康熙来了
[ Note: The post was originally written for the launch edition of Pi Weekly, a column of SSPAI’s member subscription that summarizes premium posts published during the current week, led by an explainer or commentary of recent tech news. If you’re interested by the post, please consider purchasing a subscription. Thanks for your support. ]
有时,技术问题与现实议题可能会以奇特的方式结合在一起。本周,这种情况就生动地发生了。
简而言之,在一个涉及明星争议新闻的微博话题中,汉字「入」被发布者换成了一个看起来一模一样、但输入法打不出来的近似字符。经过搜索,人们发现偷梁换柱的字符是 ⼊,一个专门用来表示这个汉字偏旁的独立符号(一些评论讹为异体字和日文字,这是不正确的)。
显然,这样的改动不太可能是手滑打错字导致,从而进一步激发了关于其动机——例如是不是有意「隔离」批评意见——的猜测。
围绕此事本身的争议并非今天的讨论范围。这里,我们只从技术角度出发,考察两个读者可能感兴趣的问题:
第一,汉字「入」和部首 ⼊ 是什么关系?为什么在电脑上是两个不同的字符?
第二,涉事的两个微博话题为什么在一些截图中难辨真伪,而在另一些截图中则能看出破绽?
先看第一个问题。如今,计算机文字最通用的标准是 Unicode(统一码)。这种编码方式使用十六进制数的组合来给字符编号,每个字符都占据唯一的「码位」(code point)。
码位的编排是有规划的。具有共同来源、用途等特征的字符会被分组编排在一起,进而构成一个个「区块」(block)——正如行伍编队。例如,最开头的 0000 到 007F 共 128 个码位构成了「基本拉丁字母」(Basic Latin)区块,包括最常用的大小写字母、英文标点,以及换行、回车等「控制字符」;紧随其后的「拉丁-1 补充」(Latin-1 Supplement)区块,则含有带声调字母和更多特殊符号。
而这次事件的主角之一、汉字「入」的码位是 5165,位于「中日韩统一表意文字」(CJK Unified Ideographs)区块。这个区块的地盘从 4E00 绵延到 9FFF,合计两万多个码位,旨在收录来自汉字文化圈各地的多种「方块字」。
而那个充当「李鬼」的部首 ⼊,则是排在隔得老远的 2F0A,属于「康熙部首」区块(2F00 — 2FDF)。不难猜到,这个区块定向收录了清朝《康熙字典》中的 214 个汉字部首;⼊ 是其中的第十一个。
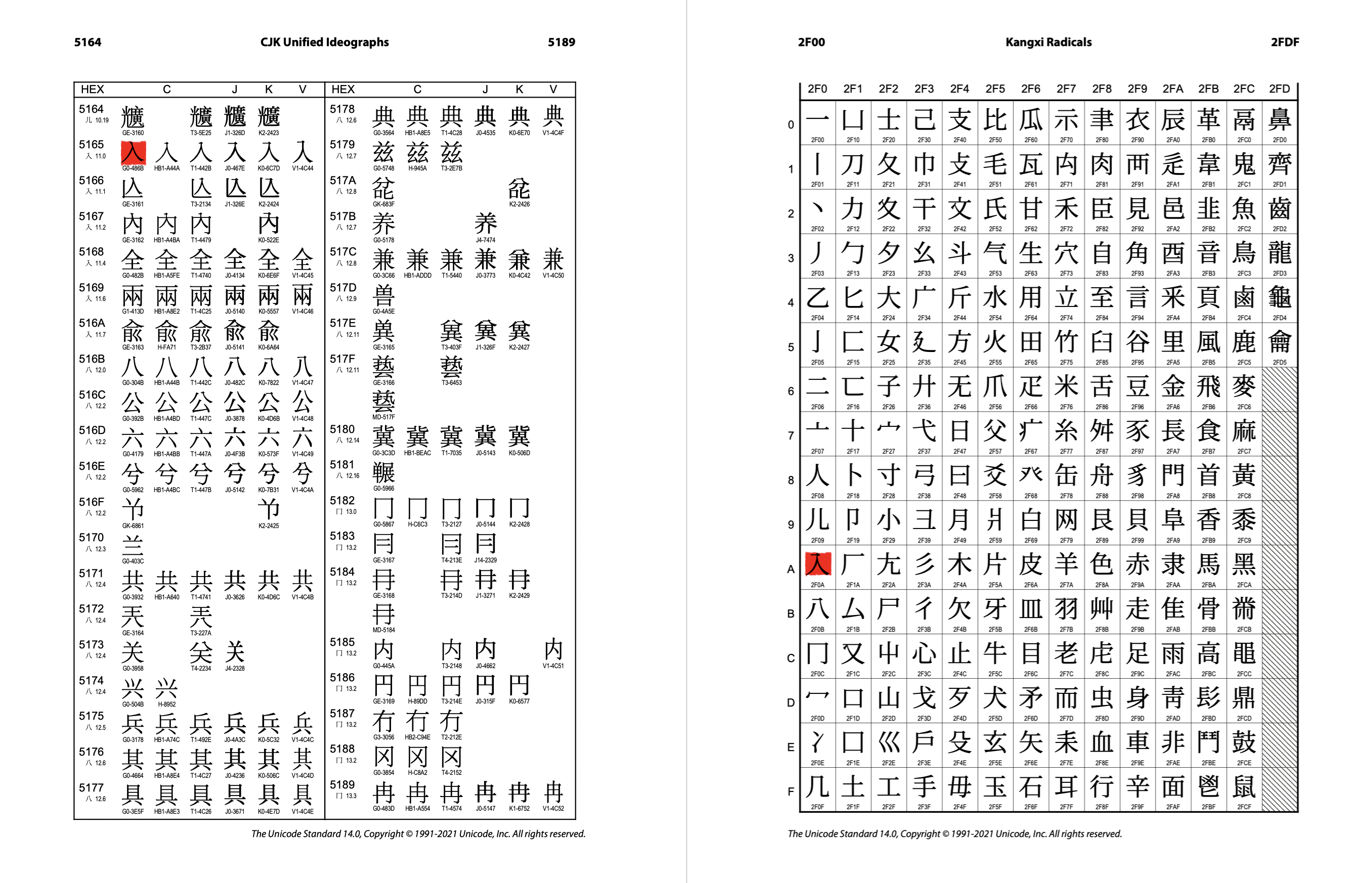
值得一提,《康熙字典》也是 Unicode 排序汉字的最主要依据。在表意文字区块中,一个字的位置通常取决于两个因素:所属康熙部首的顺序,以及部首以外笔画的数量。这样,「一」字当之无愧地排在第一位,随后是比它多一画的「丁」「丂」「七」;类似地,汉字「入」的后面则跟着「兦」(wáng,逃避)、「內」、「全」。
由此可见,在表意文字部分,每个康熙部首其实已经收录过一遍——用来引领包含那个部首的其它汉字。既然如此,为什么还要专门设一个区块再重复收录一次呢?硬盘容量不值钱吗?
康熙部首是在 1997 年被提议收入 Unicode 的。在讨论收录康熙部首的提案时,与会者提到的目的主要有二:其一,既有的繁体中文编码标准(CNS 11643,中文标准交换码)已经用一串连续的码位收录了康熙字典部首。如果 Unicode 也专设一个连续区域,就很方便与之相互转换。其二,部首具有区别于相同形态汉字的专门使用场景,最典型的就是在词典和输入法中作为检字索引,因此有独立收录的价值。(WG2 N1503,第 25 页。)
的确,收入 Unicode 后,康熙部首区块中的字符都被定义为「兼容字符」(compatibility characters),表示收录目的仅仅是维护与其他编码系统的兼容性,方便转换。除了康熙部首,常见的兼容字符还包括上标数字(如 ²)、连字(如 fi)、罗马数字(如 Ⅷ)等。现代排版环境下,这些字符都可以通过更常见的字符间接调整组合而成,理论上不需要单独收录,但为了衔接以往标准还是单列出来。
正如当年的会议记录所表明,收录康熙部首是否必要,可能有不同观点。但无论如何,最终的结论是康熙部首被接纳为独立字符;而 25 年后,它以一种意外的方式成为了社会新闻的主角。
至于第二个问题——为什么这个字在一些系统中更容易「露馅」,则涉及字体的显示原理。
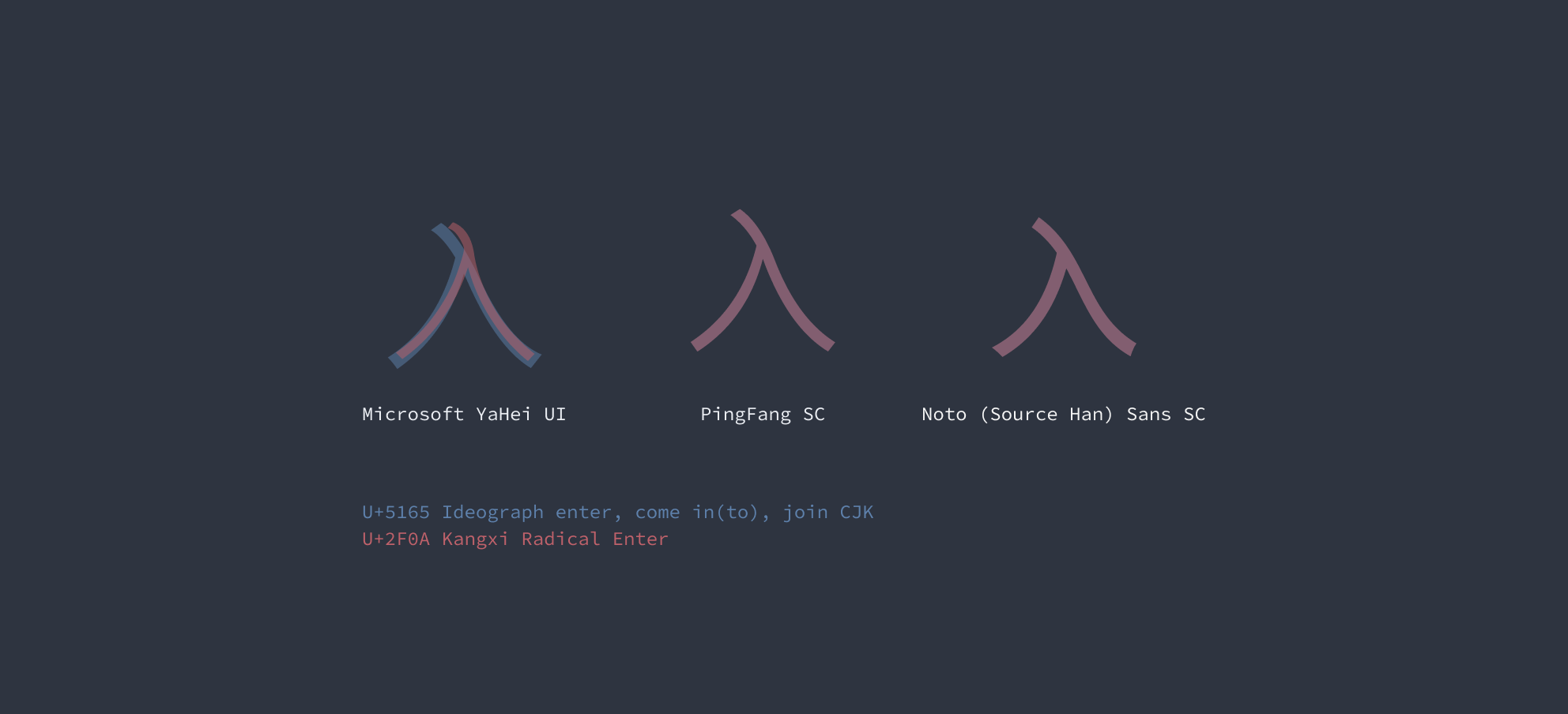
「在屏幕上显示出文字」是一个多方协力的复杂流程,编码只是其中一个步骤。粗略地说,当操作系统系统得知要显示的字符编码后,会拿着这个编码去字体文件中检索,根据字体文件中记录的设计造型,依样在屏幕上绘制出来。因此,汉字「入」和部首 ⼊ 长得一不一样,取决于所用的字体是否将它们设计成「双胞胎」。
在 iOS 和 macOS 的默认中文字体苹方中,两者的形态完全相同。因此,在 iPhone 和 Mac 用户看来,两个版本的微博话题就没什么区别。相反,在 Windows 的默认中文字体微软雅黑中,两者的设计有明显差别。因此,如果你用 Windows 电脑刷网页版微博,眼神又不错,就会察觉到一些不对劲。
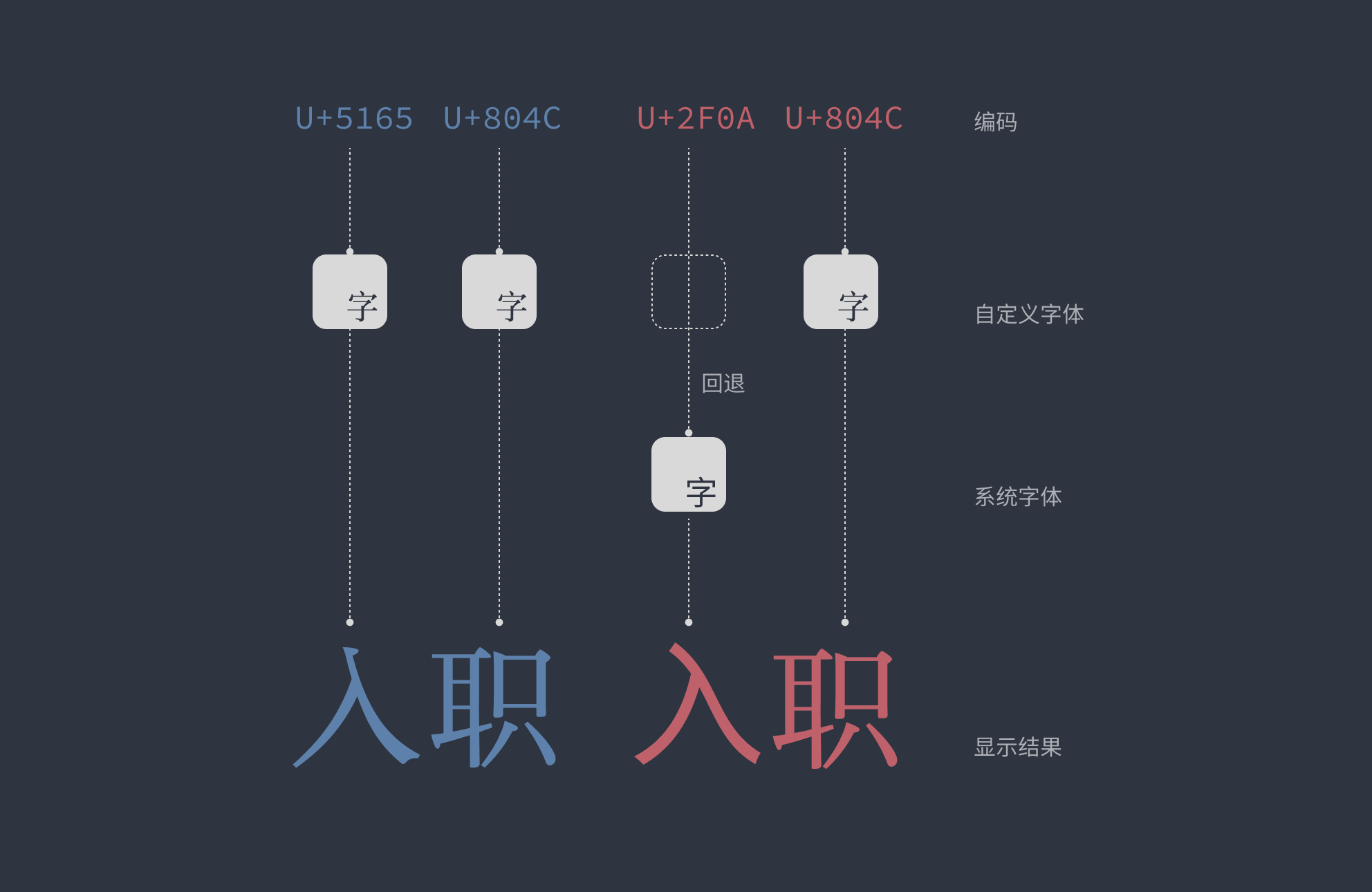
还有的时候,字体文件中根本就没有收录要显示的字符。例如,如今国产 Android 系统大多允许自定义字体,而很多人往往喜欢换上一些风格「文艺」的装饰字体。可这些字体根本不是为了界面显示的目的设计的,出于成本和实用导向的考量,收录字数往往非常有限,只包含常用汉字,⼊ 这样的偏门字符肯定是略过的。
这时,系统就会遵循一种称为「回退」(fallback)的机制,通俗地说就是「找备胎」:按照一定的候补名单依次检索其他字体,直到找到一个能接盘的字体为止。在现代的 Android 系统上,这一般意味着调用 Noto Sans CJK(思源黑体)。思源黑体是一款设计规规矩矩的界面字体,自然会与周围「个性」的邻居产生巨大反差。这就解释了为什么在很多 Android 用户发出的截图中,那个「李鬼」版本显得格外突兀。
对于不少人来说,本次事件可能是他们第一次接触到 Unicode 的「博大精深」:具有相近形态的字符可以被用来充当「障眼法」的道具。实际上,在计算机安全领域,Unicode 的复杂性一直都是别有用心者利用的对象。
一种屡试不爽的伎俩是「视觉欺骗」(visual spoofing)。这是指使用近似字符诱导用户采取不安全的操作,例如访问一个误以为权威的网址、采信一封看似来自官方地址的邮件等。Unicode 还专门有一篇报告讨论这样的安全隐患。
其中,一些最原始和「幼稚」的视觉欺骗——例如用数字 1 充当字母 l,数字 0 充当字母 o——已经广为认知,不太奏效了;但一些更隐蔽的替换则还是屡试不爽的欺诈「窍门」。仅凭肉眼,很多人并不能分辨出 аpple.com 这个网址中的字母 а 其实是基里尔文的版本,这个网址也就不是苹果官方所有。类似的把戏还包括 c(英文字母)和 ⅽ(罗马数字一百)、K(英文字母)和 K(温度单位开尔文)等。
此外,很多软件环境会自动处理 Unicode 中的生僻字形,将其替换为更常用的等效字形 (这一过程称为「正规化」,normalization)。这个特性也会反过来被人利用。
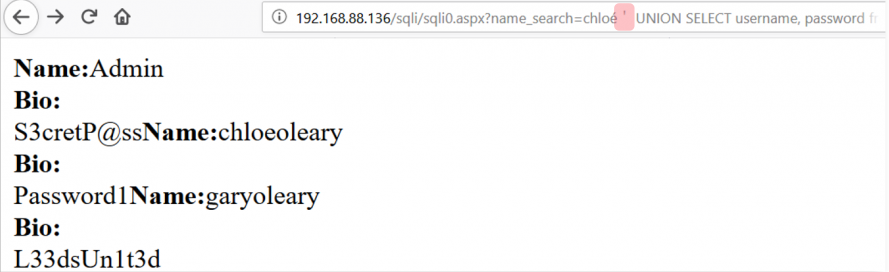
例如,很多系统出于安全考虑,会禁止用户输入一些具有执行代码功能的敏感字符,典型例子包括 '(撇号,可以注入 SQL 数据库)、<(尖括号,可以注入网页代码)等。但是,这些安全机制却不会过滤敏感字符的近似形态。
因此,只要先用更生僻的近似字形「瞒天过海」,然后静待它在后续的正规化处理中,被还原为具有高危后果的字符,就能达到注入恶意代码的效果。下图中,红色部分的全角撇号躲过了筛查,随后被正规化为普通撇号,触发 SQL 查询,导致数据泄露。
令人感慨的是,利用 Unicode 近似字形实施的欺骗,某种意义上正是技术进步的体现:越是在文字编码通用、字库齐全的环境下,这种做法就越是真假难辨、容易得手。在计算机安全领域有一种说法:人是各种系统中最脆弱的因素。现在看来,这并不只是一句技术意义上的格言。