key。接着,编辑上述项目中的 readinglist2pocket.py 文件,填入该 Consumer Key。这样,就可以通过在终端运行:
ReadingListReader $ python ./readinglist2instapaper.py
将阅读列表导出到 Pocket。导出到 Pinboard 或 Instapaper 的方法同理,在此不赘。
监控 Bookmarks.plist 文件的变动
剩下的问题就是如何监控阅读列表的变动,实现新增链接时自动通过上述脚本发送到第三方服务。最简单的方法是使用 Hazel。在 Hazel 中,新建一条针对 ~/Library/Safari 文件夹的规则,并设定两个匹配条件:
- 文件全名为
Bookmarks.plist(注意「Full Name」和「Name」的区别,后者不包括扩展名); - 上次匹配日期(Date Last Matched)早于上次修改日期(Date Last Modified)(换句话说,文件在上次被匹配后又发生了变动)。
匹配后的动作则是运行终端脚本(Run Shell Script):python /path/to/script/readinglist2pinboard.py (以发送到 Pinboard 的脚本为例)。
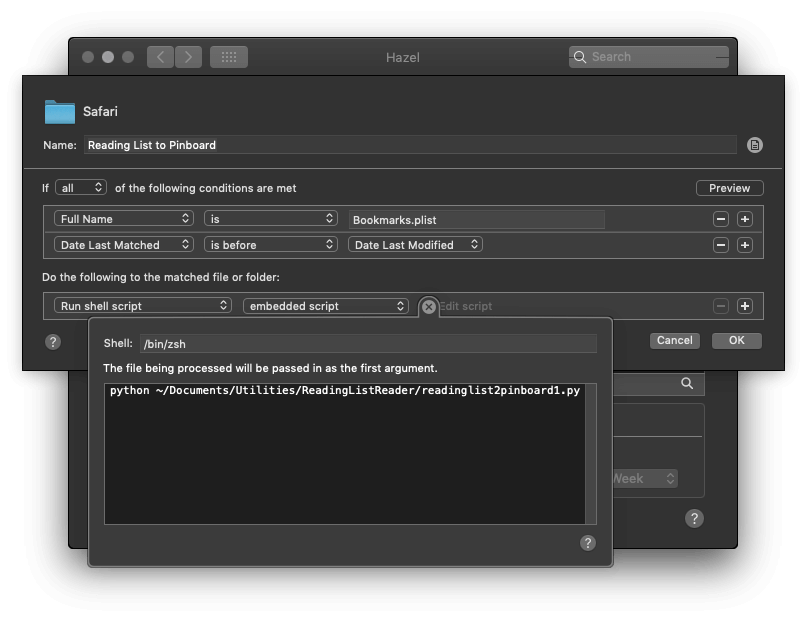
Hazel 动作示例
两点需要说明的问题:
- Hazel 的使用理论上不是必须的,但这是我唯一了解的、可以简便监控单个文件变化的工具(系统自带的 Automator 只能实现文件夹层级的监控),欢迎了解替代方法的读者指教。
- 显然,上述方法依赖于一台持续开机并在线的 Mac。如果你用的是 MacBook 并且需要扛着它四处跑,那么这种方法的效果肯定会大打折扣。然而,在苹果不进一步开放该功能的前提下,这已经是最接近「同步」的权宜之计。
用 Mercury 改进网页信息抓取效果
尽管阅读列表会自动抓取网页的标题、摘要等信息,但并不十分智能。根据经验,如果添加的链接是有付费墙的网页或短链接、跳转链接等,阅读列表有很大可能无法正确获取网页信息。这对将其同步到 Instapaper 或 Pocket 影响不大,因为它们本身会对添加的链接重新进行处理;但如果你和我一样准备把它和 Pinboard 同步,可能就需要一些额外步骤来应对上述缺陷。
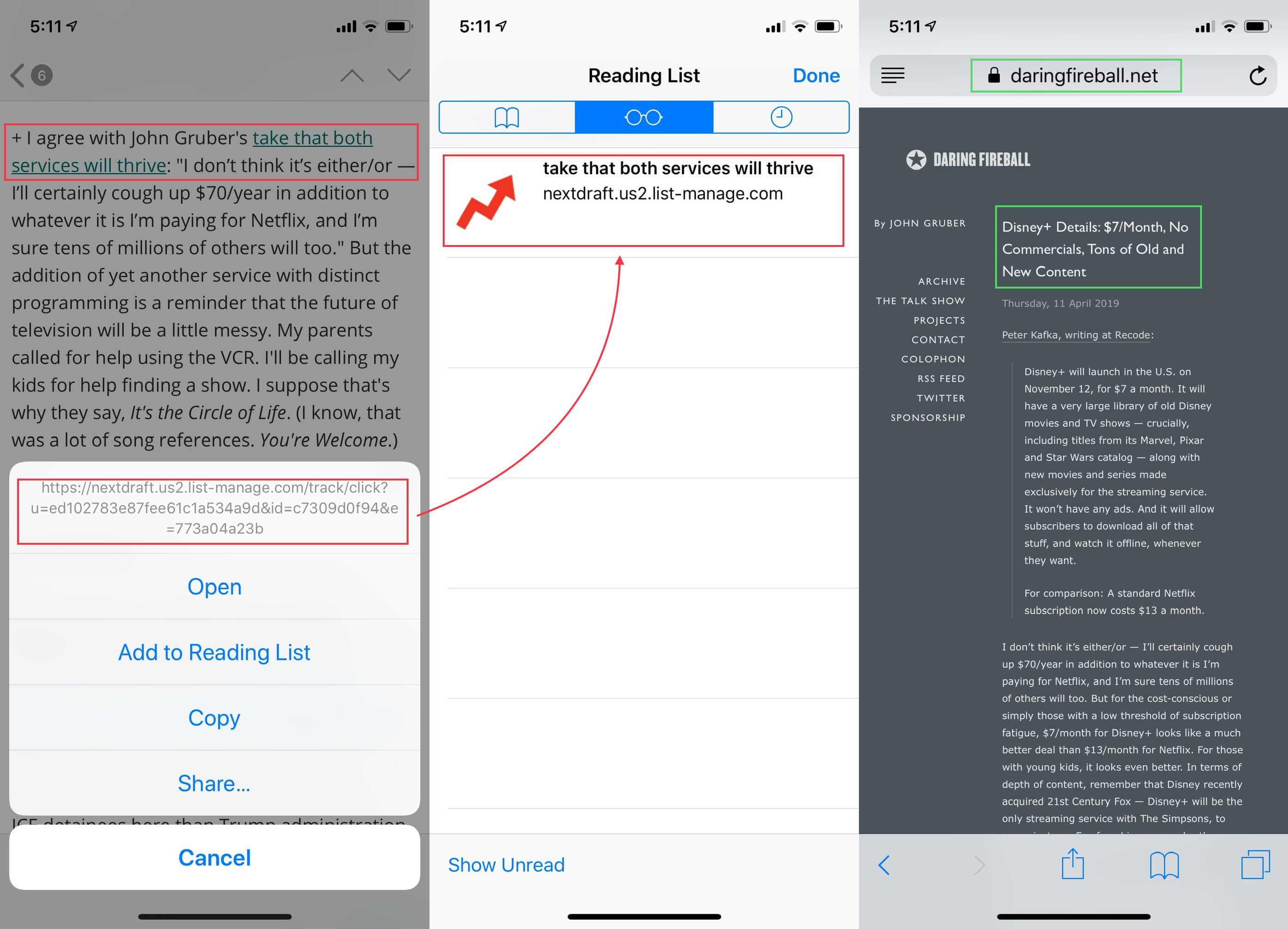
阅读列表不擅长处理需要跳转的特殊 URL
我的解决方法是引入 Mercury。Mercury 原本是一个在线 API,很多 RSS 工具曾经用它来抓取全文。但其提供方前不久宣布停止提供服务,转而将代码开源在 GitHub 上供人自行搭建使用。对于本文的目的而言,这倒不是坏事,因为在本地运行代码的效率反而更高。
Mercury 是基于 JavaScript 的,首先使用
npm -g install @postlight/mercury-parser
将其安装到系统中(依赖于 npm)。
然后,可以试着在终端执行 mercury-parser [网址] 来测试能否正常运行。
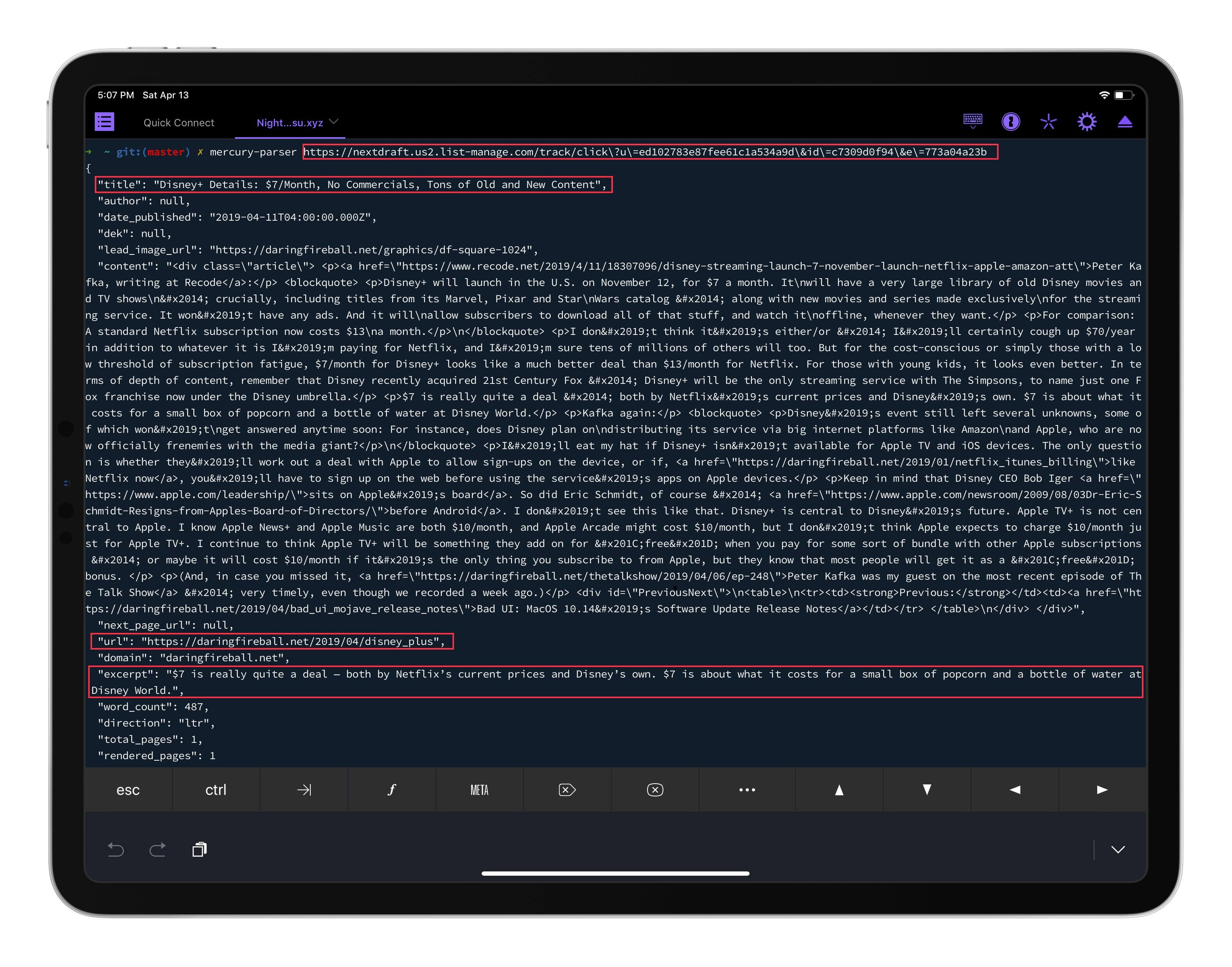
Mercury 正确获取了跳转 URL 指向的原始网页相关信息
Mercury 的解析结果以 JSON 格式输出,其中对本文有意义的是 url(原始链接)、title(网页标题) 和 excerpt(文章摘要)这三个键。为了在 Python 脚本中调用 Mercury 及其输出结果,需要对原始代码作一些修改:
from readinglistlib import ReadingListReader
import urllib
import subprocess # 用于运行 Mercury 终端命令
import json # 用于解析 Mercury 输出结果
auth_token = 'REPLACE_WITH_YOUR_API'; # 替换为你自己的 API Key
api_url = 'https://api.pinboard.in/v1/posts/add?'
rlr = ReadingListReader()
bookmarks = rlr.read()
for bookmark in bookmarks:
parser = json.loads(subprocess.check_output(["mercury-parser", bookmark['url']])) # 将脚本解析出的阅读列表链接提供给 Mercury 并获取其输出
params = urllib.urlencode({
'url': parser['url'].encode('utf-8'),
'description': parser['title'].encode('utf-8'),
'extended': parser['excerpt'].encode('utf-8'),
'toread': 'yes',
'auth_token': auth_token}) # 将 Mercury 的解析结果作为参数传输给 Pinboard 的 API
urllib.urlopen(api_url + params)
你可以在这里找到我修改好的脚本。
最后,将 Hazel 的匹配后动作改为执行该脚本,就可以获得比较即时和完善的同步结果。