付费墙的短与长(一):起源与演变
A version of this article appears on Feb. 9, 2023 on SSPAI as a member-only post. Learn more or subscribe
The article is permitted to be self-archived in the version as originally submitted for publication on the author’s personal website under CC BY-NC 4.0 pursuant to § 5.2(b) of the SSPAI Fellowship Contributor Agreement.
引言
在当今的内容生态中,付费墙(paywall)是每个互联网用户都会经常打交道的商业模式。(Full disclosure: 本文就将在一个有付费墙的产品中最先发布。)
如果追求简洁,付费墙的含义一句话就能说清楚,无非是花钱解锁付费内容。而所谓的「墙」,既指为了阅读需要支付的费用,也指根据付费状态挡住或释放付费内容的技术手段。
但相信每个和付费墙打过交道的用户,都会对这一模式的真实机制和效果产生疑问:为什么明明是同一个网站,有时伸手要钱,有时又能敞开了看?付费订阅的文章可以先存后看吗?为什么稍后读工具有时能获取全文,有时只能存个开头?如何看待付费墙对于出版方和读者的利弊?如何评价分享付费墙后内容、绕过付费墙的行为?
基于此,本系列文章计划对付费墙做一次较为系统的介绍,希望帮助读者更好地理解这一模式,在付费决策时更心中有数,也能更有效地利用付费所得的内容。
注: 本文所讨论的付费墙,主要指针对图文内容设置,基于商用内容管理系统,具有自动化付费—解锁流程的现代付费墙;不包括学术期刊内容,也不包括那种通过手动配置用户分组权限实现的简易付费机制(常见于小型个人创作者的 WordPress 等站点)。本文中涉及的技术讨论可能被用于一些绕过付费墙的做法,但提及并不代表对该等做法的鼓励。
付费墙的起源
尽管维基百科等来源将《华尔街日报》1996 年设置付费墙列为一个开创性事件,但付费墙模式并不是由它首创。
1994 年底,《圣何塞水星报》(San Jose Mercury News)就开始通过互联网提供新闻内容,并从次年一季度正式划分付费专区,收取 4.95 美元的月费。但这次尝试没能坚持多久,也不是 21 世纪之前的主流做法。当时,出版方的普遍态度还是将互联网作为一个通过免费内容吸引流量,进而获取广告收益的渠道。
随着早期互联网泡沫在新千年前后破灭,这种对注意力经济的乐观态度发生了改变。加上传统媒体的实体业务开始下滑,更多出版方开始考虑直接对线上内容收费。具体模式则是五花八门:有的对单篇文章收费,有的出售 PDF 版的印刷报纸,还有的则出售特供内容。
但走得最靠近现代付费墙模式的还是以《华尔街日报》《金融时报》为代表的专业财经媒体,它们从很早开始就坚持将大部分内容放在定价不菲的付费墙之后。2007 年,《金融时报》还首创了计量(metered)模式,设置了 30 篇的月度免费额度,对其后的文章收费。但在这些报道领域专精、受众付费能力更强的财经媒体之外,大众媒体尚未没有发展出一种成熟和广泛采用的模式。
付费墙真正走上主流舞台是 2010 年前后的事。当时,iPhone、iPad 的陆续问世带来了一波数字阅读的热潮;媒体大户默多克公开支持付费墙模式,其新闻集团旗下《泰晤士报》《每日电讯》等主流报刊的网站转为付费。
一个地标性事件发生在 2011 年 3 月:在此前多次效果不佳的尝试后,《纽约时报》网站再次推出付费方案,每月提供一定数量的免费文章(起初为 20 篇,后来降为 10 篇),然后收取 15 美元起的月费。很多同行都看衰此举,但它这次成功了,付费墙上线四个月内就获得了四十万付费用户(2021 年末突破 1000 万,比目标提前三年)。
《纽约时报》在新闻界举足轻重的地位产生了示范效应,北美的其他媒体纷纷效仿,随后又传播到欧洲,其结果自然有成功也有失败。但无论如何,付费墙的一种典型模式就此成型,并且越发深入人心。
付费墙的分类和机制
软硬二元区分的限制
当然,《纽约时报》创立的模式再经典,那毕竟也是十多年前的事情了。此后的年头里,出版方也没有停止尝试的脚步,而是继续演化出了更多的玩法。试试盘点一番你正订阅的付费内容,想找出两个完全相同的模式可能不太容易。那么,如何有体系地对付费墙进行观察和归类呢?
对此,维基百科的「付费墙」词条试图将付费墙分为「硬性」和「软性」,认为两者的区别在于是否提供部分免费内容,并将那种每月循环提供限量试读篇幅的计量模式作为软性付费墙的具体形态之一。这援引自一篇 2012 年的文章,也代表了一种比较常见的提法。
但稍有一些内容订阅经验的读者都会同意,这样分类已经不太有意义了。如今,出版方越发频繁地调整其付费墙机制,以便适应其对运营目标、受众群体和付费意愿的最新判断。更重要的是,随着技术的发展,付费墙早已经不再需要是「铁板一块」,而是可以根据用户的画像信息,动态地「伸缩」「开闭」,即时改变免费内容的范围,试图兼顾免费流量和付费收益这两个矛盾的目标。
换言之,今天的付费墙已经没有绝对的「软」「硬」对立,而是按照其限制的严格程度分布在一个光谱上。实际上,绝大多数出版方都会提供一些「免费午餐」和「后门」,差别只在于频率和范围;真正的铁公鸡几乎是不存在的。
本文认为,要真正理解类型繁多的付费墙,比起简单的软硬二元区分,应该更细致地观察其具体机制和原理。这至少包括以下两个维度:
- 解锁条件,也就是在什么情况下允许访问付费内容;以及
- 加载机制,也就是在判断解锁条件的基础上,用怎样的技术手段隐藏或显示付费部分。
下面分别举例说明。
付费墙触发和解除条件
如何解除付费墙?这听起来像句废话:终极的答案毫无疑问只有一个,那就是掏钱。但除此之外,大多数网站都会设置各种弹性条件,以便达到招揽新客、吸引互动或收集信息等目的;让我们逐一盘点。
访问频次
这就是计量式付费墙主要依据的判断条件,最常见于各种新闻网站。一般模式是允许访客免费阅读一定数量的文章,超过这个数量再阅读时,则隐藏开头段落以外的部分,并提示付费或订阅;免费额度会定期(一般是每月)重新计算。
以访问频次为条件,意味着需要记录用户的访问历史。这既可以在客户端实现(通过 cookies、localStorage 等缓存机制),也可以在服务端实现(通过记录 IP 地址或其他可识别信息)。显然,后者更不容易被「钻空子」,但有更高的开发、维护和隐私合规成本,且比较容易误伤,因此更多网站还是以本地缓存为主。
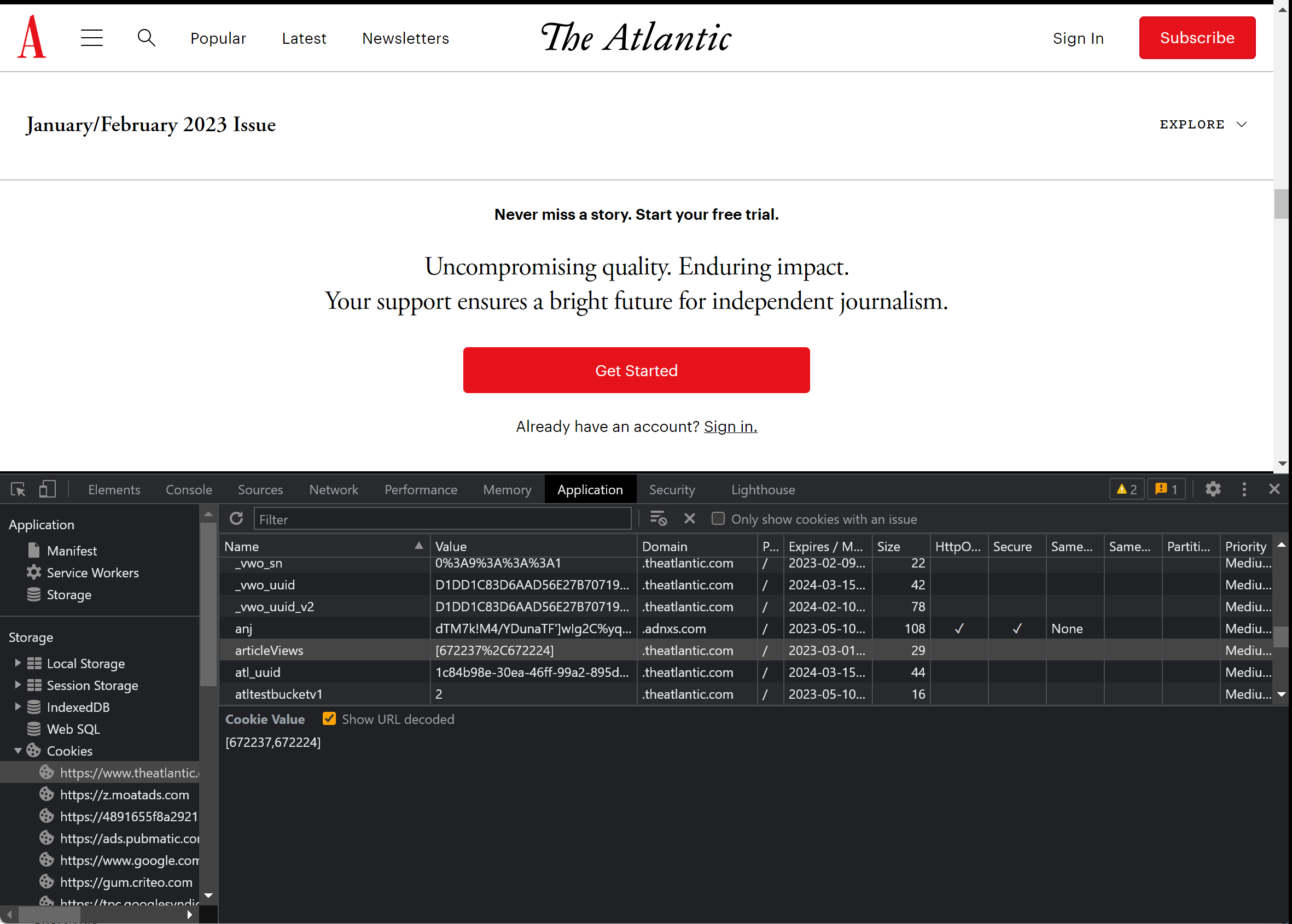
例如,《大西洋月刊》对于未登录用户打开的第一篇文章免费放行,如果继续阅读就要求付费。检查浏览器 cookies 存储可以发现,该网站通过一个 articleView 字段存储用户浏览过的各篇文章编号;如果删除这个字段(或者改用隐身模式访问),下次访问的文章就不会显示付费墙。这也是一种最老套的「软性」付费墙实施方式,因为太容易绕过,用得已经越来越少了。
相比之下,《纽约时报》的做法是将计量付费墙和注册墙(registration wall 或简称 regwall)结合起来。具体而言,当未注册用户打开第一篇文章时,页面会要求完成注册才能阅读。这是一个显然经过优化的流程,被压缩到基本只填个邮箱就完事。如果用户读完之后再打开一篇文章,就会显示正式的付费提示。至于价格,则是根据日期、地理位置等因素动态变化的,不同人看到的可能相差数倍(标注方式也具有高度的误导性)。


此外,《纽约时报》网站也会记录大量 cookies 信息,包括用户近三周的活跃情况、最近访问时间等。
跳转来源
如前面所说,任何付费墙机制都试图在促进销售和促进传播之间摸索出一个平衡点。而要促进传播,谷歌、推特、Facebook 等搜索引擎和社交媒体带来的流量不容忽视。因此,很多付费墙机制都会对从这些平台跳转而来的访客网开一面。
还是以《纽约时报》举例。上面所述的注册墙—付费墙流程,只适用于从其首页直接打开文章的情况。如果从谷歌搜索页面或者通过推特上的链接打开同一篇文章,就不受这种限制,可以直接阅读全文,只是页脚有一个提示注册的横幅。
这在技术上实现起来也很简单:出版方可以从 HTTP 请求中的 referer 属性得知用户是从哪里找上门来的。此外,平台类网站普遍在链接开头添加的跳转域名(如 t.co)或在尾部追加的引荐参数(如 ?utm_medium=social)也能表明流量来源。如果发现流量来自搜索或分享,直接放行即可。
显然,跳转来源也是一种比较容易被钻空子的方式,因为 referer 属性非常容易从用户侧操纵。例如,只要在谷歌中搜索文章链接再点击搜索结果,或者将链接通过推特私信发送给自己,就可以获得相应的「通关文牒」——这都是早年绕过付费墙的常见「技巧」。如今,越来越多的网站已经变得精明,不再简单地通过跳转来源判断是否显示付费墙了。
网页版本
随着移动时代的到来,出版方开始越发重视移动端的流量。为此,不少付费墙采取了桌面端和移动端「区别对待」的策略,为移动版或 app 端的页面设置更为宽松的访问条件,目的在于引导用户多用这些版本。当然,也存在一种正好相反的做法:为越来越少见的桌面端流量网开一面(毕竟你很难赚到伯夷叔齐的钱),而集中精力向移动端用户推销付费产品。
根据网页版本提供不同范围内容的做法有两个特殊情况,其动机都与搜索引擎优化有关。首先是对谷歌的 AMP(Accelerated Mobile Pages)页面放行。简单来说,AMP 页面是一种符合谷歌私有规范,专为移动端优化的内容格式。由于元素比较简洁、而且通过 CDN 缓存,其加载速度(理想条件下)比完整页面更快。早年,谷歌曾经大力推行这种标准,并且在搜索页面通过显眼的「走马灯」横幅展示支持 AMP 的文章,很多网站出于引流的目的,也会愿意为 AMP 版本设置比较宽松的付费墙。(AMP 页面因为开放性、隐私性等问题,在技术群体中口碑很差,但那超出了本文的讨论范围。)
例如,《巴伦周刊》(Barron’s)等道琼斯旗下刊物是传统意义上的「硬性」付费墙,如果不订阅就不能查看任何文章,隐身模式、跳转链接等雕虫小计也不能撼动。但是,它确实会对从谷歌搜索页跳转而来的 AMP 页面开放少量篇幅的免费文章。
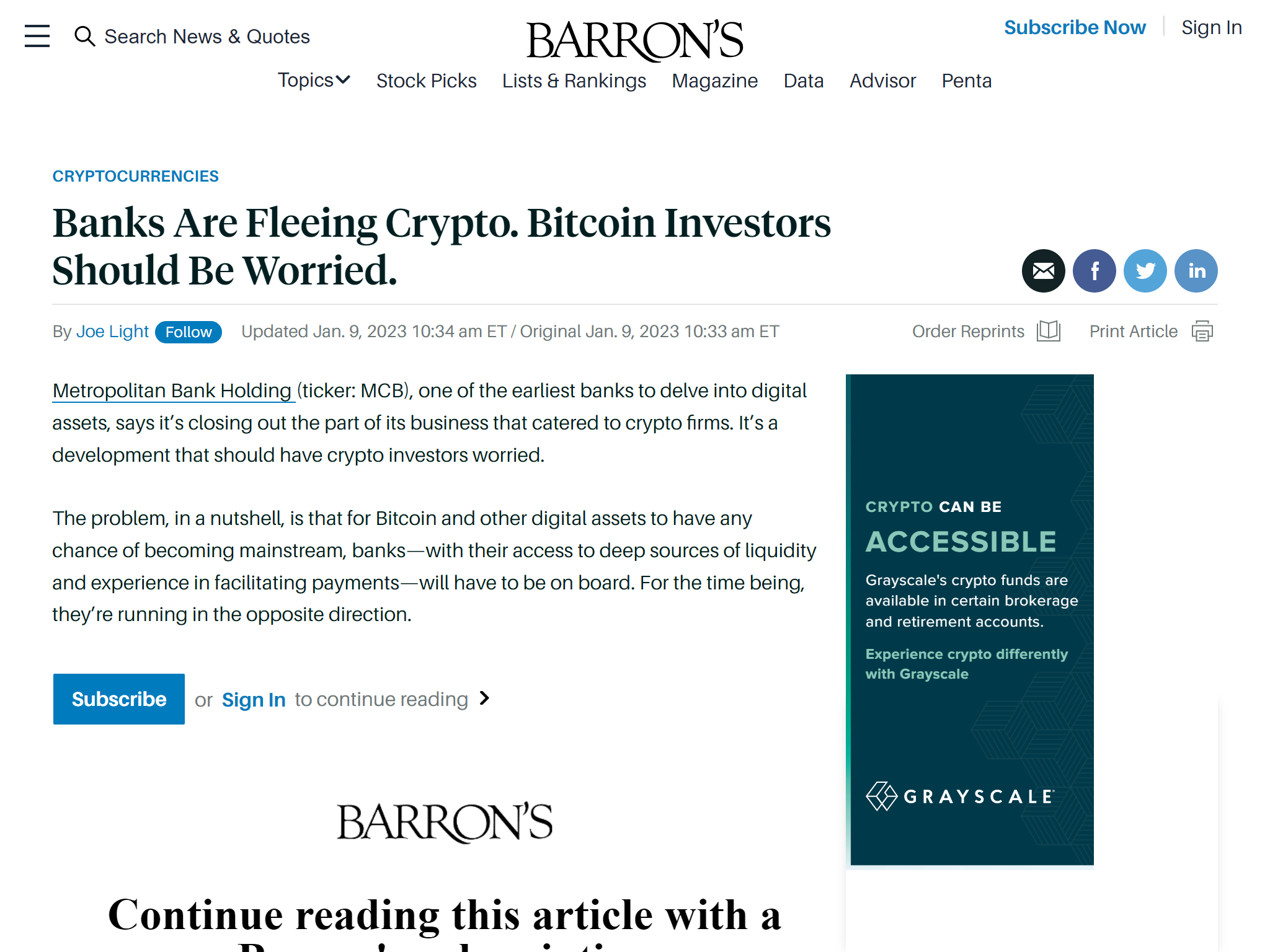

另一个特殊情况是对特定用户代理(UA, user agent)开放。对于很多媒体来说,少让几个读者看到文章没关系,但一定不能不让搜索引擎看到。否则,文章无法被索引,就不会出现在搜索结果里,流量就无从产生。而要做到向搜索引擎定向开放,只要关注所有 HTTP 请求都会带有的 UA 信息就行了;如果发现是类似这样的谷歌机器人 UA:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
就直接提供全文方便抓取。
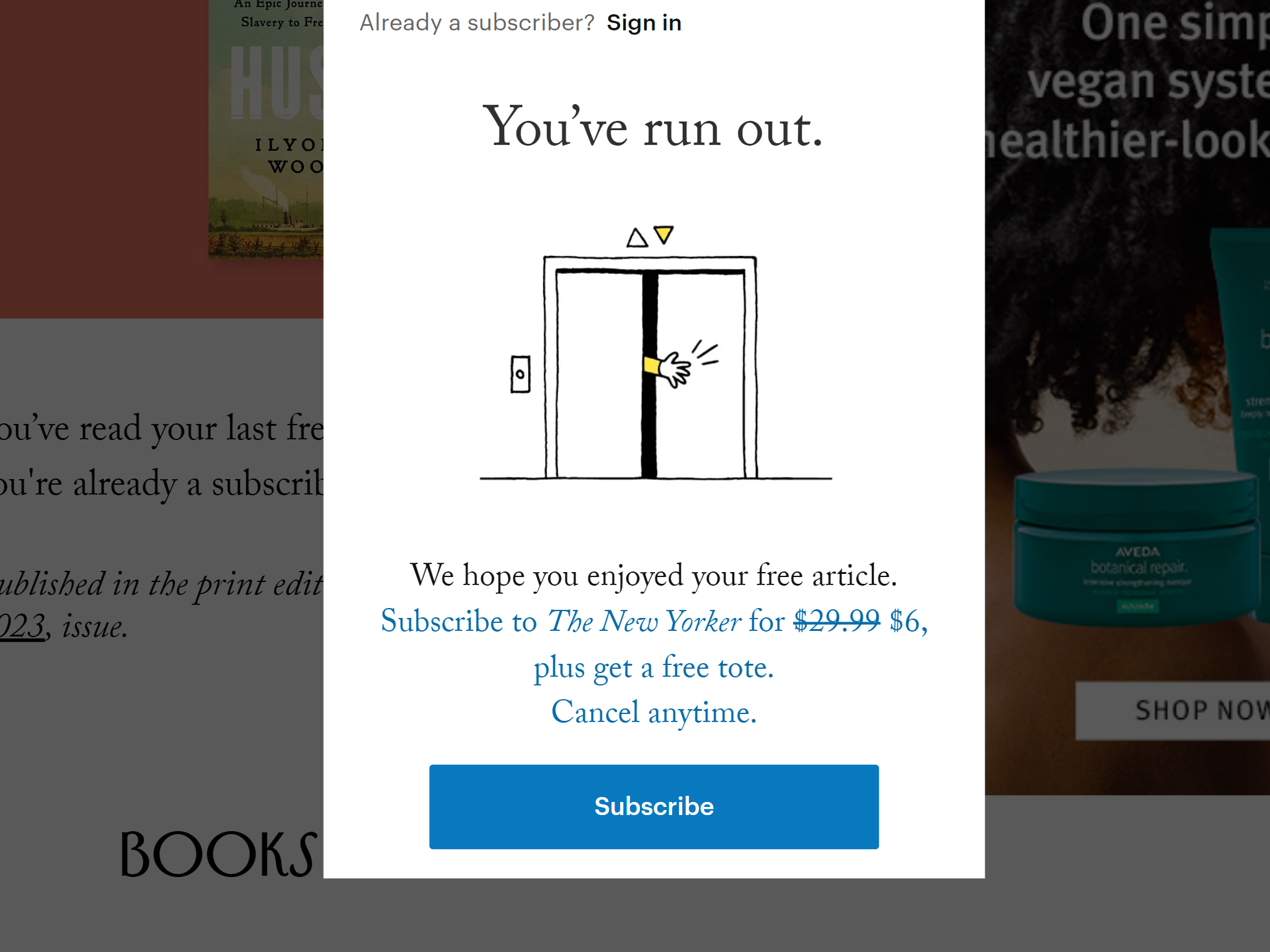
例如,《纽约客》杂志的网站平时采用计量式付费墙,阅读数量达到大约三篇后会开始显示遮挡横幅。但如果将 UA 修改为谷歌机器人,就会看到一个不受限制的全文页面(尽管因为没有加载很多额外样式显得有点简陋):

地理市场
这主要是欧洲《通用数据保护法》(GDPR)生效后出现的特殊现象。由于实行 GDPR 后,在欧洲市场的隐私合规门槛很高,一些非欧洲网站在没有足够法律资源的情况下,会选择直接「躺平」,对欧洲访客少展示甚至不展示广告和付费墙。
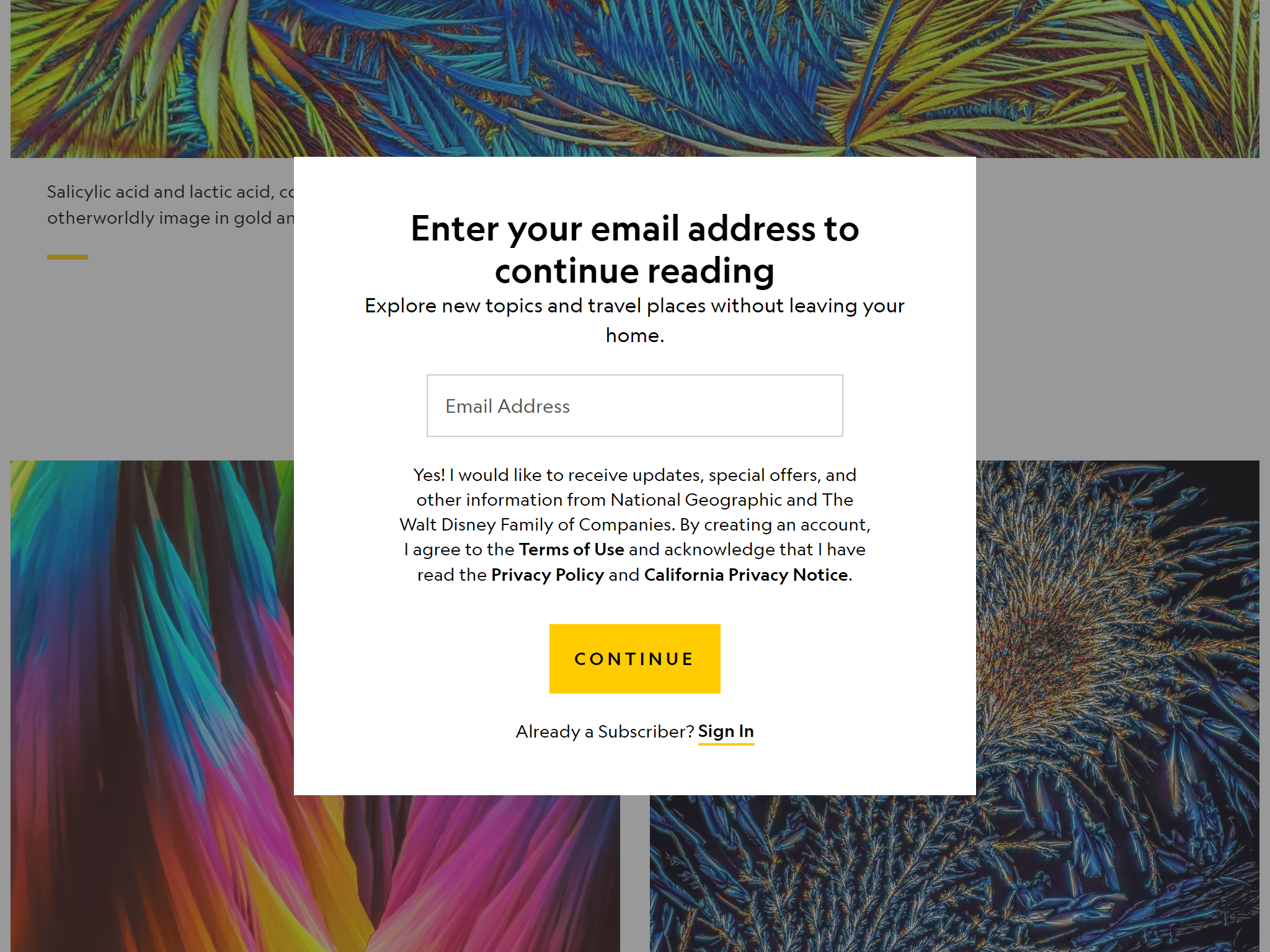
例如,《国家地理杂志》的网站对于美国本土访客,采用的是注册墙和付费墙结合的机制。但对于欧洲访客,则不会显示付费墙,取而代之的是连篇累牍的隐私信息收集提示。(有的时候你真的很难评价欧洲给世界互联网带来了什么,更少的广告和更多的牛皮癣?)

内容隐藏和加载机制
在判定解锁条件的基础上,出版方还需要设置一个自动隐藏和加载付费内容(或内容片段)的技术手段。这在实践中也有简繁之分。
遮挡或隐藏
这是一种比较基础和常见的方法:即使没有满足解锁条件,付费内容也随着页面正常加载,只是被其他元素(往往是引导注册或付费的广告横幅)遮住,或者隐藏显示。
例如,《纽约时报》的付费墙触发后,就会以横幅和深色背景将主体内容遮住,并且通过脚本限制滚动页面。但从浏览器检查器可以看出,网页已经加载了完整的内容,只是被上层元素挡住了。
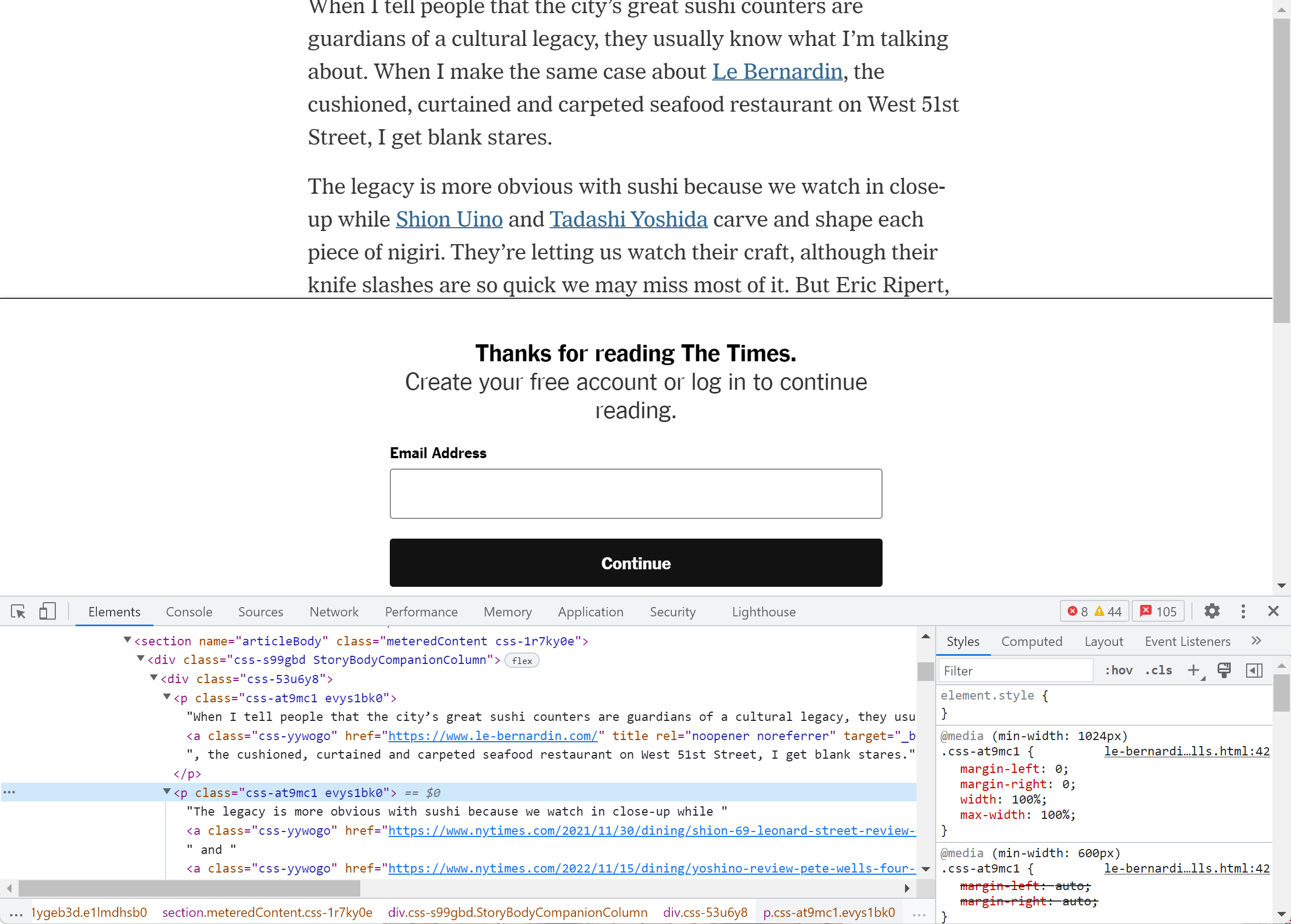
靠隐藏和遮挡来实现付费墙,在技术上比较简单,但防御效果也比较弱:只要反其道而行之,屏蔽相关脚本或者删除遮挡元素,即可拆除付费墙。稍微通晓一点网页开发常识的用户,只靠浏览器的自带功能就能徒手完成。
延迟载入
相比之下,一种更为「强硬」的形式是延迟加载:全文内容要么 (a) 暂不随网页一起从服务器加载;要么 (b) 虽然加载,但暂不渲染成为页面的一部分,而是以 JSON 数据等形式暂存。只在解除条件满足后,页面脚本才会才向服务器请求完整的内容,或者从暂存的数据中提取内容,将其显示在页面上。
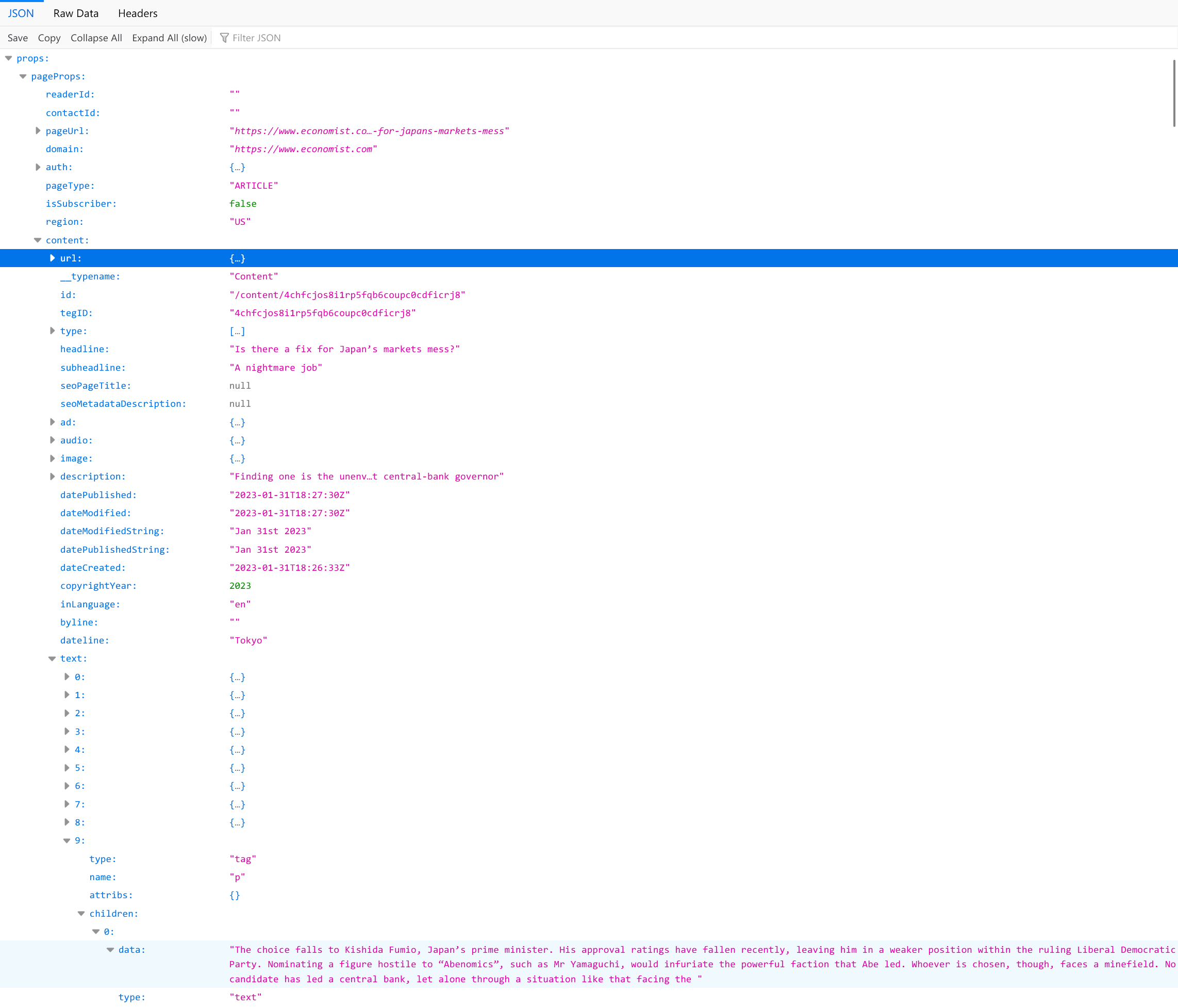
例如,在《经济学人》的网站上,如果付费墙未解除,完整文章不会显示,页面上也没有剩余内容对应的元素。但全文内容实际上已经在头部信息的脚本中「待命」,在解除条件满足时就可以被读取并替换到页面上。
《华尔街日报》则更进一步,如果付费墙未解除,文章前几行字之后的部分不会以任何形式载入,只有用户登录订阅账户以后才会开始加载。
小结
至此,我们在简单回顾付费墙起源的基础上,讨论了当今付费墙的主流类型,提出付费墙已经不能用简单的「软」「硬」来做二元区分,而应从解锁条件和付费机制两个维度具体观察,进而以一些主要在线媒体目前采用的机制举例分析。
为什么要花这么多功夫观察付费墙机制?因为这方面的细节能在相当程度上反映出版方的真实商业意图,进而为评价付费墙提供更合适的依据。
这种商业意图在出版方对于「漏洞」的态度上体现得最为明显。如果按照最简单直白的思路,付费墙似乎当然是越「硬」越好,不然就是放着钱不赚。但上面多次举例的《纽约时报》显然不是这样——走后门机会又多、技术限制又容易绕过。事实上,时报的付费墙从上线开始就以其「古怪」而出名,以至于在业内催生了「多孔型」(porous)付费墙这一术语。这是傻呢还是怂呢?
当然不是。《纽约时报》并不是不知道自己的付费墙像纸糊的一样;它只是不在乎。至少从经济效益上看,时报的数字化转型可以说是传统媒体迄今为止最成功案例之一,而那面看似「多孔」的付费墙在其中扮演了重要的角色。
要理解这种现象,就必须认识到:付费墙的根本目的不在于堵住内容,而在于区分人群。成功的付费墙必然是对交叉补贴原理的充分运用;其既不同于追求从支付意愿高的群体获取最多收入,也不同于追求从价格敏感群体获取最多流量价值,而是要让两者之和最大化。
「漏洞百出」的付费墙就是这种思路指导下有意为之的选择。对于这种以时事新闻为主要产品、以一般大众为主要读者的媒体来说,内容的最大传播与从内容获得收益至少是同样重要的目标。为此,一两份低价订阅的得失是不足为道的。这有点像微软对待操作系统盗版的态度:如果有人不愿意捧个钱场,至少要争取到捧个人场;总归能挣到一份流量和广告收益(时报的订阅权益不能包括去广告)。但不难想象,如果一家定位垂直的刊物对着照搬,肯定只会被人占便宜到血本无归。
与此同时也必须指出,付费墙越是「先进」,往往也就越是以资源消耗和隐私滥用为代价。如果采用最传统的「一刀切」规则,只要判断有没有付费这一个参数就行了。而当付费墙发展到《纽约时报》那种「智能」程度时,就要通过大量收集用户数据、加载层层堆积的 JavaScript 脚本,才能实现「见人说人话,见鬼说鬼话」的效果。(别忘了这还是一堵宽进严出的墙,时报退订流程的难度和阴暗程度是出名的。)IT 界古训有云,如果你用免费产品,你就成了产品。这在付费墙的语境下可以推演成:你越是看似占到了便宜,越可能其实被反过来占了便宜。
下一篇文章中,我们将探讨付费墙对用户保存内容造成的不便,以及如何通过合理方法解决这些问题。