找个替身,干净卫生——替身前端的选择与使用
A version of this article appears on Nov. 21, 2022 on SSPAI as a member-only post. Learn more or subscribe
The article is permitted to be self-archived in the version as originally submitted for publication on the author’s personal website under CC BY-NC 4.0 pursuant to § 5.2(b) of the SSPAI Fellowship Contributor Agreement.
什么是替身前端
如果你还记得 Google、Twitter 和 Reddit 这些大型平台早年的模样,相信不会否认它们这些年都在变得越来越难用:为了商业变现,页面上的有效信息越发被广告所侵蚀;为了用户黏性,时间流日渐让位于算法推荐的洪流。作为「免费」的代价,平台也大肆收集用户的隐私信息,很多时候远超提供服务所必要的范围。
但有压迫就有反抗。一些不愿逆来顺受的用户选择拍案而起,用技术对抗技术。于是,一类称作「替身前端」(alternative frontend)的开源项目涌现出来,并且队伍有逐渐壮大之势。
什么是替身前端?最好的办法是通过例子来说明。
比如,这是一个普通的推文链接:https://twitter.com/elonmusk/status/1585341984679469056,访问以后可以打开一个普通的推特页面,上面普通地充斥着各种广告和推荐信息。
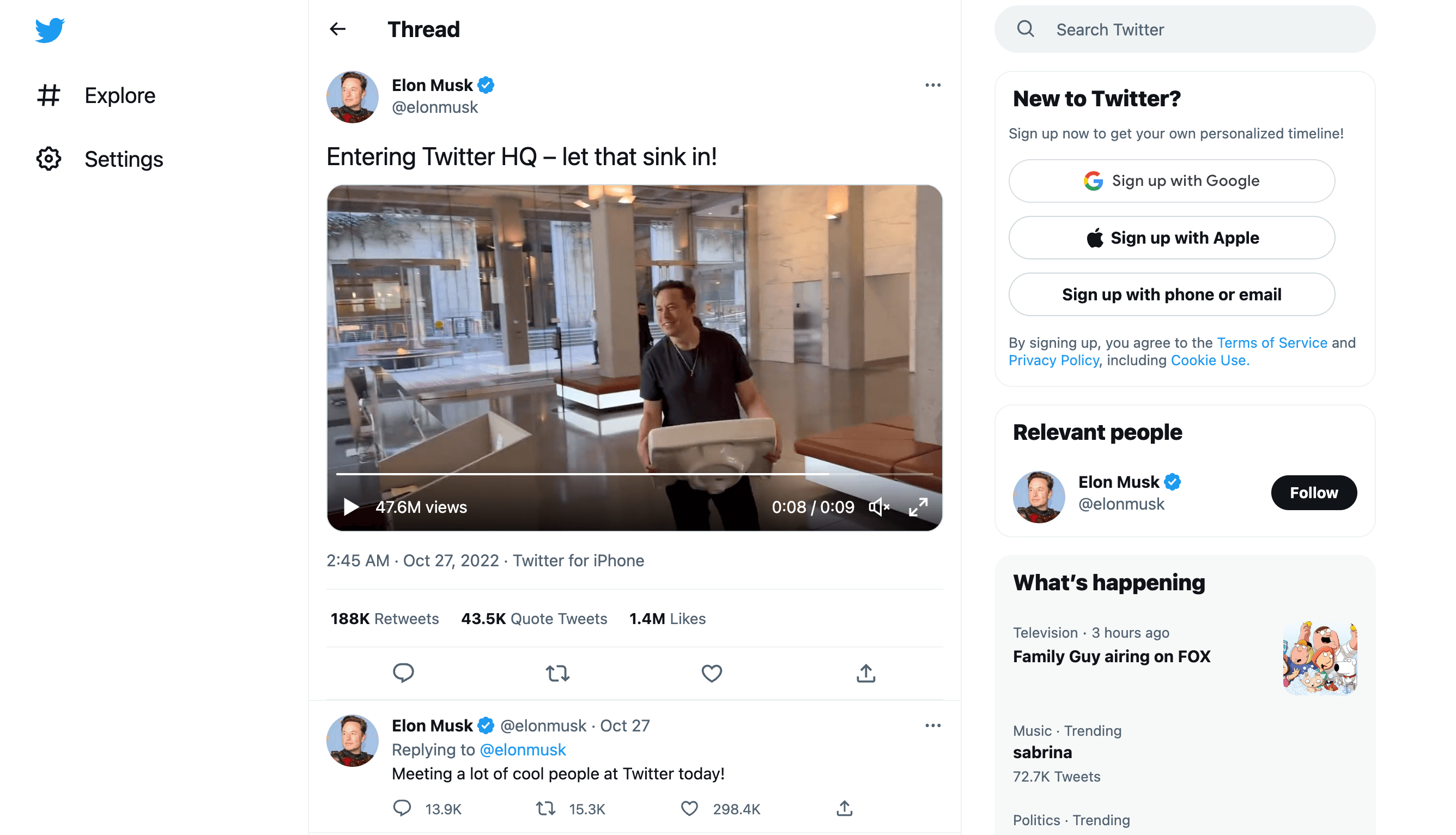
现在,请将域名部分的 twitter.com 换成 nitter.net,其他保持不变:
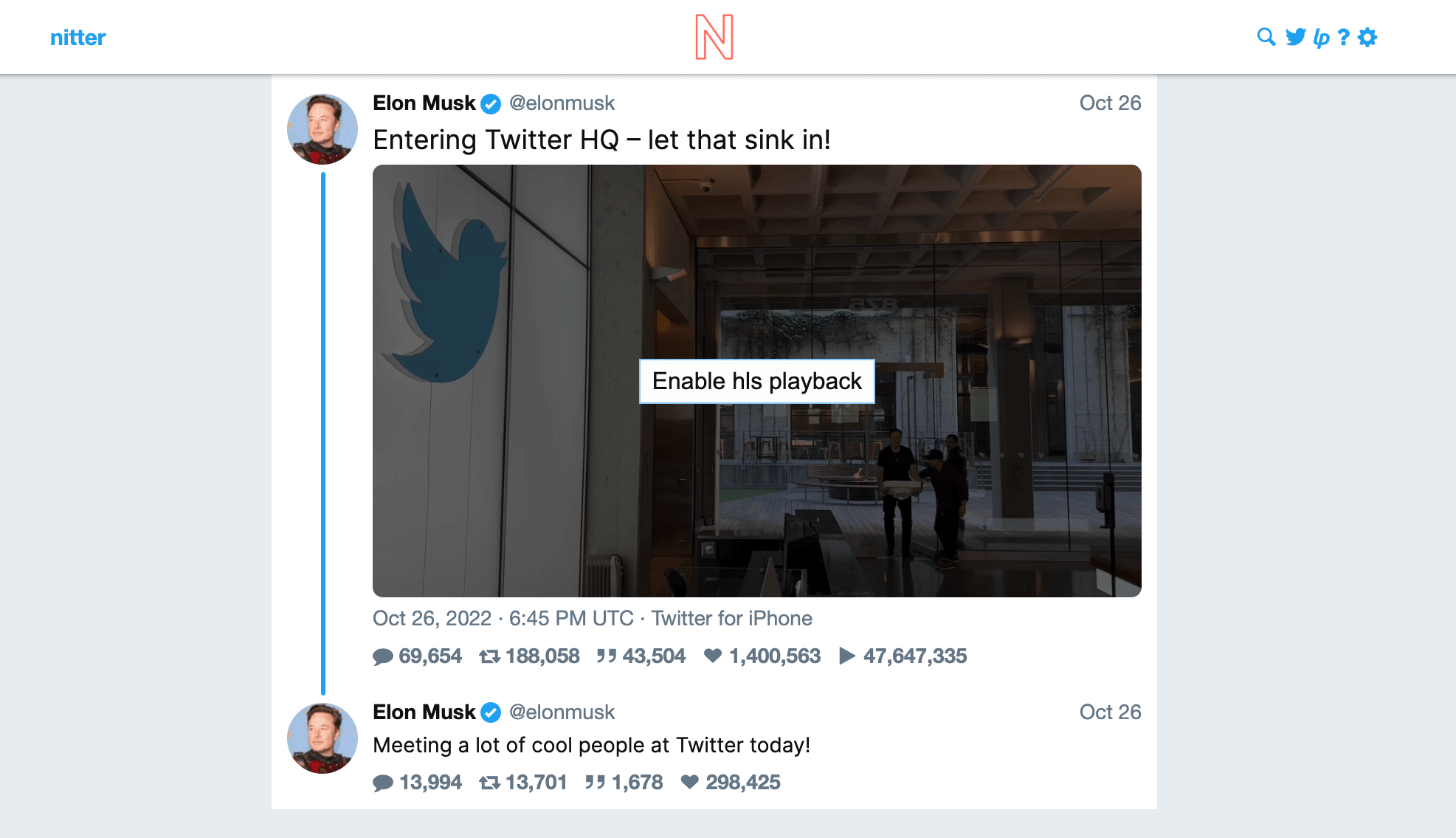
是不是有一种梦回 2009 的感觉?这里,nitter.net 是开源项目 Nitter 的官方实例服务器,而 Nitter 就是 Twitter 的一个替身前端。
再比如,这是一个普通的 YouTube 视频链接:https://www.youtube.com/watch?v=v_5KcoSwmg4,访问以后可以打开一个普通的 YouTube 页面,上面仍然普通地充斥着各种广告和推荐信息。
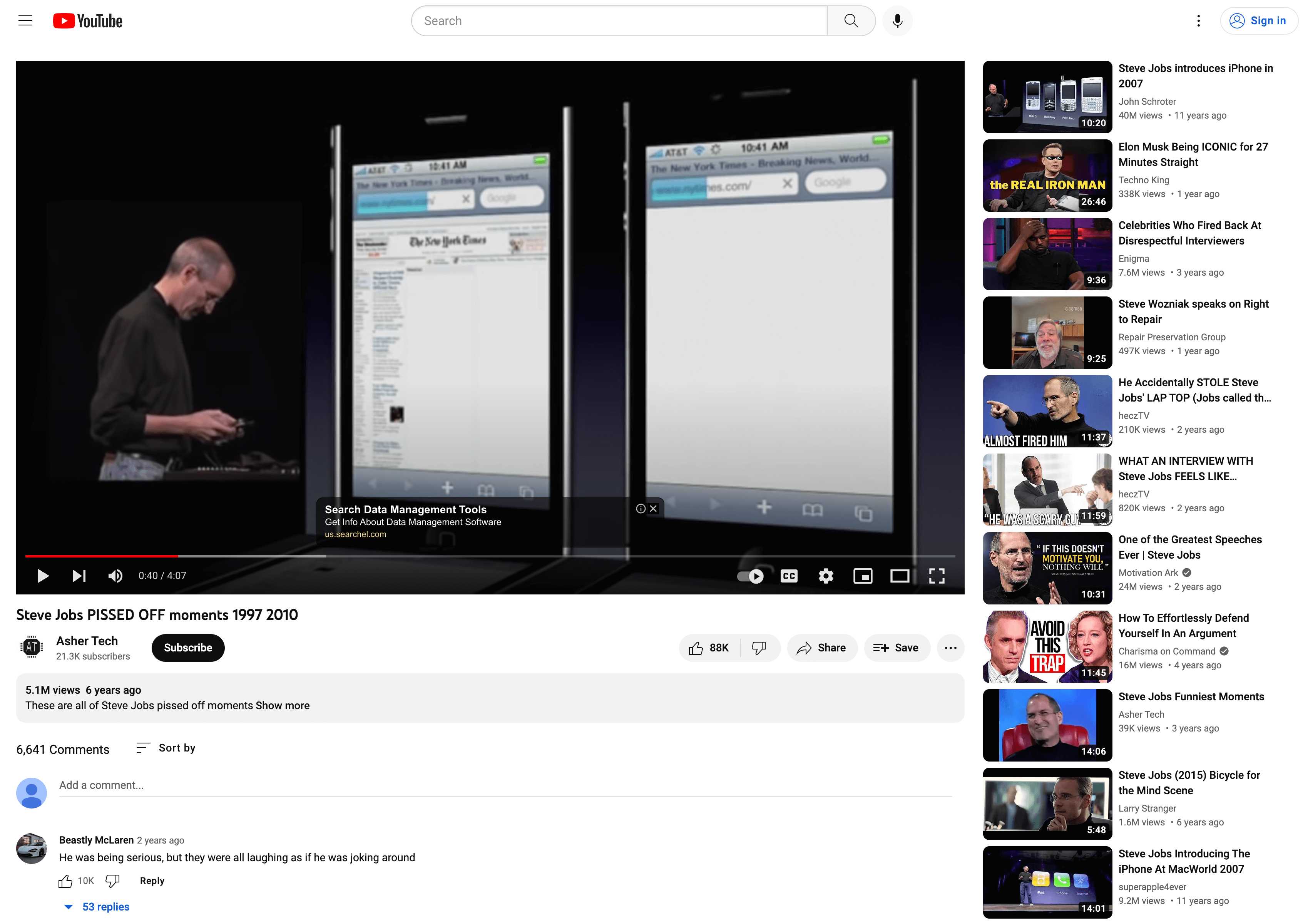
如果将域名部分的 www.youtube.com 换成 piped.video 再打开,你仍然可以看到这个《乔布斯翻车场面合集》视频,但是没有任何之前的干扰元素。
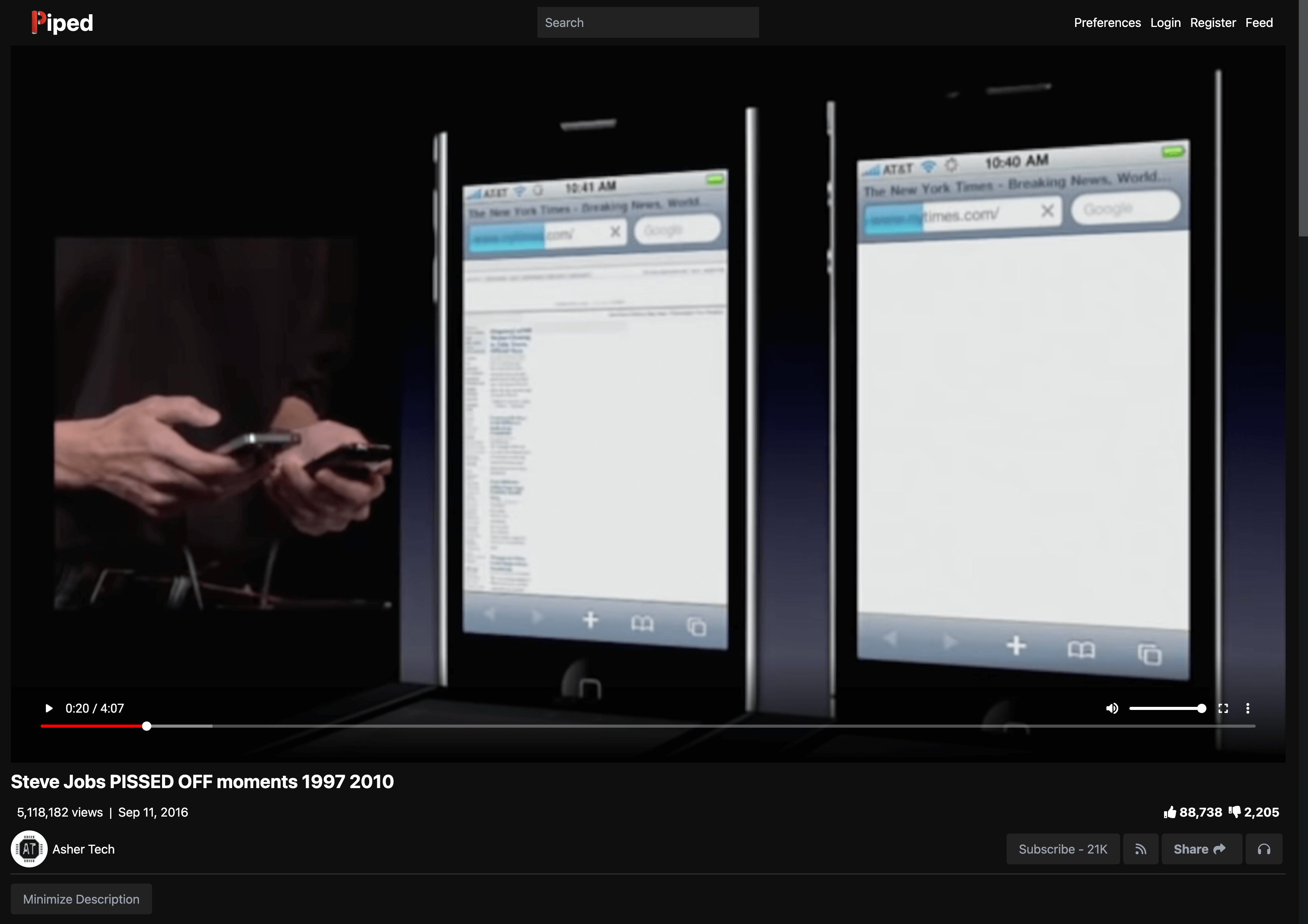
这里,piped.video 是开源项目 Piped 的官方实例服务器,而 Piped 就是 YouTube 的一个替身前端。
相信你大致已经有了一些直观印象。
总结一下,本文所谓「替身前端」,就是使用直接或间接的技术方法代替用户访问目标服务,有选择地将目标服务的功能和内容以不同形式重新呈现,以实现精简内容、强化功能、提高效率或保护隐私等目标的,可以自行托管的开源软件。
下面,我们具体介绍这个定义中几个要点,以便更好地理解替身前端的原理和功能。
实现原理
不同替身前端的工作原理各异,但本质上都可以看作是基于网页的用户代理(Web-based User Agent)和网页抓取工具(web crawler)不同程度的结合。而至于具体实现方式,主要取决于目标服务对于程序化访问的友好程度;这同时也代表着替身前端开发和保持存活的难度:
- **有的服务对开发者相对友好,提供了功能完整的 API。**例如,Reddit 在 API 开放方面一直做得不错,Twitter 也仍然保留了一些非正式的 API。对于这类服务,替身前端在开发时可以直接调用官方 API,类似于一个网页版的客户端;个别不能实现的功能再通过抓取网页补足即可。
- **有的服务没有公开的 API,但也没有对程序化访问做太多限制。**例如,Quora 和 Medium 的网页版都臃肿难用,但「只蠢不坏」,通过选择 CSS 元素和匹配正则表达式就能提取多数有用信息。对于这类服务,替身前端一般会模拟成浏览器,请求网页版,提取网页信息获得所需数据后整理过滤,呈现给用户。
- **有的服务不仅不提供 API,而且采用私有方式加密、主动屏蔽程序化访问;这种服务的替身前端开发起来难度最大。**例如,YouTube 对 720p 以上分辨率的视频只支持通过 DASH 协议分别传输音视频流,并且在默认情况下只允许根据带宽动态选择视频画质;Instagram 会随机轮换个人主页的数据路由,并且对访问频次有极其严格的限制。对于这种服务,替身前端就只能尽可能地猜测和模仿原生版本的行为,依靠轮换 IP 的方式减少被屏蔽的概率,同时依靠开源社区的用爱发电,及时适配和更新。
目的动机
大多数替身前端的都兼具两种目的:增强功能和保护隐私。
比较讽刺的是,在网页服务普遍臃肿的大环境下,替身前端最主要的一项「增强功能」往往是「做减法」,提供一个更简洁、轻量的界面。这主要是通过屏蔽原版服务重度使用的 JavaScript 脚本,以及与主体内容无关的装饰元素和广告实现的,在很多情况下能将动辄几 MB 甚至几十 MB 的原版压缩到 KB 级别。 除此之外,RSS 支持、内容下载或导出、评论布局优化等便捷小功能也是替身前端中常见的。
至于保护隐私,由于广告和追踪脚本被去除,网络请求主要由替身前端代理,平台运营者能收集和追踪的隐私数据自然极大减少。但必须指出,这里的「隐私」是要加脚注的,具体程度取决于多种因素,包括但不限于替身服务的代码质量、托管服务器和用户自身的网络配置等。总之,隐私保护充其量只是替身前端锦上添花的附加功能,任何严肃的隐私环境都不可能只靠它们来实现。
此外需要说明,替身前端不是绕过版权保护和权限管理的手段。一个简单的判断方法是,如果一则内容不能在未登录的情况下通过浏览器隐身模式直接访问(不包括为了引流而设置的软性登录墙、软性付费墙),那么也不能用替身前端来暗渡陈仓,例如 YouTube 上的付费视频、Instagram 上的私密账户等。
许可方式
尽管没有什么统一标准,但目前出现的替身前端几乎都是开源的,并且支持自托管。这也不难理解:从使用者的角度来说,要信任替身前端代替自己去访问目标服务,透明和可控是必要的,而代码完全公开、实例自己搭建,是实现透明可控的最直接方式。
而从开发者的角度来说,替身前端的原理决定了它比较脆弱,容易受到目标服务更新、平台采取抵制措施等外力影响;只有通过开源协作及时修复和更新,通过允许自托管扩大使用面和冗余性,才能最大程度地延长项目的「生命周期」。
常见替身前端介绍
如开头所说,替身前端的开发在近年有越发活跃之势,阵容在不断扩大。下表列举了一些我认为比较常用的,你也可以从 GitHub 项目 alternative-front-ends 看到更完整的名单。
| 服务名称 | 替身前端 |
|---|---|
| Fandom | BreezeWiki |
| SearX (SearXNG) 或 Whoogle | |
| IMDb | libremdb |
| Imgur | Rimgo |
| Bibliogram(已停止开发) | |
| Medium | Scribe |
| Quora | Quetre |
| Libreddit 或 Teddit | |
| Reuters | Neuters |
| TikTok | ProxiTok |
| Nitter | |
| YouTube | Piped |
下文对一些最常用服务的替身前端情况做简单讨论。
YouTube
由于需求太广,YouTube 的第三方插件或客户端也是多到令人眼花缭乱,各种收费模式、适配各种平台的选择都有。而符合本文开头定义、目前比较知名的替身前端主要有两种:Invidious 和 Piped。
其中,Invidious 是一个比较经典的项目,创立于 2017 年;但其主要开发者已经于 2020 年因其他事务退出维护,此后该项目的更新就比较缓慢了。而 Piped 相对较新,从 2020 年开始维护;根据其维护者的说法,相比于 Invidious,Piped 在性能、稳定性方面的表现更好(社区反馈和我个人体验也大致可以印证)。因此,本文更推荐使用 Piped 作为 YouTube 的替身前端。
当然,YouTube 的替代客户端选择很多,社区中口碑较好的还有桌面应用 FreeTube、移动应用 NewPipe,以及命令行工具 yt-dlp 等,由于超出本文讨论范围,在此不多介绍。实际上,这些工具之间在一些关键功能组件上互有借鉴,这也反映了开源社区的优势。
除了 YouTube 本体,其附属的音乐服务 YouTube Music 也有替身前端可用,例如 Beatbump 和 Hyperpipe,可以自行尝试。
作为英文世界的主要综合性论坛,Reddit 虽然近年因为臃肿的新版设计、强推变现功能而受到批评,但相比之下仍然是对极客用户和开发者比较友好的。除了前面提到的有功能完整的官方 API,还一直保持了 old.reddit.com 的域名,照顾那些偏好旧版界面的老用户。
old.reddit.com
因此,如果你的诉求只是找回传统简洁的页面,可以直接把 old.reddit.com 看成「官方版」的替身前端。
但如果对于功能增强和隐私保护有进一步的要求,可以考虑使用 Teddit 和 Libreddit 这两个来自社区的替身前端。两者都是从 2020 年底开始维护的,目前的活跃度和口碑不相上下,但 Teddit 的外观更「古典」,适合阅读文本为主的帖子;Libreddit 设计更现代,看图片居多的版块效果更好。
在主流服务中,为 Instagram 制作替身前端的难度可以说是「地狱级」的。如果你了解这些年来有多少前赴后继的第三方 Instagram 客户端,对此应该有所体会。简单来说,Meta 对旗下服务采用了非常严格的反爬措施,会积极封锁它认为可疑的 IP 地址,而提供的 API 基本只适合内容上传和分析营销目的,并且有很严格的用量限制。因此,在替身前端所必须的匿名环境下几乎无法通过正常方式获得 Instagram 的内容。
尽管如此,2020 年以来,还是有一个叫做 Bibliogram 的项目设法做到了这一点。然而,随着 Meta 不断加固自己的「围墙花园」,Bibliogram 最终无法跟上 Instagram 不断加码的反制措施,在 2022 年 9 月宣布停止维护;作者当时写的回顾文章非常值得一看,既是一篇充满信息量的技术分析,也是对垄断平台的一次血泪控诉。(比较讽刺的是,Bibliogram 难以为继的原因之一是它本身也被众多机器人盯上,当作为非个人用途爬取数据的抓手。)
目前,还有少量第三方 Bibliogram 实例在提供服务,但可用功能仅限显示单条发帖,不能显示用户主页或提取 RSS 订阅。
尽管很多说法会将 SearX(及其维护更活跃的分叉版 SearXNG)当作 Google 的替身前端,但这两个项目的初衷并不只是为了替换 Google,而是做一个全功能的「元搜索引擎」(meta search engine),也就是同时向多种通用和专用搜索引擎发起请求,然后将结果汇总呈现给用户。Google 只是它们能够调用的众多搜索引擎其中的一种,换句话说,它们只是「顺便」可以当成 Google 的替代前端来用。
当然,旨在直接替代 Google 的项目也是存在的,那就是 Whoogle。这是一个从外观到功能都一比一模拟 Google 的替身前端,但屏蔽了搜索广告、AMP 链接和追踪脚本等令人厌恶的元素,也不使用任何 JavaScript、cookies。虽然目前主打隐私的搜索引擎不少,但大多对于非英文关键词的支持都非常有限~(我甚至不知道用什么中文关键词可以避免在 DuckDuckGo 上搜出 NSFW 的内容)~,Whoogle 的存在对于中文用户也颇有意义。
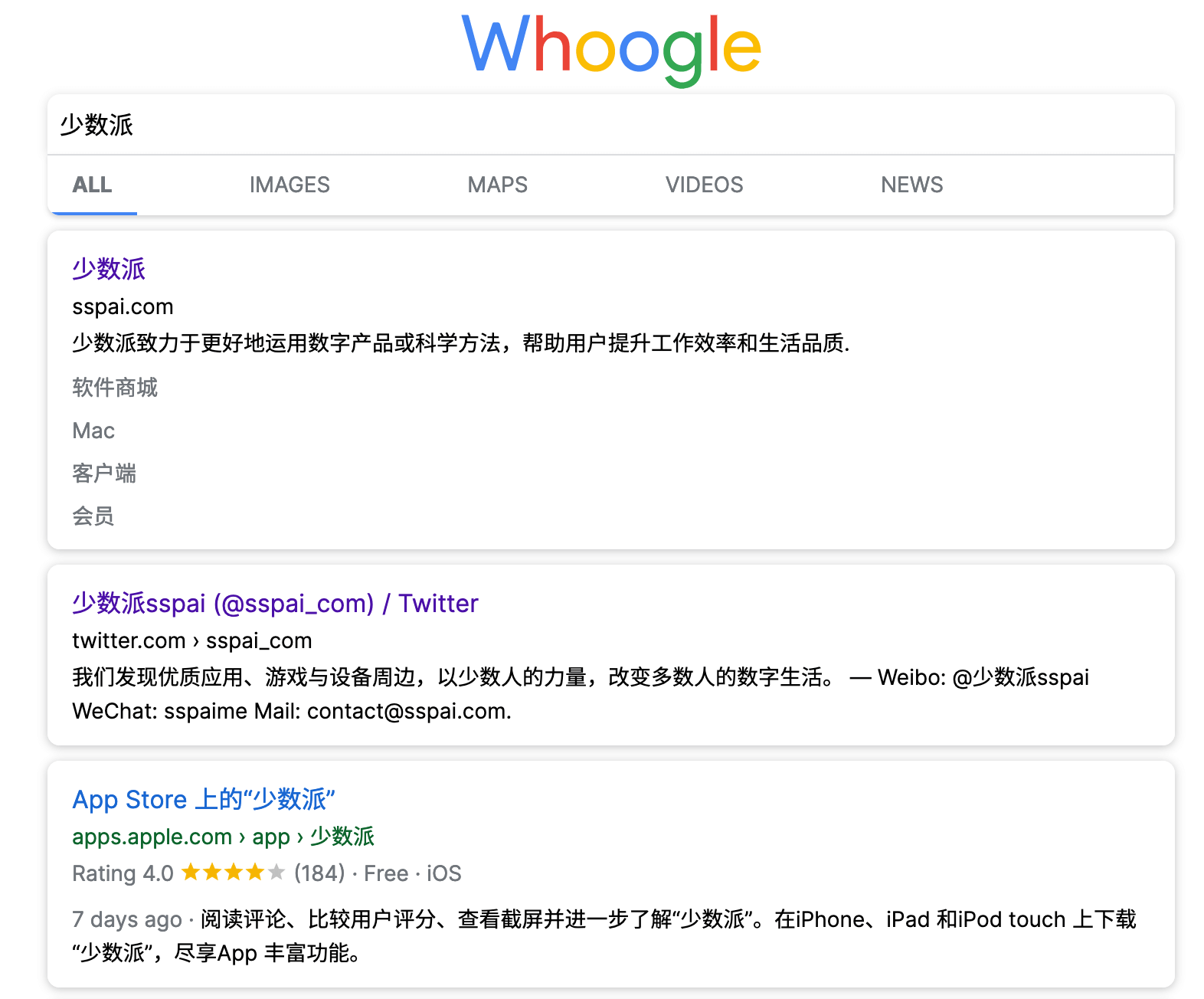
需要注意,Google 的反爬是特别严格的,很多数据中心的 IP 地址原本就在其黑名单之列,每次搜索都需要经过人机验证才能出结果,托管在这些机房的 Whoogle 或 SearX 实例也就无法正常工作。即使原本不在黑名单之列,也有较大概率在频繁使用后被拉黑,因此很多 Whoogle 和 SearX 实例的生命周期都是有限的,全凭 Google 生杀予夺,需要经常更换。
因此,如果你希望看到 Google 的搜索结果,同时可以接受一定程度上的「不自由」,那么可以考虑使用 Startpage;这家搜索引擎付费采购了 Google 的 API,搜索结果大致相近(但仍有区别,特别是非英文关键词),不妨一试。此外,SearX 也支持间接调用 Startpage。
关于替身前端服务器的选择
如上所述,开源、可自建是替身前端的主要特征之一。因此,每个替身前端有一定用户基础后,都会产生大量由社区用户自发提供的公开实例(服务器)。实际上,大多数替身前端都会在代码仓库、文档页面或官方网站等位置提供一个不断更新的服务器列表(例如 Invidious 的列表、SearX 的列表),任何人都可以通过提交 pull requests 的形式参与维护。这就涉及到怎样选择的问题。
由于这些列表一般都是按照平均响应速度、版本更新情况等标准排列的,可以从排名靠前的服务器中找几个测试,选择一个在自己网络条件下响应最快的即可;后文将会提到的一些专门插件还内置了服务器更新、测试和自动选择功能。至于是否要为了强化隐私,在不同服务器之间频繁轮换,本文的观点是作用有限,而且会让历史记录非常凌乱,并不推荐一般用户这么做。
值得一提的是,不少列表会用警示颜色标注出使用 Cloudflare 服务的节点。这主要是因为 Cloudflare 本身相当于一层代理,并且受美国法律管辖;一些对于隐私比较执着的用户认为这会增加不必要的信任成本,主张尽量避免。但另一方面,Cloudflare 也能起到加快访问、避免攻击的效果。本文对此不做判断,读者可以根据自己的偏好选择。
当然,你也可以选择用自己的服务器来搭建替身前端,这样更加稳定,也不需要担心陌生人的服务器是否安全。但需要同时考虑的一些「劝退」因素是:你的服务器未必比一些大型公用实例的性能更好;自建服务也不能保证完全的隐私,因为仍然包含了一层对于服务器提供商的隐含信任;如果自建服务的机器访问过于频繁,可能被 Google 、Meta 等大型平台标记和封禁,影响这台服务器的其他职能。因此,本文建议只自建确实用得上的服务,并且避免在已有其他主要用途的服务器上搭建。
替身前端的使用方式
尽管按照惯例,替身前端一般都支持与原版服务一比一的链接替换——将原始链接的域名部分换成替身前端的服务器地址即可「一键换装」,但如果每次都要手动修改还是过于麻烦了。因此,有必要用一些工具来简化这一流程。下面,我们按照从专用到通用的顺序分别介绍几类方法,读者可以根据运行环境和偏好自行选择。
专用插件
随着替身前端的队伍日益壮大,社区中也出现了相应的专用浏览器插件。安装这些插件后,每当点击原版服务的链接,就会被自动跳转到对应的替身前端链接。此外,不少插件还具有服务器切换和服务器列表更新功能,可以自动从官方来源获取目前有效的替身服务器实例,从而缓解了服务可用情况变动对使用的干扰。
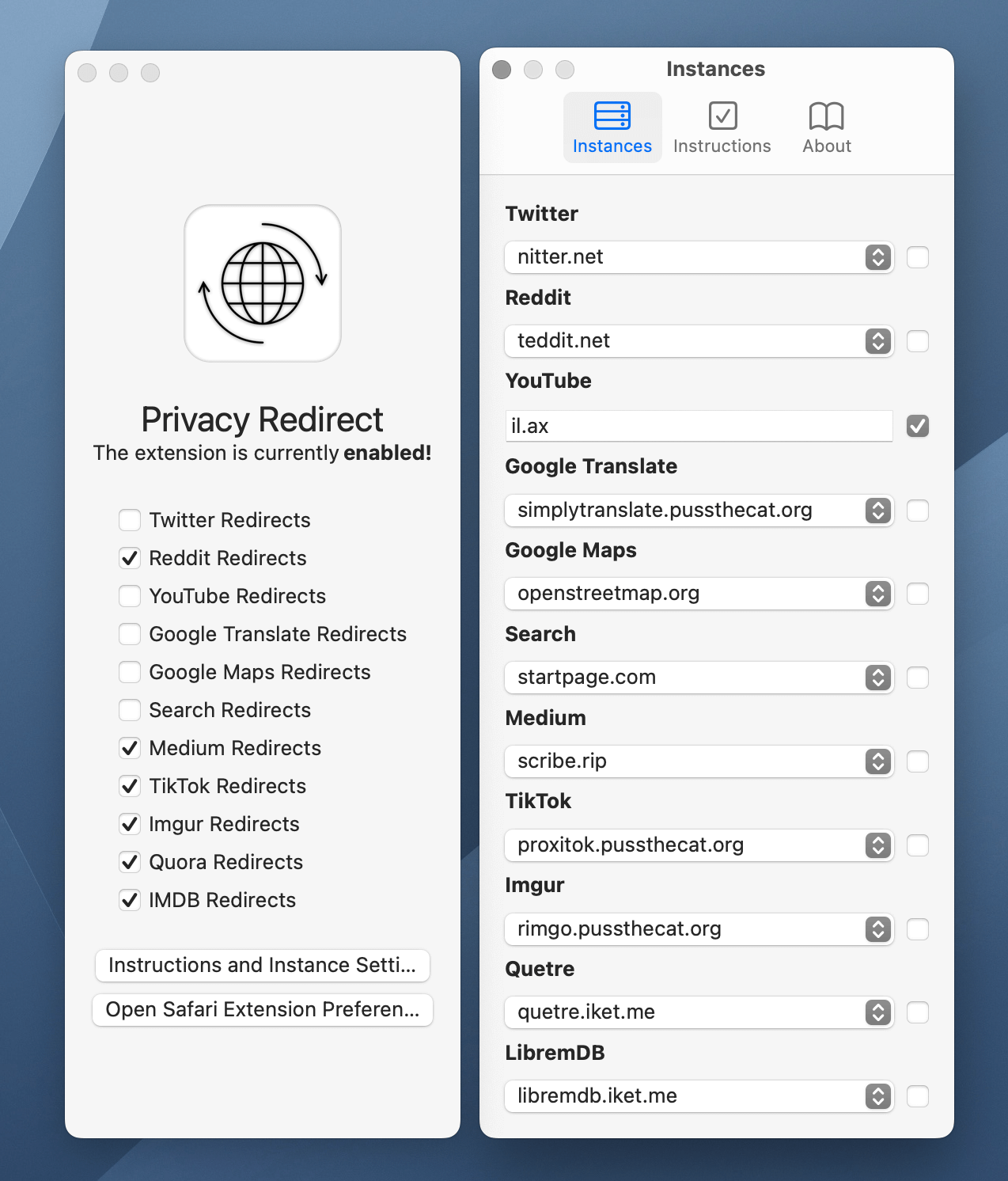
在桌面端,目前最好的选择是 LibRedirect。 它分叉于历史更久的 Privacy Redirect,但后者已经很久没有更新了。

LibRedirect 支持 Firefox 和 Chrome 两种主流浏览器。遗憾的是,由于 Chrome 已经逐渐开始实施颇受争议的 Manifest v3 迁移进程,而 LibRedirect 的功能很大程度上依赖于旧的 WebRequest API,属于 Manifest v3 的直接打击对象。因此,该插件目前无法上架 Chrome 或 Edge 官方商店,只能下载未打包版本后自行加载,并且在 Chrome 正式移除 Manifest v2 和相关旧 API 支持后(最早可能发生在 2023 年 6 月),几乎需要从头重写才能继续运行。
LibRedirect 不仅收录服务覆盖面广,而且各种辅助功能做得极为周到。对于每一项原版服务,可以选择要使用的替身前端类型、服务器地址;并且可以选择多个服务器,每次跳转从中随机选择一个作为替身,通过分散访问进一步提高隐私程度。此外,在工具栏的插件按钮中,LibRedirect 提供了各项服务的快捷开关,以及复制原版服务地址、在同类替身前端的不同服务器之间同步设置等功能按钮。
**在移动端,Android 用户有浏览器插件或者独立应用两种方式可选。**对于前者,装一个允许安装插件的浏览器,然后直接使用 LibRedirect 即可。例如,Firefox Nightly,Fennec、Iceraven 等 Firefox 发行版,以及 Kiwi 等 Chromium 发行版都支持安装插件。
此外,也可以安装 UntrackMe 这一工具,以便实现系统全局的跳转。它的原理是将自己注册为原版服务相关域名的默认打开方式,每当检测到用户正在访问原版服务时,就改为打开对应的替身前端。
对于在桌面端使用 Safari 的用户和只有 Safari 可用的 iOS 用户,Privacy Redirect for Safari 是一个稍弱但仍然好用的选择。 与 LibRedirect 相比,这个插件收录的服务类型、服务器数量都要少一些,每次更新服务器需要作为应用更新等待审核上架,因此可能不够及时;遇到一些「青黄不接」的时候,需要通过手动设置地址功能更换新出现的有效服务器。
还需要注意,由于苹果对 Safari 插件的(莫名其妙的)限制,改写请求类的插件只能在请求发出后才能对其进行改写。反映在实际体验上,访问原版网站之后至少会有一秒甚至更长的停滞,然后 Safari 才会「恍然大悟」般地改为访问替代前端。不仅如此,由于请求已经向原网站发出,覆水难收,这种运行机制也就无法起到任何保护隐私的作用,而只能用来改善浏览体验了。
最后,还有一个叫做 Farside 的有趣开源项目,可以看作免安装的替身前端插件。这个项目收录了目前各大替身前端和服务器列表,只要在原始地址的开头加上 farside.link (或者你自建的实例地址)后直接访问,Farside 就会随机选择一个替代前端服务器并跳转。更具体的用法可以参见项目主页。
改写网络请求
如果你不想为了使用替身前端专门装一个插件,或者设备环境不支持安装插件,也可以考虑更通用的做法——改写网络请求,也就是将指向原版服务的请求替换为指向替身前端服务器的请求。这可以在浏览器和操作系统两个层面进行。
在浏览器层面, Firefox 和 Chromium 系浏览器可以使用 Redirector(开源),Safari 可以使用 Redirect Web for Safari(免费下载;2 个以上规则需 $4 内购)或 StopTheMadness($10)。这些插件的用法大同小异,都是通过正则表达式规则来匹配并替换域名。
例如,要用这类插件手动制作一条将 Twitter 重定向到 Nitter 的规则,可以用正则表达式匹配:
^https?:\/\/(www\.|mobile\.|)twitter\.com(\/|$)(.*)?
替换为:
https://nitter.net/$3
(开源的好处再次体现出来:如果懒得自己写规则,可以去 LibRedirect 的源代码里抄抄作业,将 JSON 里对反斜线的双重转义 \\ 改回 \ 即可。)
在系统层面, 可以使用各种网络调试工具的重定向功能,具体规则写法因软件而异,请自行查阅相关文档。需要提醒的是,由于替身前端针对的原版服务基本都全面启用了 HTTPS,需要向系统中安装自签名证书、启用 HTTPS 解密(MitM)才能实现重定向。这会导致配置步骤相对繁琐、而容易造成误伤,本文不建议这么做,仅为论述完整目的列入此处。
小书签或 UserScript
如果进一步追求简洁,并且不介意少量手动操作,可以用一个小书签(bookmarklet)来快捷地将原版服务地址换成替身前端地址。
例如,下面这段代码的功能是从 Twitter 跳转到 Nitter:
javascript:(function(){location.host='nitter.net';})()
这里,location.host 指的是当前浏览地址中的主机(host)部分,将其改写为 nitter.net 就可以跳转到 Nitter。
这当然是高度简化的。为了让代码更通用,我们还可以让它识别并相应处理不同类型的服务,并且在无法识别时自动停止执行。例如,下面的代码可以同时实现 Twitter—Nitter、YouTube—Piped 和 Reddit—Teddit 的跳转(均使用项目官方服务器):
javascript: (function () {
var reTw = /(www\.|mobile\.|)twitter\.com/,
reYt = /(www\.|m\.|)youtube.com/,
reRd = /(www\.|old\.|np\.|new\.|amp\.|)reddit\.com/;
switch (true) {
case reTw.test(location.host):
location.host = 'nitter.net';
break;
case reYt.test(location.host):
location.host = 'piped.video';
break;
case reRd.test(location.host):
location.host = 'teddit.net';
break;
}
})();
这里,我们首先用正则表达式判断当前正在浏览什么平台的页面,然后用 case 替换为相应的域名。如果需要增加或修改服务类型,相应调整这两个部分即可。
(你可以安装我预先做好的上述书签模板。)
如果你想省去额外的点击步骤,也可以使用 TamperMonkey 等 UserScript 管理器来实现自动跳转。例如,下面这段 UserScript 在安装并启用后,可以实现从 Fandom 跳转到替身前端 BreezeWiki:
// ==UserScript==
// . . .
// @match *://*.fandom.com/*
// @run-at document-start
// . . .
// ==/UserScript==
window.location.host = window.location.host.replace("fandom.com", "breezewiki.com")
这里,元信息区块(metadata block)里的 @match 键通过正则表达式匹配当前域名,@run-at 键指定脚本的执行时间点是原始页面开始加载之前(document-start),之后的跳转原理和上述的小书签方法完全相同。(关于元信息区块的具体说明,参见文档。)
结语
以上就是我关于使用替身前端的心得。可以看到,替身前端虽然能解决原版服务的很多问题,但也不是什么万灵药,而是需要付出一定的学习和选择成本。此外,与商业化运作、大团队维护的原版服务相比,社区驱动的替身前端在设计和操作上其实并不够「精致」,说好听是「黑客审美」,说直白点就是有很多随意甚至古怪之处。但「方便」和自由本身就是此消彼长,商业平台只是用精致的外观把技术的复杂性包裹起来,并收取自由作为费用;替代前端则反其道而行之。即使不作为主力用途,不时关注和观察这些与主流对抗的独立作品,对于在技术割据时代保持独立判断也是有利的。