Mac 的内置硬盘「作弊」了吗?
A version of this article appears on Mar. 11, 2022 on SSPAI as a member-only post. Learn more or subscribe
The article is permitted to be self-archived in the version as originally submitted for publication on the author’s personal website under CC BY-NC 4.0 pursuant to § 5.2(b) of the SSPAI Fellowship Contributor Agreement.
一
Mac 的固态硬盘性能一直是苹果宣传的重点。特别是近年 Apple T2、M1 等自研芯片整合了主控芯片后,Mac 内置固态硬盘相比竞品的性能优势似乎越发明显。在这样的背景下,如果有人站出来说「Mac 的固态硬盘速度有作弊之嫌」,想必会引起不少关注和争议。
Mac 一直致力于宣传内置 SSD 的高性能(来源:苹果)
上个月,这样的讨论确实发生了。
打开话匣的是 Hector Martin。先介绍一点背景:此君绝非哗众取宠的无名群众,而是一位资深的信息安全顾问和 Linux 研究者,曾因将 Linux 系统 移植到 PS4 上 而出名。去年以来,Martin 又将目光投向了 Asahi Linux,这是一个旨在让 ARM 架构 Mac 运行 Linux 系统的开源项目,目前进展颇多,已接近发布公测版。能主导这样一个高难度项目,Martin 关于 Mac 的观点自然会引起社区的重视。
在 2 月中旬的一串 推文 中,Martin 就提出了一项争议很大的主张:苹果的定制硬盘确实快得出奇,但却是以牺牲数据一致性(data integrity)为代价的。
这件事的背景是,Martin 在一台 M1 版 MacBook Air 上测试 Linux 系统时,发现很多写入操作慢的出奇,与类似操作在 macOS 下的速度完全不可同日而语。为了找出问题根源,他测试了苹果内置硬盘和其他两款常见固态硬盘的读写性能。
结果非常耐人寻味:
| 硬盘型号 | 仅写入 | 写入并冲刷缓冲 |
|---|---|---|
| 内置硬盘 | 40,000 IOPS | 46 IOPS |
| 西部数据 SN550 NVMe | 20,000 IOPS | 2,000 IOPS |
| 三星 860 EVO SATA | 5,000 IOPS | 143 IOPS |
换言之,在「仅写入」的测试中,苹果内置固态硬盘可以达到 4 万次的 IOPS(每秒读写次数),这是主流第三方 NVMe 固态硬盘的 2 倍、SATA 固态硬盘的 8 倍。
但到了「写入并冲刷缓冲」的场景,内置硬盘仅仅取得了 46 IOPS 的「好成绩」,相当于第三方 NVMe 固态硬盘的 2.3%、SATA 固态硬盘的 32.2%,还不如很多机械硬盘。
怎样理解 Martin 前后两次测试的区别和意义呢?
我们知道,现代计算机中最主要的性能瓶颈就是存储。因此,软硬件设计中普遍采用多级缓存的设计来改善性能。就写入数据这一场景而言,待写入的数据至少要经过系统缓存(OS cache)、磁盘缓冲区(disk buffer)这两道中间环节,才能最终进入永久存储(permanent storage)——机械硬盘的盘片或固态硬盘的闪存颗粒。
macOS 中的多级缓存(来源:WWDC 2019 演示文稿)
借用送快递来打比方,这就好比一个快件要经过区域分站、小区驿站等中转节点,才能最终送到你手上。
通常情况下,发件方(写入数据的应用程序)并不关心这些底层的区别;它们只是把快件(写入的数据)交给快递公司(操作系统),至于送达方式、成功与否全凭后者的反馈。而为了提高处理效率,操作系统的常见做法是只要快递送到了驿站(数据写进了缓冲区),就反馈说送达成功(写入完成)。至于最后一步「送货上门」(写入永久存储,中文讨论中也常称为「落盘」),则是由操作系统在之后再根据自己的节奏完成——但这已经不受应用程序控制了。
诚然,从日常使用角度而言,前一项数据是用户直接感知的「写入性能」,Mac 内置硬盘也确实有亮眼表现。但一旦发生断电等故障,那些还滞留在驿站的快件(缓冲区未落盘的数据)就有丢失的风险。
此外,快件从驿站派送上门的顺序,往往不同于到达驿站的顺序;派件员(硬盘主控)可能为了省时省事等目的将其重新排列组合。这在平时也无妨,但对于数据库日志、文件系统日志等特殊场合,常常要求关于一项操作的记录必须先于这项操作本身落盘(好比从银行存取现金,一定是先记账、再动钱)。这些预写日志(write-ahead log,WAL)会被打上称为「写入屏障」(write barrier)的标签,享受「优先派送」的待遇,它的落盘效率直接影响到后续操作何时能进行。
因此,如果说 Martin 测试的前一项数据代表了数据日常写入的效率,那么后一项数据则代表了数据落袋为安的效率,同样不能忽视。而正是在这项性能上,Mac 发生了翻车。
不仅如此,Martin 还宣称发现了 macOS 的一项「作弊」行为。
在测试落盘性能时,他最初使用了 POSIX 标准定义的 fsync() 系统调用。POSIX 是一套旨在促进操作系统相互兼容的接口标准,Linux 是在 POSIX 标准的指导下开发的(尽管并未完全遵循),而 macOS 更是通过了其 认证。因此按理说,两个系统执行 fsync() 的结果应该是一致的,也就是像标准所 规定 的那样,「强制对缓冲中的数据执行物理写入,并确保系统崩溃等错误后,截至调用前的所有数据均已录入磁盘」。
实际情况并非如此。Martin 发现,Linux 的确执行了 fsync() 所附加的冲刷缓冲动作,测出的写入效率也比不冲刷缓冲时相应降低。但如果在一台 MacBook Air 上用 fsync() 写入数据,五秒之后通过 PD 协议发去一条强制重启指令,这些理论上应该落盘的数据还是会丢失。他又换了一台 Mac mini,用 fsync() 写入数据五秒之后直接拔了插头,同样出现了丢数据的情况。
这种现象只有一种可能原因,那就是 macOS「无视」了 **fsync()** 所附加的落盘要求。
的确,如果你在 macOS 下查阅 fsync() 的手册页面(可以在终端执行 man fsync 查阅)中,就能看到这样一段说明:
注意,尽管
fsync()将所有数据从宿主冲刷到驱动器(即「永久存储设备」),该驱动器自身可能在相当长的时间内都并不会将数据在物理意义上写入盘片,并且可能不依先后顺序写入。具体而言,如果驱动器断电、操作系统崩溃,应用程序的数据可能只被部分写入,或完全没有写入。磁盘还可能重新排序数据,导致后来的写入还存在,而早先的写入则丢失。
这并不只是理论上的罕见场景,而是很容易在现实工作的负荷或驱动器断电故障中复现。
对于要求保证更高数据完整性的应用程序,Mac OS X 提供了F_FULLFSYNC这一fcntl命令。F_FULLFSYNC要求驱动器冲刷所有缓冲区数据,写入永久存储。
[ 节选翻译;粗体均为笔者所加 ]
换言之,在 macOS 下, fsync() 并不会冲刷缓冲区。要实现与 Linux 下相同的效果,应该使用另一个函数 fcntl(),并附加 F_FULLFSYNC 作为命令参数。
事实上,促使 Martin 开展这项测试的疑问——内置硬盘在 macOS 和 Linux 下性能差距巨大,其原因正在于此。如果对于同一项操作,Linux 因为 fsync() 的要求「送货上门」,而 macOS 却耍滑头地送到驿站就点了送达,那么两者的效率当然不能同日而语。
Martin 由此得出的观点是:如果一直「岁月静好」,Mac 内置硬盘确实速度令人望其项背。但一旦发生断电的意外事故,它就比第三方硬盘有更大风险遭遇数据丢失,对于没有电池作为后备供电的桌面型 Mac 就更是如此。
显然,Martin 的观点不可能不在社区引起热议。截至本文写作时,他的推文已经获得了近 1800 次转发,5900 多次点赞;在 Hacker News 和 Reddit 上的讨论帖也堆到了数百层高。这些讨论中,社区用户从不同角度对 Martin 提出了补充和质疑观点。
那么,Martin 说得有道理吗?与 Linux 相比,macOS 真的是一个不那么负责任的「快递公司」吗?这将是本文 下一部分 的主题。[ 待续 ]
二
前文 提到,Martin 关于 Mac 内置硬盘的测试在社区引起了热议。讨论过程中,最突出的争议焦点是 Martin 用「作弊」一词来形容 macOS。对此,不少观点认为这种说法并不准确。他们的主要理由有两点。
macOS 没有刻意误导
首先,苹果并没有刻意隐藏或误导 **fsync()** 在 macOS 下的不同行为。相反,苹果还通过文档和讲座,反复解释和说明这一区别,以及背后的设计逻辑。
例如,上文引述的 fsync() 手册页面就是一例。此外,在 XNU(macOS 的内核)的 源代码 中,也可以看到苹果的注释说明:F_FULLFSYNC 相当于执行 fsync() 并冲刷缓冲区(第 279 行)。
实际上,**fsync()** **在 macOS 和 Linux 上的差异并不是一直存在的。**正如推特用户 Dominic Evans 指出,早期版本的 Linux 内核和 OS X(macOS 的曾用名)一样,也不会在执行 fsync() 时冲刷缓冲区。只是到了 2.6 版的若干小版本更新中,Linux 才修改了 fsync() 的行为,使其具有了冲刷缓冲的额外效果。
从 Linux 版 fsync() 的手册页面 修订历史 也可以看出这一点。早期版本的手册还表示「如果硬盘启用了写入缓冲,数据可能并未实际写入永久存储」;晚近版本中,这样的表述已经被「fsync() 包括冲刷既存缓冲」取代了。
这个问题也远非被第一次提出。 早在 2005 年,资深苹果工程师 Dominic Giampaolo 就在一次邮件列表回复中 解释 过这个问题。当时,MySQL 数据库在一次更新日志中称,其在 Mac 平台上用 fcntl() 代替了 fsync(),因为苹果在内置硬盘上「禁用」了 fsync() [ 的冲刷缓冲功能 ]。
Giampaolo 反驳了这一表述,指出 fsync() 在 OS X 和其他 Unix 家族的系统上从来就没有保证过落盘。正是因为考虑到有此需求,苹果才专门增加了 F_FULLFSYNC() 参数用来提供这一选项。由于这将是一项影响性能的「重度」操作,只应该在数据库之类需要确保数据一致性的场景下使用;而对于大多数日常操作,fsync() 就足够了。
此后,苹果还在多个官方渠道传递过类似信息,包括官网一篇题为 《减少磁盘写入》 的开发者文档,以及 2019 年的 WWDC 上一场「在你的应用中优化存储」(Optimizing Storage in Your App)讲座等。

苹果工程师在 WWDC 2019 讲座上对 fync() 的介绍(来源:WWDC 2019 演示文稿)
换言之,至少在苹果看来,他们的设计并没有忽略落盘这一需求,相反是给开发者提供了更加灵活的选择,即根据不同应用场景在性能和数据安全之间做出不同权衡。
第三方硬盘可能没说实话
其次,所谓「一个巴掌拍不响」,数据写入是一项需要软硬件相互配合的操作。操作系统如何指令是一回事,硬盘的主控及其固件如何响应这些指令则是另一回事。
如果操作系统在执行 fsync() (或 macOS 上的 F_FULLFSYNC)下达了确保数据落盘的指令,如果硬盘「执行不力」,一俟数据写入缓冲区,就敷衍反馈任务完成了,操作系统其实也无从核实。
**这并非只是理论上可能出现的情况。**好巧不巧,就在 Martin 引起的讨论余波未尽时,苹果工程师 Russ Bishop 在推特上表示,自己 测试了 一系列不同品牌的固态硬盘,发现它们对于断电事故的防护能力各不相同。
其中,三星、西部数据、英特尔、希捷、英睿达(Crucial)的受测型号经受住了考验,而海力士(SK Hynix)和 Sabrent 的两种型号则在断电后发生了丢数据的情况。
值得注意的是,Bishop 正是通过 macOS 的 **F_FULLFSYNC** 功能来写入测试数据的。如上文所述,这个指令会要求硬盘冲刷缓冲区。如果在执行过后仍然发生丢数据的情况,「责任」只可能在于硬盘身上——它没有遵照操作系统的命令以及 NVMe 的 技术规范(PDF),将数据提交至非易失媒介(non-volatile media),也就是存储颗粒上(§7.1, revision 2.0b)。
Bishop 显然不是第一个发现这个问题的人。2011 年,威斯康星大学麦迪逊分校的几名研究者就在提交给 IEEE 国际会议的一篇 论文 中详细讨论过这种现象,称之为将性能放在稳定性之上的营销逐利行为。
推特上,参与过往年 macOS 开发的 Rosyna Keller、Andrew Wooster 等人也结合实际经历 指出,忽略冲刷缓冲区的要求、对操作系统撒谎是第三方硬盘曝片存在的现象,曾给苹果团队开发 Time Machine 备份等功能造成过很大的困扰;反倒是 Mac 的内置硬盘始终保持「诚实」。
而苹果之所以没有「从善如流」,学习 Linux 修改 fsync() 的行为,除了是因为已经有了等效的 F_FULLFSYNC 选项,另一个考虑也是和已经染上不靠谱名声的 fsync() 区分开,给开发者更清晰的选择。
讨论至此,我们似乎还忽略了另外一个重要阵营——Windows 系统下的情况。我们将在本文的 最后一部分 来看看这块「他山之石」。[ 待续 ]
三
前文中,我们介绍了社区对 Martin 所做测试和主张的不同意见。本文中,我们将暂时跳出 Unix 一脉系统,看看另一个阵营的 Windows 系统是如何处理硬盘缓冲的。最后,我们将讨论对于普通用户来说,可以从此事及其相关讨论中得到的启示。
前文 中,我们介绍了社区对 Martin 所做测试和主张的不同意见。下面,我们将暂时跳出 Unix 一脉系统,看看另一个阵营的 Windows 系统是如何处理硬盘缓冲的。
他山之石——Windows 下的硬盘缓冲
Windows 没有 Unix 基因,不存在怎样实现 fsync() 的问题,但仍然免不了考虑「把数据扔给硬盘」和「盯着硬盘完成写入」的区分。
对此,Win32 API 分别提供了 WriteFile 和 FlushFileBuffers 这两个函数;使用后者写入文件,其效果就类似于在 Linux 上执行 fsync() 或在 macOS 上执行 F_FULLFSYNC——在写入文件的同时刷新缓冲区、并将所有缓冲数据落盘。
此外,Windows 还在用户界面上提供了与硬盘缓冲相关的选项。在开始菜单的搜索框输入 devmgmt.msc 并回车(或者在「开始」按钮上点击右键),打开「设备管理器」;然后,在硬盘名称上点击右键,选择「属性」,切换到「策略」选项卡。
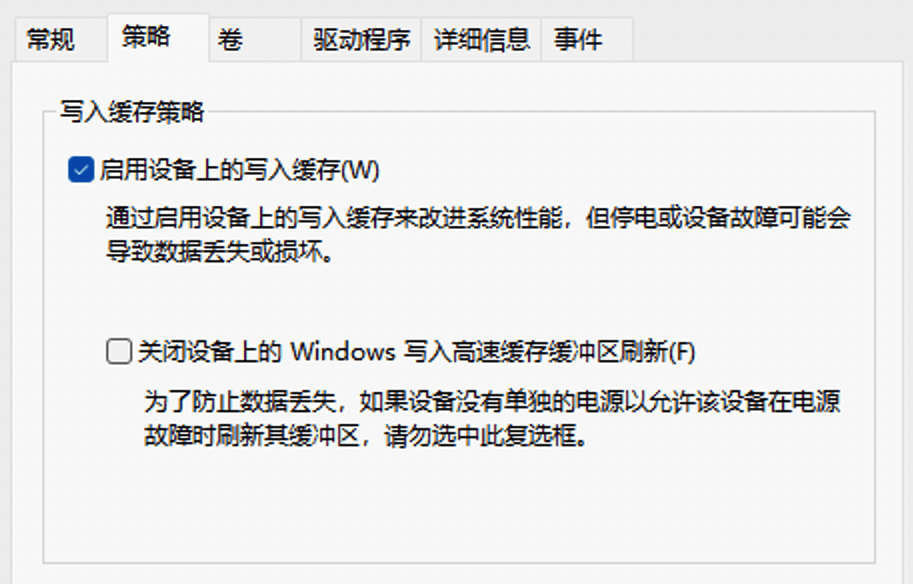
这里,「写入缓存策略」部分的两个复选框就是用来控制缓冲区开关和行为的。其中,「启用设备上的写入缓存」是一个整体开关,只有将其勾选,Windows 才会在这块硬盘上使用缓冲区;否则,Windows 会试图让每次写入都直接落盘(Windows 10 1809 版起,这 成为了 U 盘等外置存储的默认行为)。
但正如微软自己在这个选项旁边提示的,「停电或设备故障可能会导致数据丢失或损坏」。为了降低这一风险,Windows 提供了一项预防机制,即此处第二个选项中提到的「写入高速缓存缓冲区刷新」。这是指 Windows 会不时要求硬盘冲刷缓冲区,类似于在 Linux 上隔一段时间就调用一次 fsync()。
缓冲区刷新是默认开启的,但可以通过手动勾选复选框来关闭。从界面描述看,微软显然并不希望你这么做:「为了防止数据丢失,如果设备没有单独的电源以允许该设备在电源故障时刷新其缓冲区,请勿选中此复选框」(实际上,这句提示随着 Windows 的演进还在 变得越来越严厉)。
然而,如果你在网上搜索这两个选项,能看到大量说法相左的「经验」「技巧」,内容大致都是惊叹自己在勾选(或不勾选)后观察到了翻天覆地的性能提升,给出的理由也是五花八门。
不仅如此,这个选项可能根本没有什么实际意义。微软首席工程师 Raymond Chen 曾在 2007 年的 TechNet 杂志上 撰文 回忆到,Windows 3.11 版本曾经存在一个 bug,导致系统经常忽视应用程序提出的冲刷缓冲区的请求。这被当时的一些开发商误解为真实的性能优化,本着「不用白不用」的心态,在软件中到处滥用冲刷指令,连鼠标和键盘操作后都要「冲刷」一下。
随着 Windows 95 修复了这个漏洞,冲刷指令的性能影响重新体现出来,那些第三方软件的体验则受到了毁灭性打击。在大量投诉下,微软出于妥协才加入了这个旨在让修好的 bug「复活」的选项。(还有说法 称,这些厂商在不满之下反咬一口,状告微软是出于「垄断」目的才做的这一修改。)
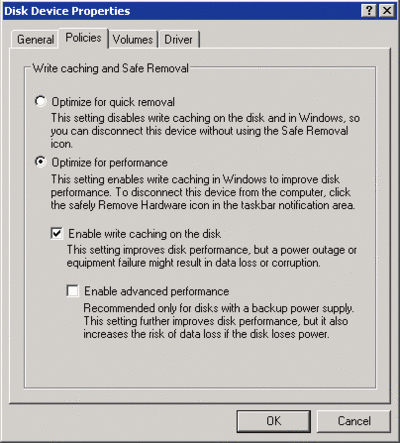
Windows 2003 中的磁盘属性设置,「禁用缓冲区刷新」被美其名曰「启用高性能模式」,其实是指「启用 bug 模式」(来源:微软 MSDN)
这固然是一个戏剧化的轶闻,但也在一定程度上表明了 Windows 的特征:由于平台高度异质化、历史包袱颇多,很多功能开关最多只能起到「尽力而为」的作用。具体到「缓冲区刷新」这个选项,由于厂商完全可能通过固件和驱动对这些选项做出不同响应,其具体效果必然高度依赖于硬盘的颗粒、主控,使用的驱动程序及其版本。
因此,对于用户而言,如果没有特别的理由,最理性的选择就是保持默认设置不动,以及遵循厂商的建议(例如,英特尔 和 三星 都建议对于消费级产品开启写入缓存)。
结论
总结起来,抛开「作弊」这种过于主观、容易引战的表述,对现状比较公允的表述可能是:
- 因为一些历史而非刻意的原因,macOS 采用了与 Linux 不同的方式提供数据写入接口,但后果优劣则因人而异,跨平台开发者比原生应用开发者更容易因此产生困惑。
- 就冲刷缓冲这项操作而言,Mac 内置硬盘的缺点是效率不及主流第三方产品(且原因暂时不明);但优点是得益于与 macOS 的垂直整合,只要程序提出要求就可以确保数据落盘,不用担心像一些第三方硬盘那样另有算盘。
诚然,这些技术上的细节更多应交给厂商和开发者来关心。但对于普通用户来说,也可以从此事及其相关讨论中得到不少有价值的启示。
首先,任何跑分测试的结果都是相对的。
现代的存储设备和相关的存储机制早已被高度抽象化了;软件层面的概念和硬件层面的部件很少是一一对应的。尽管上文反复提及「系统缓存」「硬盘缓冲」等概念,但它们并没有表面上那样泾渭分明。
一方面,如果启用了虚拟内存,系统缓存的职能可能分配给硬盘来执行;另一方面,随着无板载 DRAM 的流行,很多固态硬盘又会反过来征用主内存作为缓冲区(典型例子包括 NVMe 标准中的 HMB、英睿达 Executive 驱动 的 Momentum Cache、三星 Magician 驱动 的 RAPID Mode 等)。即使到了硬盘内部,普遍存在的「SLC 缓存」(在廉价的 TLC 或 QLC 硬盘中,将多个颗粒「合并」模拟成高速的 SLC 颗粒)也会进一步构造出性能台阶。
三星 Magician 驱动程序提供的 RAPID 功能(来源:三星)
如果在测试中未能控制这些变量中的任何一个,都会产生有偏差的结果。换个角度说,任何测试结果也只有结合特定测试条件、具体使用场景理解才有意义。
其次,不存在什么绝对的标准和原则。
在本次事件的讨论中,可以观察到一个问题反复出现:POSIX 标准对 fsync() 的定义,以及 NVMe 标准对冲刷指令的定义,究竟是过程导向(把数据传给硬盘)的还是结果导向(保证数据落盘)的?对这个问题的不同回答会导致对各家设计的不同评价。
但实际上,这两份标准本身也给留出了很多例外情况和裁量空间。POSIX 标准指出,如果使用环境不要求同步写入(即不需要在写入数据的同时保证落盘),那么系统对 fsync() 的效果可以高度自主,哪怕「啥都不干」(a null implementation)也是可以的;NVMe 标准也提到,如果主控能保证即使断电不会丢数据(例如自带了电池、电容等防断电机制的硬盘),那么只是进入 DRAM 的数据也可以视为「非易失」的。
换言之,场景比教条更重要。存储相关软硬件设计的评判标准不仅是看哪个更遵守标准,更主要是看哪个在性能和稳定性找到了更好的平衡。
最后,计算机部件的集成化是一把双刃剑。
放在十几年前,很难想象硬盘这种「笨」设备可以搭载一块性能堪比早期主机的主控芯片,无需主机介入就能独立承担缓存控制、垃圾收集等职能。但高度的集成化也会导致高度的不透明,操作系统越发对硬件的行为失去控制,用户也越发难以在出现问题时自主排查和修复。
但越是如此,那些老生常谈的经验就越是适用:做好数据备份;台式机应考虑添置后备电源;驱动安装和配置调节以官方口径为准,不要不明原理而听信一些「江湖偏方」。[ 全文完 ]