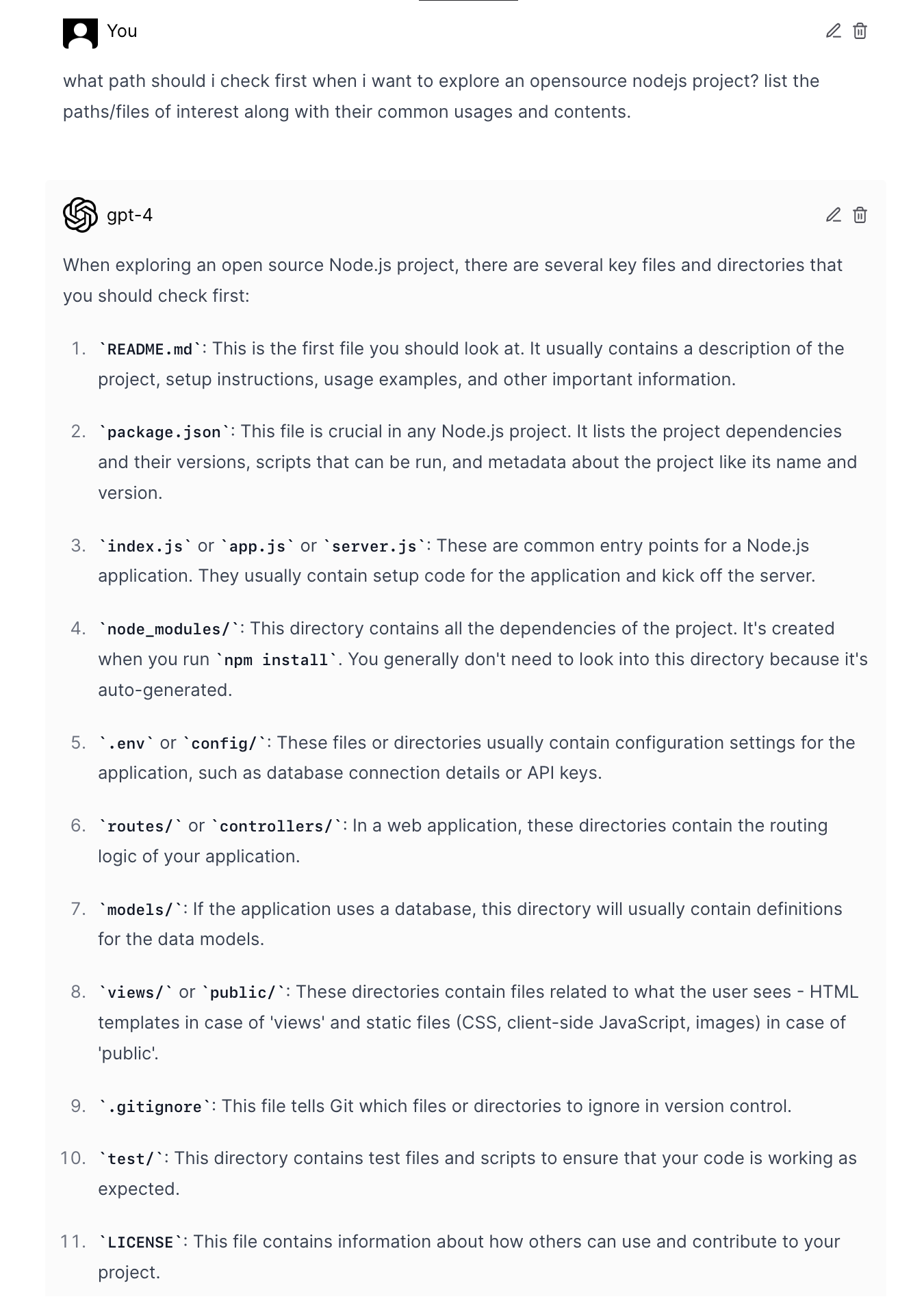
非开发者可以从代码中读些什么
A version of this article appears on Aug. 10, 2023 on SSPAI as a member-only post. Learn more or subscribe
The article is permitted to be self-archived in the version as originally submitted for publication on the author’s personal website under CC BY-NC 4.0 pursuant to § 5.2(b) of the SSPAI Fellowship Contributor Agreement.
引言
对于任何对技术和软件感兴趣的人来说,GitHub 都是绕不开的资源宝库。然而,在 GitHub 的使用方式上,人们却似乎以「懂」和「不懂」开发分为明显的两派:开发人员会除了会高频使用基于 git 版本管理功能,也更乐意打开他人项目的源代码一探究竟;而一般用户则大多纯粹把 GitHub 当作另一个「下载站」,很少涉足 release 以外的页面。
我很长时间以来就属于后一种情况。然而,随着时间的推移,我逐渐意识到这么做其实会错过很多有价值的信息,而「懂开发」也不是读代码不可逾越的前置条件。通过有选择地查看代码库,或能从他人的技法创意中撷取一叶,或能作为罕见提及的资料来源,或能解答帮助文档未能覆盖的使用困惑。
下面,我就从自己一个业余爱好者的视角出发,结合一些实际经历,聊聊我是如何从代码库中获取有用信息的。
基础技巧:语法速成和代码速查
怎样(凑合)看懂代码
在不懂代码的情况下看代码,听起来似乎很不自量力,但不要因为自己是「麻瓜」而妄自菲薄:其实,只要「硬着头皮」去代码中探索一番,就会发现多少还是能看懂一些的。
这是因为:
- 代码也是人写的,总归会考虑「人类易读」的需求。再加上开源项目一般没有必要为了保密而故意混淆,只要开发者不是跟自己过不去,就一定会让调用 API 的文件看起来像在调用 API,读取参数的函数看起来像是在读取参数。因此很多时候,即使只是路径、名称和注释这些字面内容就足以提供很多有用信息。
- 现代编程语言普遍有一些共通的语法特征,可以触类旁通。例如,「类 C」(C-like)编程语言就是一个很大的家族,其共同特征包括用分号表示语句终止、用大括号分隔代码块、用括号分隔参数,以及类似的算术和逻辑运算符等。因此,即使只了解其中一种语言、一部分语法,也可以套用在理解其他语言语法上。这就像很多学习了一两门欧洲语言的人,可以更快地学会同族的其他语言一样。
即使你对一种语言完全没有概念,也没必要直接放弃,大可以用 Learn X in Y minutes 这类资源来「临时抱佛脚」一番。站如其名,Learn X in Y minutes 的主要内容就是针对每种主流语言,提供一份既是指南又是演示、能在几分钟内看完的真实代码片段(不少还有中文版);但凡遇到陌生的语言,将相应的条目从头到尾读一遍,基本就「不会作诗也会吟」了。

类似的资源还包括 Codecademy 和 Devhints 上的「小抄」(cheatsheets)。这些速成教程当然不能代替更系统的学习,但对于本文讨论的目的——「不求甚解」地查阅一些代码,已经足够了。
当然,因为今年是 2023 年,你的另一个选择是随时使唤 GPT。作为一个最简单的套路,在提示词里先说 you’re an experienced programmer 树立「人设」,然后问问题,一般都能得到一个还不错的答复。如果要降低理解难度,还可以按需要求 explain in plain English 云云。(不用说,对于 AI 的准确性要始终保持警惕,应当把它的答复当作进一步检索的路线图,而不是可以直接采信的最终答案。)
怎样有效找到代码
解决了「怎么(凑合)看懂代码」,问题的另一部分是「怎么找到代码」。
这方面,尽管有必要警惕 GitHub「店大欺客」的垄断趋势,但客观上,它确实能提供别处没有的资源规模;前不久获得大幅翻新的代码搜索和浏览功能也确实提高了效率。可以不夸张地说,对于大多数需求,只要愿意花时间搜索,一般都能找到现成的方案或者思路启发。
具体的一些思路会在后文通过例子说明,这里先介绍一些通用的技巧:
用好搜索功能。正如在网页搜索时可以通过 intitle、insite 和 filetype 等搜索符事半功倍,GitHub 也支持一系列适用于代码搜索的语法。完整的语法可以阅读官方说明,这里重点推荐几个最实用的:
in:readme用于在自述文件(README)中搜索。大多数项目会在 README 中说明功能和用法,因此这个限定符特别适合根据需求寻找项目的阶段。org:<组织名称>用于在特定组织名下所有仓库中搜索。这是因为很多大型项目往往由组织名义管理,分成多个仓库分别开发(文档一般也单用一个仓库),也只有跨仓库查阅才能做到全面。pushed:>YYYY-MM-DD:用于限定在特定日期之后有更新的仓库中搜索。这是为了过滤掉一些年久失修的仓库,避免找到曾今流行、但因时间过久而失效的方案。
关注字面内容。对于我们这种业余部队来说,看懂所有代码是不现实的,但也没有必要。很多时候,如果暂时忽略代码中那些令人畏惧的符号和格式,仅仅关注关键词的字面含义,也足以提供很多信息。
例如,代码中函数和变量的名称通常都是采用某种驼峰风格拼写的英文短语,除了看起来有点费眼,理解门槛并不高。此外,比较规范的项目还会提供详尽的注释,这就更利于理解了。
借助目录定位。在代码中,动辄成百上千行的文件是很常见的,没有经验甚至都不知道从何看起。这时,不妨先看界面右侧的「符号窗格」(Symbol Panel)。
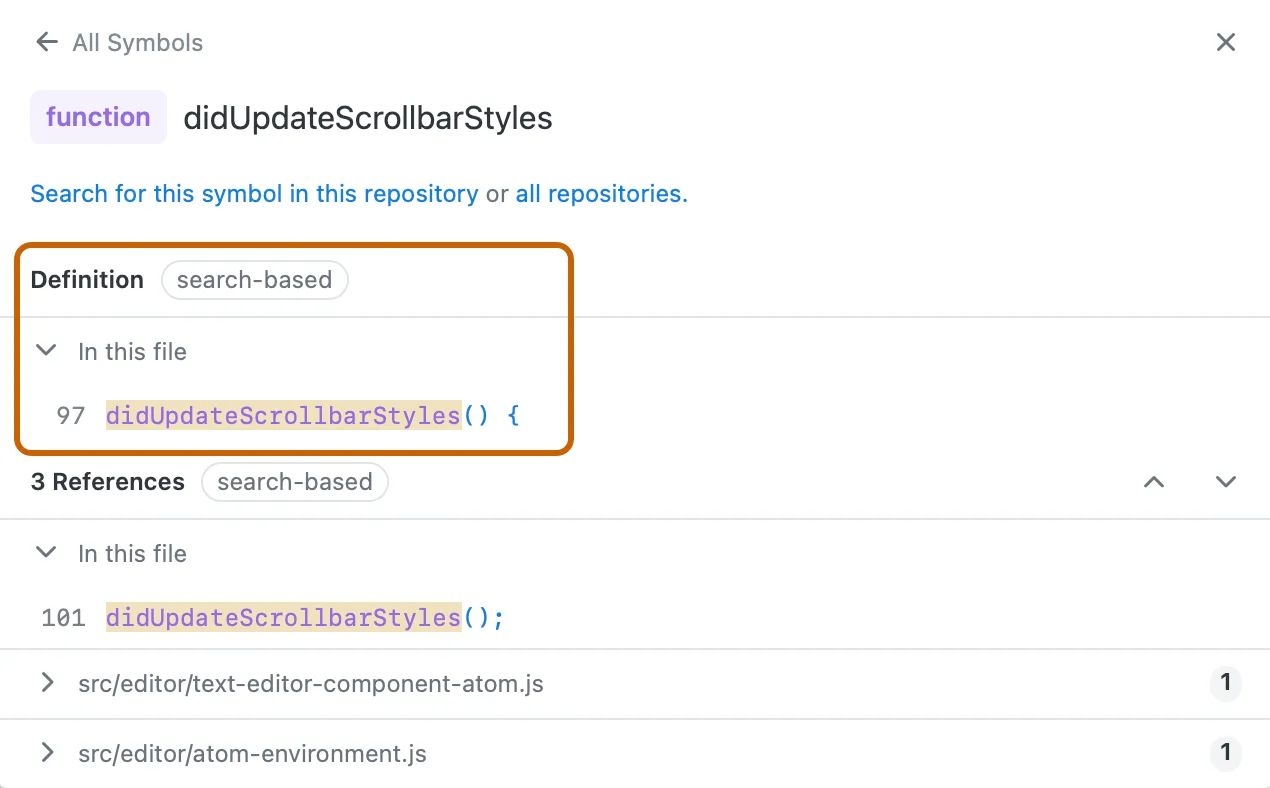
这里所谓的「符号」指的是各种有名称的组件(包括函数、方法、类、常量、变量、枚举型等),粗略地说就相当于代码的「目录」。因此,可以先通过目录项的名称猜出每段的大致功能,然后再小范围寻找有用信息。
多做交叉查询。某种意义上,程序都可以看成是一系列信息(存放在各种常量和变量)和流程(通过函数和方法来定义)的结合。实践中,出于化整为零、便于开发和维护的目的,这些信息和流程往往不会集中一处,而是散布在多个文件中,通过相互引用发挥作用。
因此在查阅代码时,应当建立来回跳转、交叉对比的习惯:如果发现一个与阅读目标比较相关的函数或者变量被调用,就去查阅它的定义,从而知道那部分代码在处理什么、以什么为「原料」来处理;反之亦然。(GitHub 中点击函数名称就可以在右侧显示引用或定义;变量的交叉查询则可以通过上述搜索符进行跨文件搜索。)
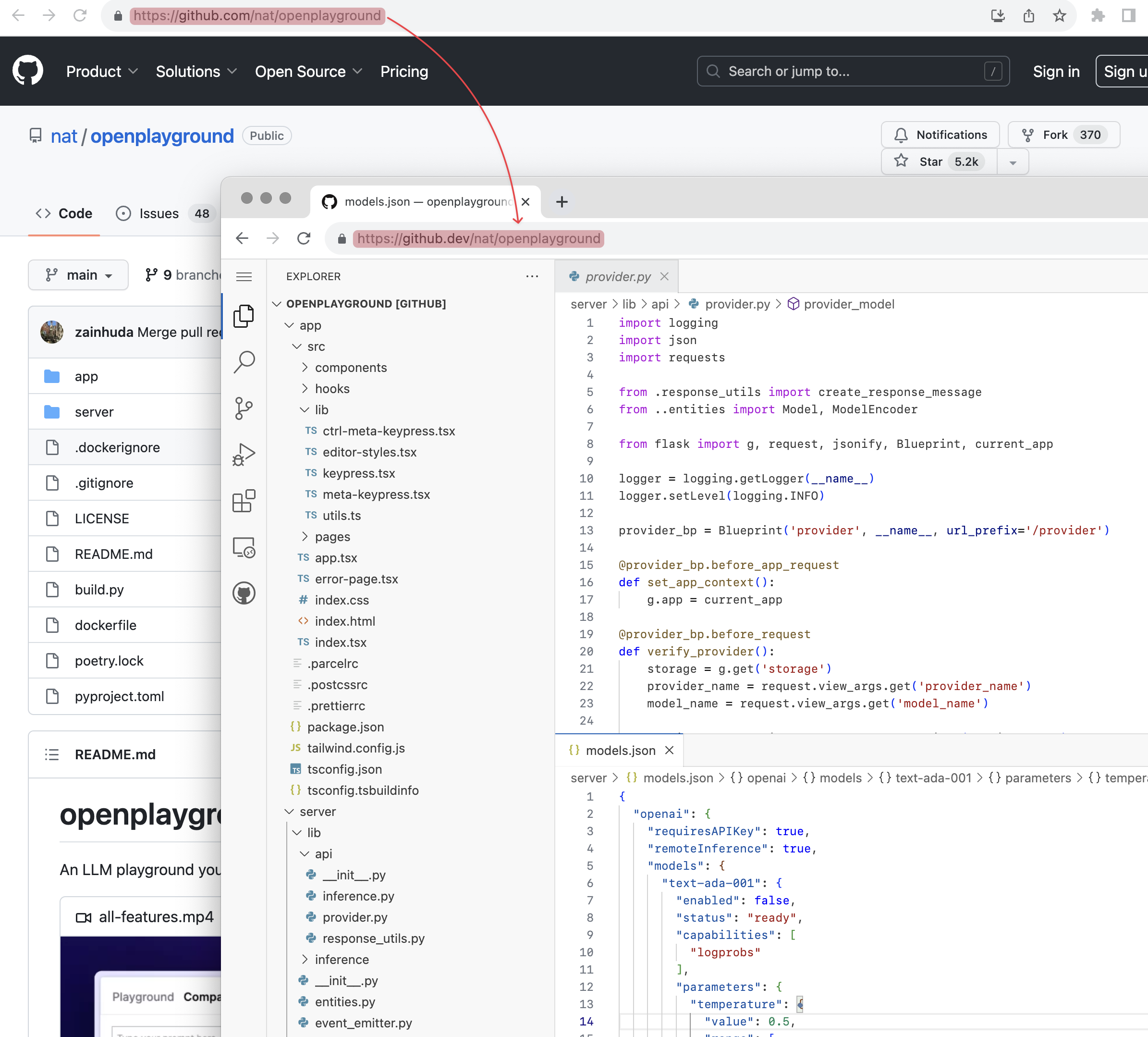
使用外部工具。最后,对于复杂的项目,还可以把网址中的 github.com 改成 github.dev 用网页版 VS Code 打开(或者使用句号快捷键 .),或者克隆仓库到本地,以便用上更丰富的搜索和 IDE 功能。
用法一:从代码库发现技巧提示
之所以强调不要只把 GitHub 当作「下载站」,主要有两方面的原因:首先,开源社区固然藏龙卧虎,但有时间、有耐心将技术和诀窍倾囊而授的只是少数,其「智慧」更多时候都埋藏在代码中,也只能通过阅读代码来挖掘。此外,开源代码虽然浩如烟海,要找到完全匹配自己需求的项目却也是「大海捞针」,但如果愿意将目光放宽到「大致合适」的项目,也不难通过组合和修改达成目标。
例 1.1:手动实现代码反映的思路
这方面,一种常见的情况是虽然找到了大致符合需求的项目,但其提供的使用方法或难以跟从、或已经失效、或相对于需求过于复杂。此时,就可以通过阅读代码,找出其中与需求最相关的部分,在理解原理的基础上通过更简单和熟悉的方式实现。
举个例子:前段时间,我在为某期《派早报》准备素材时,看到了「爱回收被列为苹果折抵换购供应商」的消息。根据网上信息找到爱回收的条款页面,发现确有其事,但问题是页面没有标注任何日期,无法确定到底是不是「新闻」;如果学其他媒体写一句「网友近日发现」,未免太过掉价。
有没有办法通过网页的其他特征来判断呢?用 webpage publish date estimate 之类的关键词检索了一通,果然发现了一个现成项目 CarbonDate(多么形象的名字)。
项目提供了一个网页版,但运行特别缓慢(至少当时是没成功),于是干脆直接看能否从代码中学到些思路。
先看 README 中的自述,得知 CarbonDate 采用了模块化的设计,每个模块用来尝试抓取网页的一种日期相关特征,最后取其中最早的日期作为推测的发布日期。据此,找到 modules 目录下一群以 cdGet 开头的文件逐个查看。
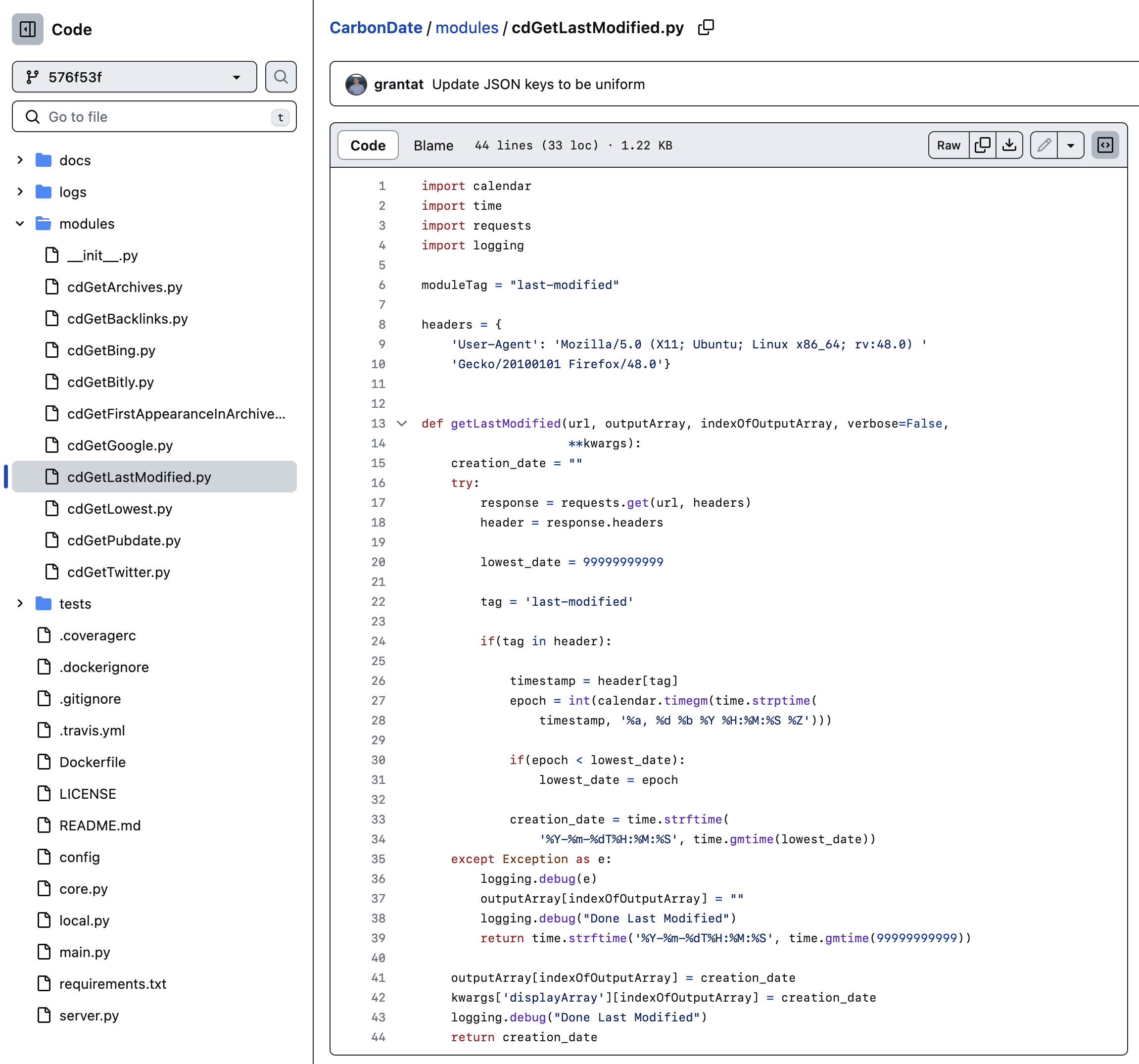
虽然我之前每本到手 Python 教程从来没有看完超过三分之一,但也足够连蒙带猜地根据文件名和函数名,了解它们都想做什么:(1) 查询目标在互联网存档服务中的最早存档日期;(2) 搜索包含目标网页链接的其他网页,再进一步查询后者的发布日期;(3) 抓取搜索引擎结果页条目标注的日期;(4) 查询目标网页被短链接服务收录的日期;(5) 查询目标网页文件的 HTTP 响应中的修改日期(last-modified);(6) 查询提及了目标网页链接的推文日期;以及 (7) 试图从目标网页的网址和 meta 头部信息中提取日期。总之,就是找出那些「只有网页发布后才会发生的事」。
显然,这其中大部分方法都是可以手工完成的。经过一番尝试,模仿上述第 5 种方法,用 curl -v 命令查看 HTTP 响应时,发现显示 last-modified 为 6 月 28 日(当时结果,后来又有过更新),相对于查询当天(7 月 1 日)确实还算「近日」,遂放心当作「新闻」收入。
类似地,你可能不一定愿意或有条件自建一个完整的 RSSHub,但这并不妨碍你从它更新频繁的路由目录代码中找出与自己关注网站相关的部分,然后直接借鉴其中的思路。
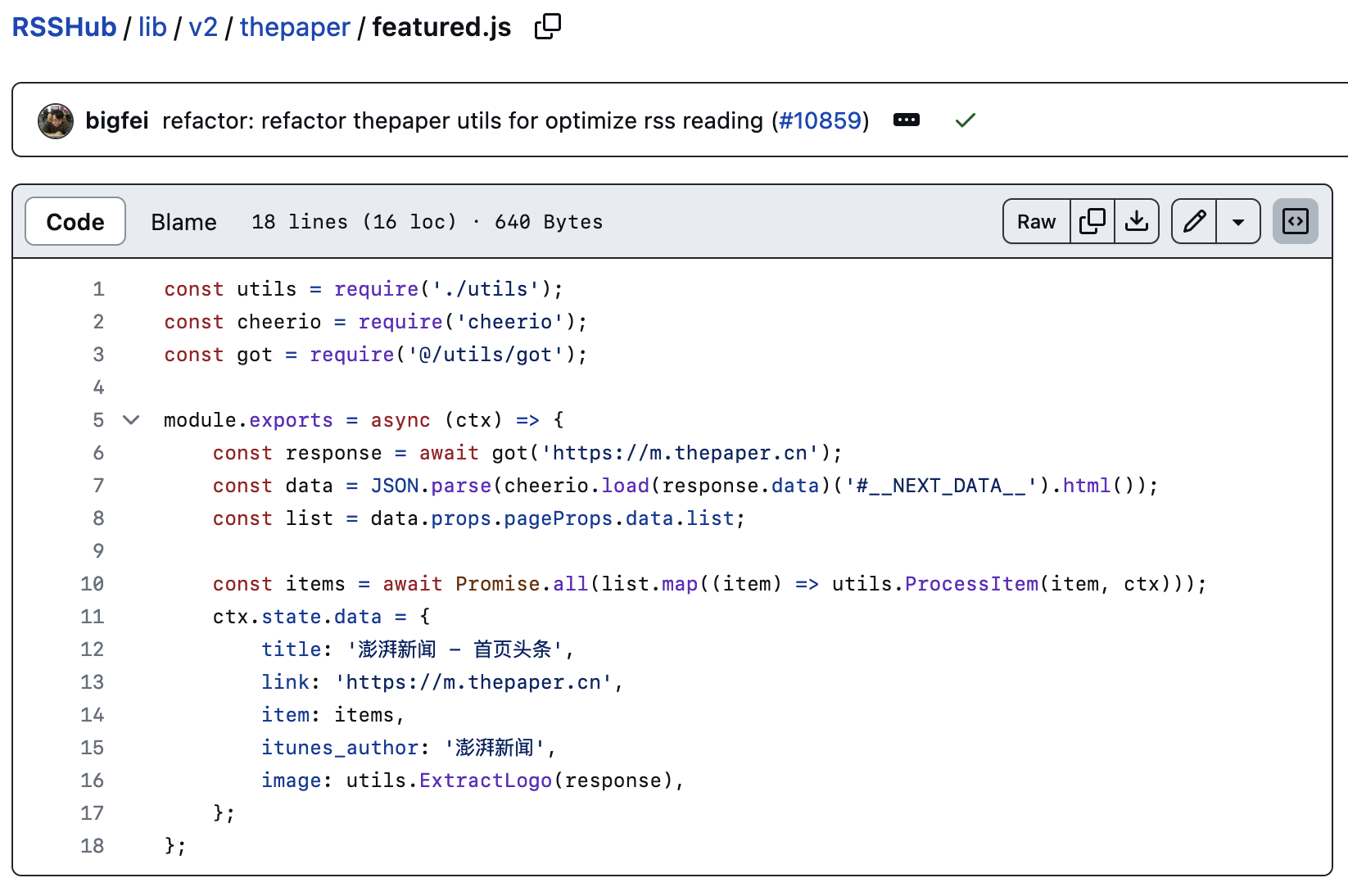
例如,从下图所示的代码中,不难看出澎湃新闻的「最新头条」可以通过提取移动版网页中 id 为 __NEXT_DATA__ 的元素内含的 JSON 数据获得。
例 1.2:从停止维护的脚本中打捞有用技巧
另一种值得检查代码库并有选择使用的情况是面对各种「一键脚本」时。
这些网上流传的安装脚本、优化脚本等虽然能带来很多方便,但无戒备地运行决非好习惯,因为:
- 这些脚本来自互联网上的陌生人。不要轻易相信陌生人。
- 即使有充分理由确定来源可以相信,这些脚本也很可能随着时间推移而失效和产生副作用。
因此,在运行「一键脚本」之前先检查一遍内容和维护状态,是作为用户最基本的谨慎。与此同时,即使认定脚本可以信任,全盘接受也未必是最佳的选择;即使发现脚本已经停止维护,也未必就要全盘舍弃。相反,我们可以在阅读代码的基础上,有选择地使用其中最适合实际情况的部分。
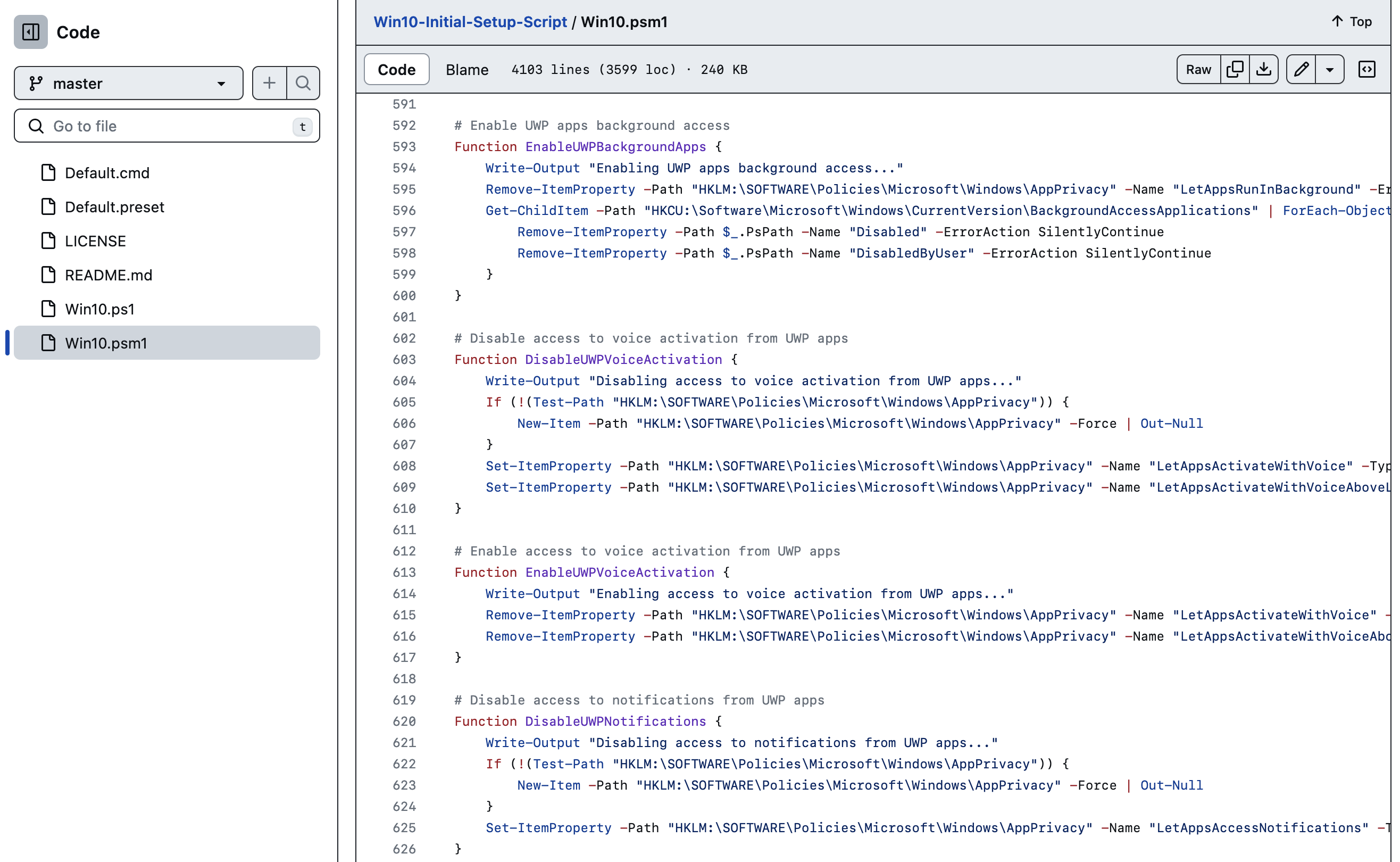
例如,Win10-Initial-Setup-Script 是前几年比较受欢迎的项目,功能是一键优化 Windows,帮助用户关闭不想要或反隐私的功能。但随着作者迁移平台,这个脚本已经停止维护,一些设置已经不再适用了(例如当时被视为牛皮癣的 Cortana 已经自行了断)。
即使如此,鉴于 Windows 的底层变化是非常缓慢的,即使是这个「废弃」的脚本中仍然有很多精华,可以当做一份完善的「笔记」来借鉴。事实上,即使你对于 PowerShell 没有什么了解,也不难根据这份注释完善的脚本找出相关设置项的原理——大多数是修改注册表键或停用服务——然后通过手动操作实现相同效果。这比起诉诸那些充斥着广告和虚假信息的「内容农场」,要靠谱得多。
用法二:将代码库作为资料来源
上文提到,程序代码中所包含的并不都是对「流程」的描述,还有很多纯粹属于描述或列举的「信息」。例如,一个旨在清理垃圾文件的程序,必然需要包含对于待清理路径的列举,以及何为「垃圾文件」的定义;一个需要调用特定 API 的程序,必然需要包含 API 的地址,以及对调用方法和返回数据结构的描述。
在代码库中,这些信息一般 (1) 作为常量存储,(2) 反映在函数的定义中,(3) 存为单独的数据文件(常用的格式如 JSON、CSV 和 XML 等),或者 (4) 写在注释部分。
作为非开发者,如果我们想了解某个软件或服务的 API 用法、数据集、文件列表等,可能未必能从公开渠道找到专门的文档或文章(特别是对于商业软件和服务);如果自己从头研究,又过于费力,且难以做到全面。而通过将代码库当作资料来源加以利用,往往就能又快又好地找到所需的信息。
例 2.1:通过包管理工具了解软件更新动态
一种典型例子就是 Homebrew、Scoop 等软件包管理工具。我们知道,这种工具的工作原理,就是由社区用户根据特定规范,将所收录软件的下载地址和安装流程写成配置文件。在安装时,包管理工具根据配置文件的指示下载软件及其依赖项,并完成相关的编译、文件复制、安装后配置等流程。
因此,这类包管理工具的配置文件仓库,实际上就可以看成一个集体维护的「软件目录」「安装指南」和「更新资讯站」,并且可能比大多数专做这类内容的网站——众所周知是广告木马重灾区——更靠谱、更专业、更及时。因此,即使我们因为各种考虑不直接用 Homebrew 和 Scoop 来安装和更新软件(例如希望保持系统精简、避免和软件自带的更新机制冲突等),也不妨将它们的配置文件仓库当作软件资讯的来源,常作查询。
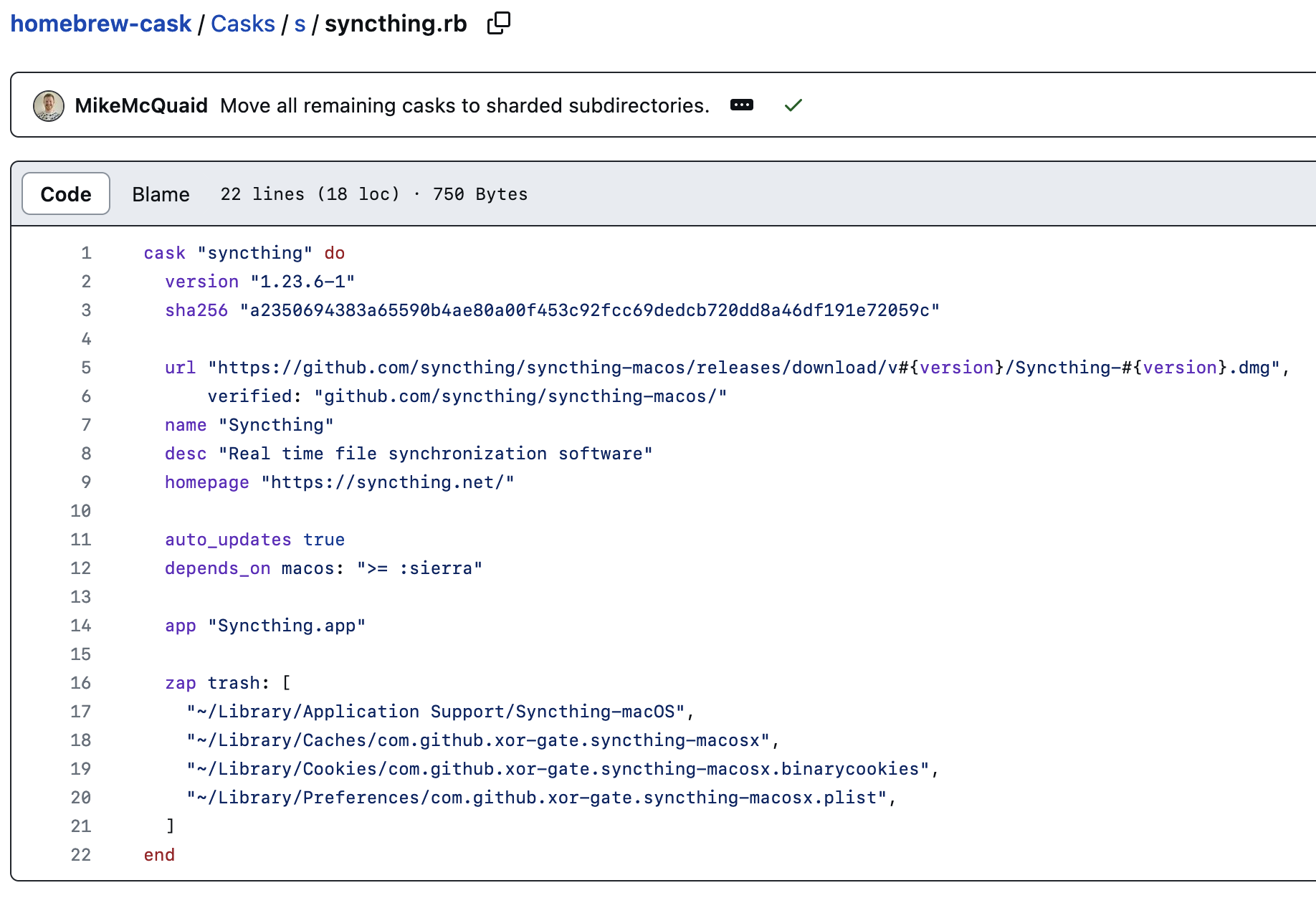
例如,在下图所示的 Syncthing 配置中,不仅可以直接找到下载地址,而且还能看到该软件都会在系统中留下哪些配置文件和临时文件。
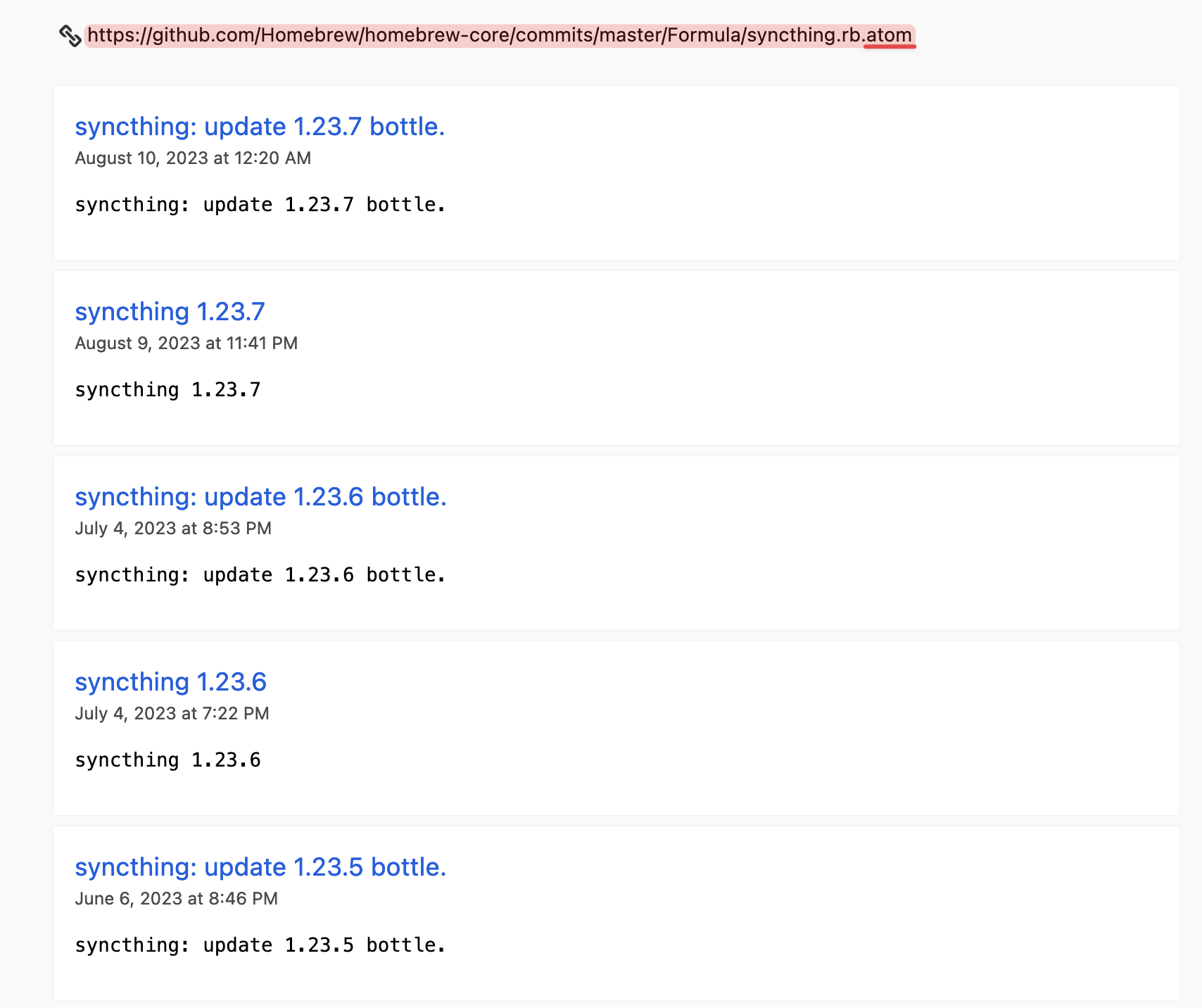
更好的是,你还可以在任何提交记录页面(无论是整个仓库还是特定目录或文件)的地址结尾加上 .atom 来获取订阅链接,这样相当于获得了一个更新通知服务:
例 2.2:通过官方插件逆推非公开 API
还有的时候,一些服务存在非公开的 API,但没有文档记载。此时,如果能找到使用了这些 API 的项目,其代码就能在很大程度上起到与文档相同的作用。
例如,Matter 是这两年新兴的「稍后读」应用之一,也有些不错的评价,但一个明显缺点是至今没有提供 API。经过一些检索发现,Matter 官方为 Obsidian 做了一个同步标注内容的插件,而这个插件是开源的。这就为找出 API 提供了突破口。
打开插件的代码库,简单扫视一番文件名,就可以直奔看起来与 API 最相关 api.js。它的开头几行基本就把答案给出了一大半:API 的地址是由几个常量拼合而成的,都以 https://api.getmatter.app/api/v11/ 开头。
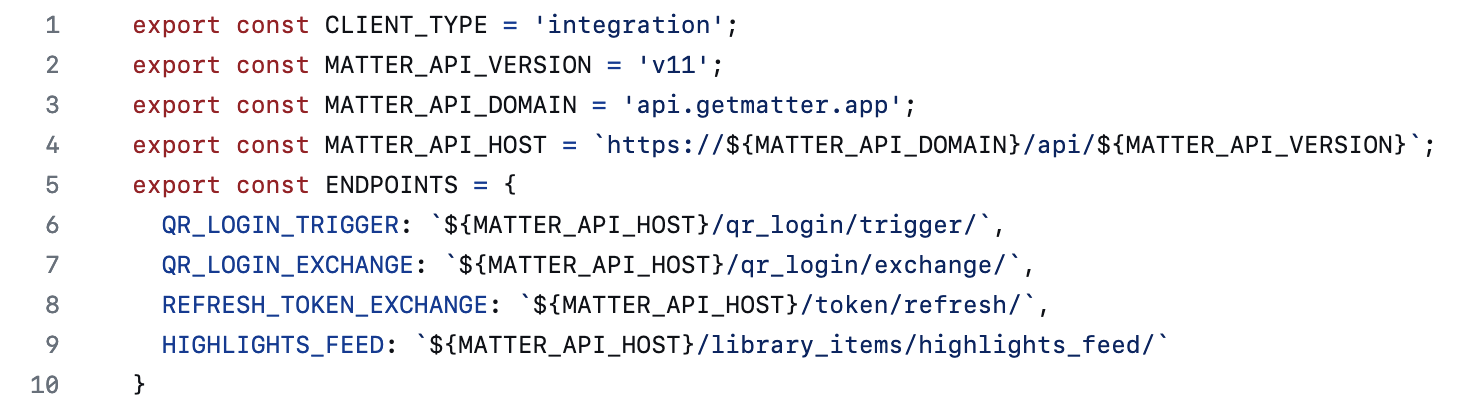
注意到代码中提到了 QR_LOGIN 等字样,结合插件主页的使用说明,可以合理推测:这个插件在首次使用时需要通过扫码验证获取某种 token,用于在后续调用时鉴权。
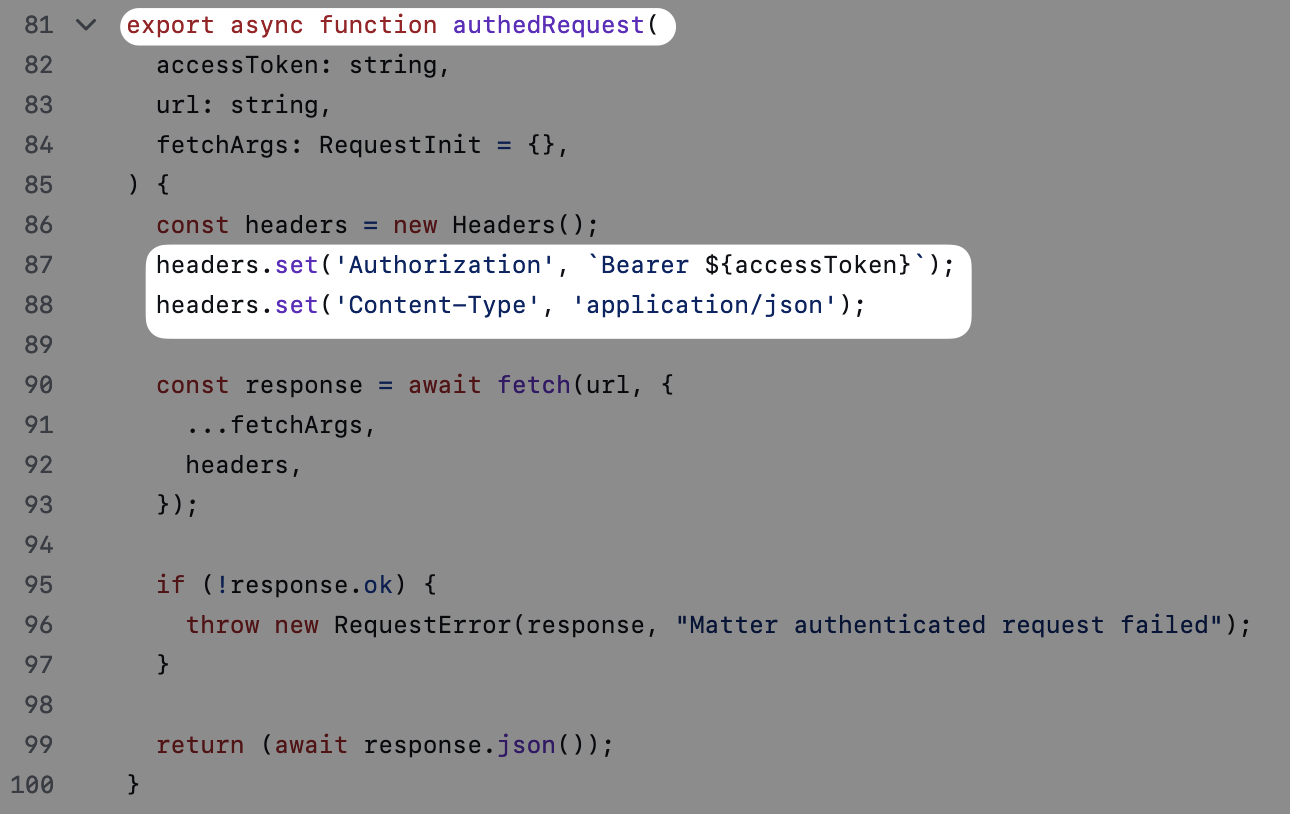
再根据前文提到的技巧,通过侧边栏的符号窗格了解文件结构。注意到这里有一个 authedRequest 函数,看名字大概就是用来发送 API 请求的。果然,其中不仅提到了发送请求需要使用的头部信息(headers),而且表明发送请求需要一个 accessToken 鉴权,这大概就是扫码验证后服务器会返回给插件的信息。
为了验证这个推测,再查看另一个看起来比较关键的 setting.ts 文件。仍然先看目录,可以发现一个 displaySetup 函数,估计是负责显示初始设置的。
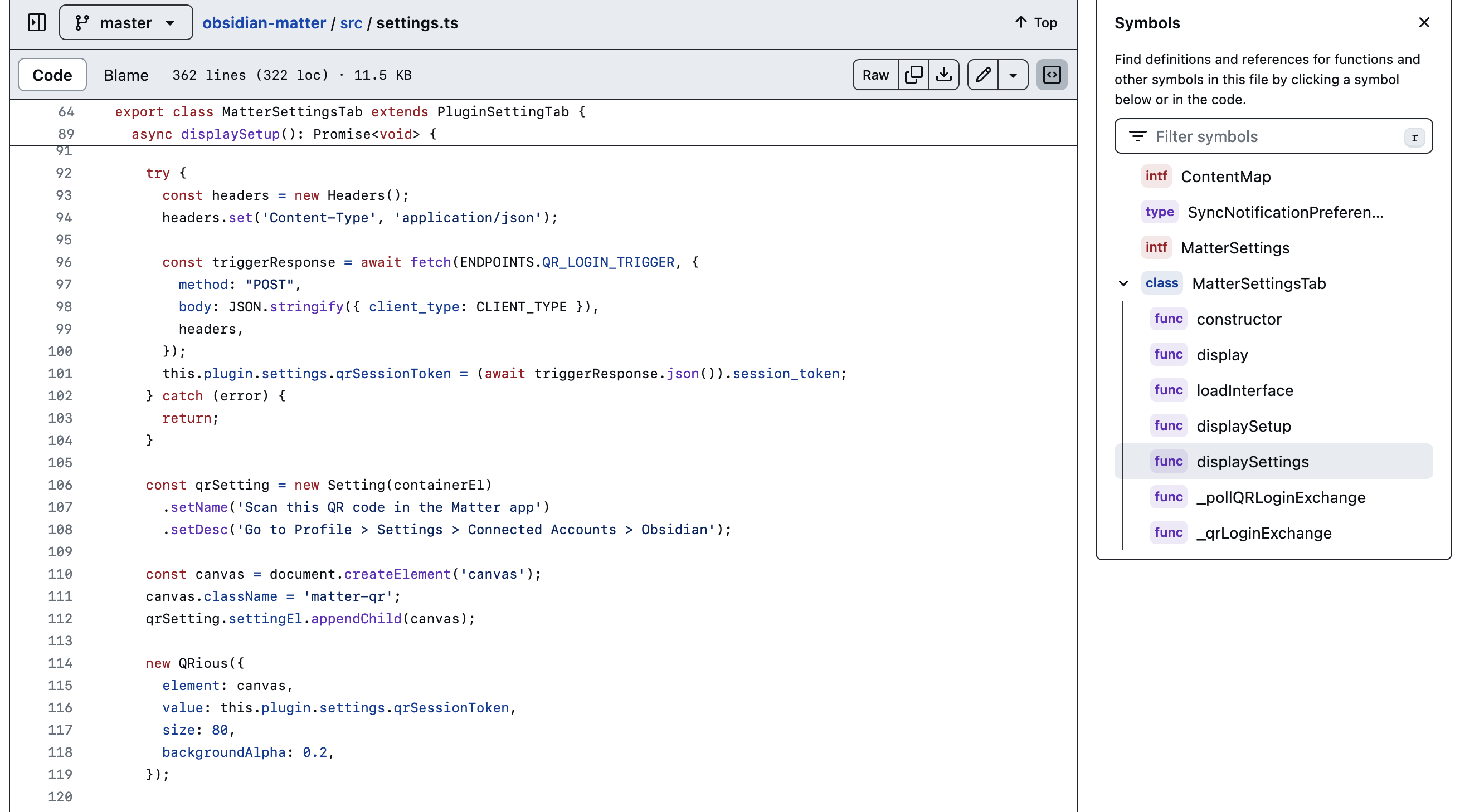
将其内容和刚才在 api.js 中发现的常量比对,大致就能猜出获取 token 的流程:
- 向
https://api.getmatter.app/api/v11/qr_login/trigger/发送一个 POST 请求,从返回值中获得一个临时的会话 token(session_token); - 把
session_token的内容做成二维码,然后用 Matter app 中的 Settings > Connected Accounts > Obsidian 功能扫码验证; - 以
session_token作为请求体,向https://api.getmatter.app/api/v11/qr_login/exchange/发送请求,就可以获得真正的 API token。
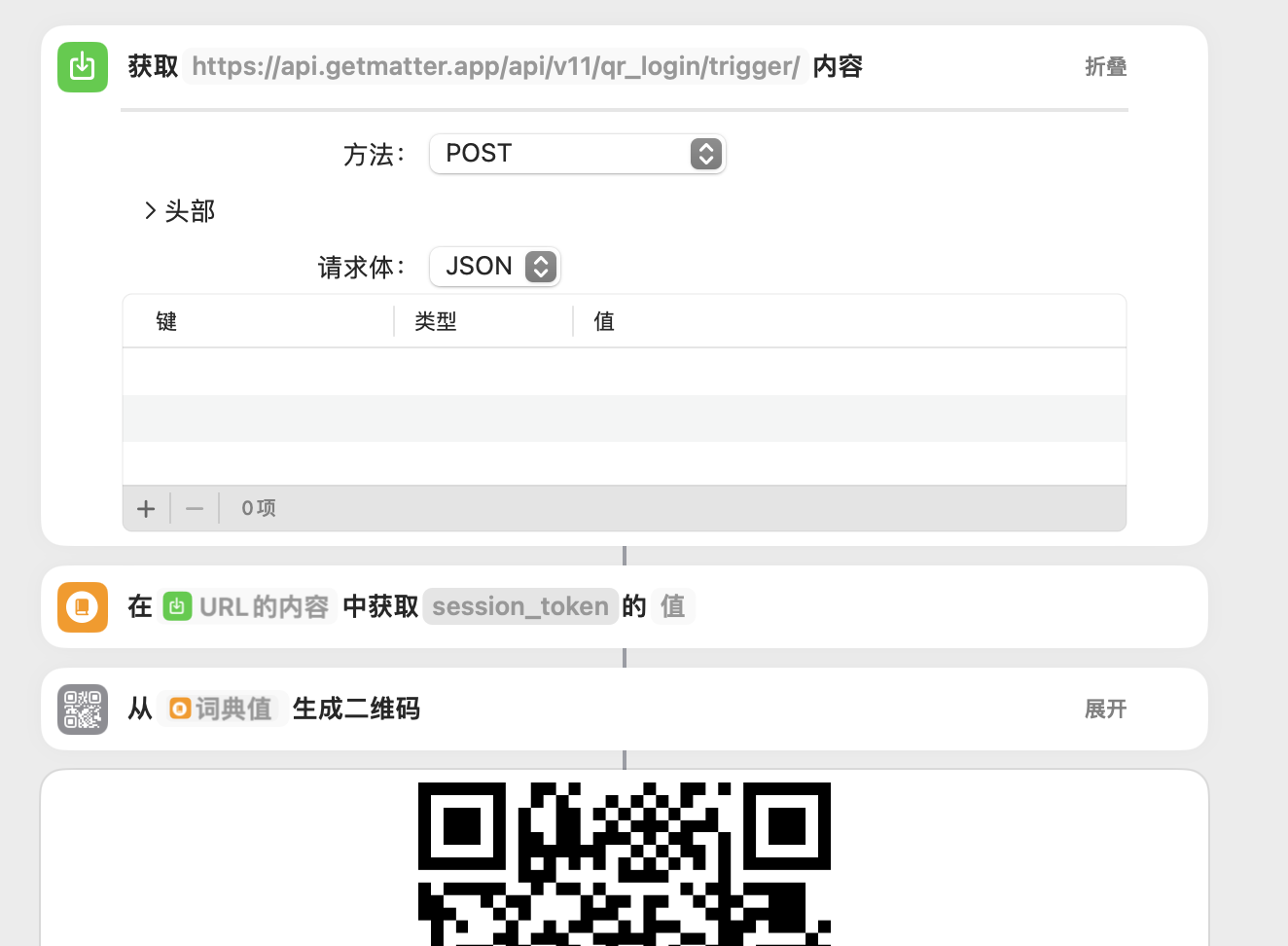
如果你擅长使用 curl 之类的 HTTP 调试工具,大概就不需要我继续教了。但即使只是掌握快捷指令这个新手友好工具,它的功能也足以「模拟」上述流程:
最后,在负责主要功能的 main.js 中,可以看到对于 API 响应结构的描述:
- 每篇文章对应
feed数组中的一个对象,该对象中的title和url键分别是标题和链接;
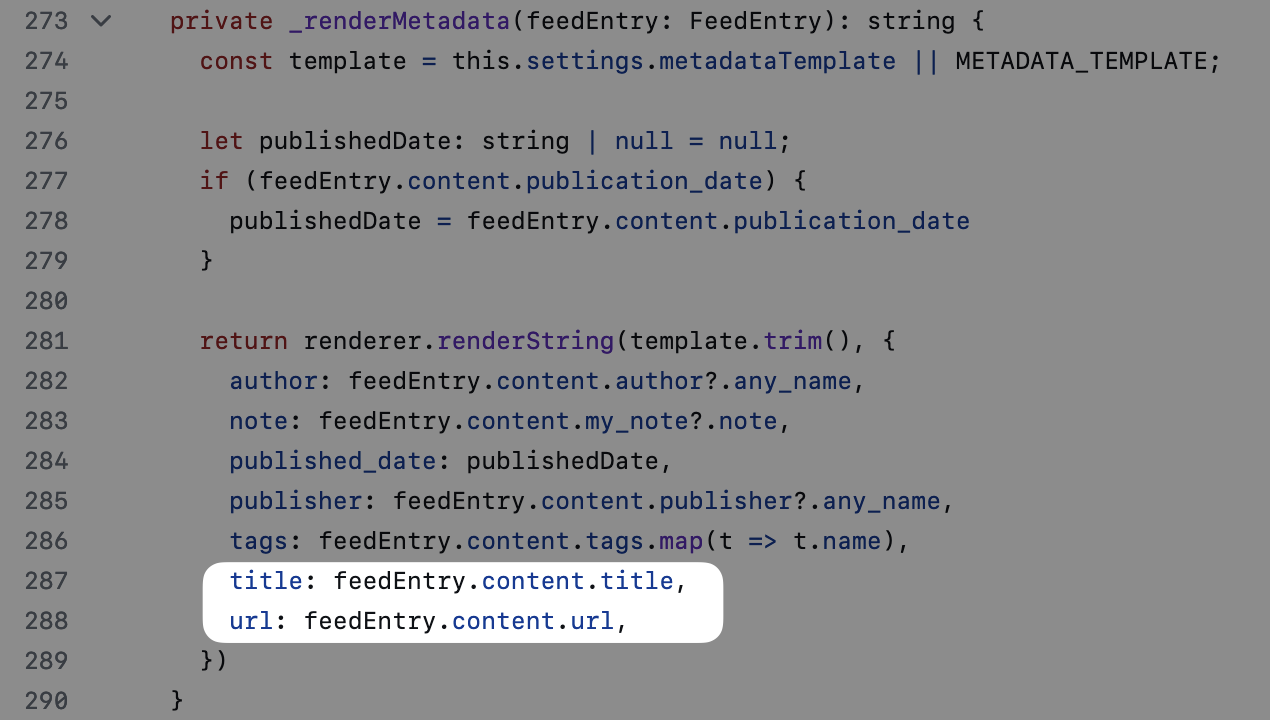
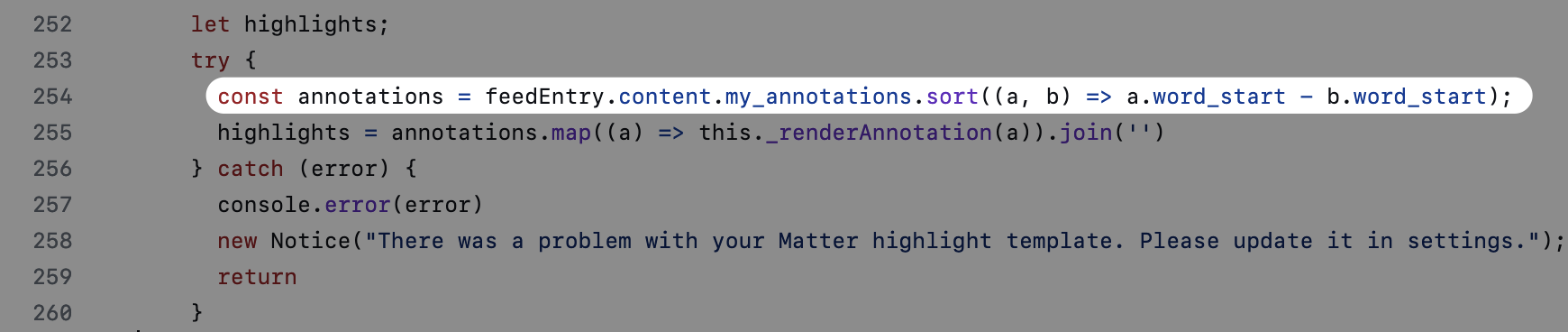
- 每条高亮文本存放在
my_annotations数组下的text键中,并且可以通过word_start得知其在文中的位置。
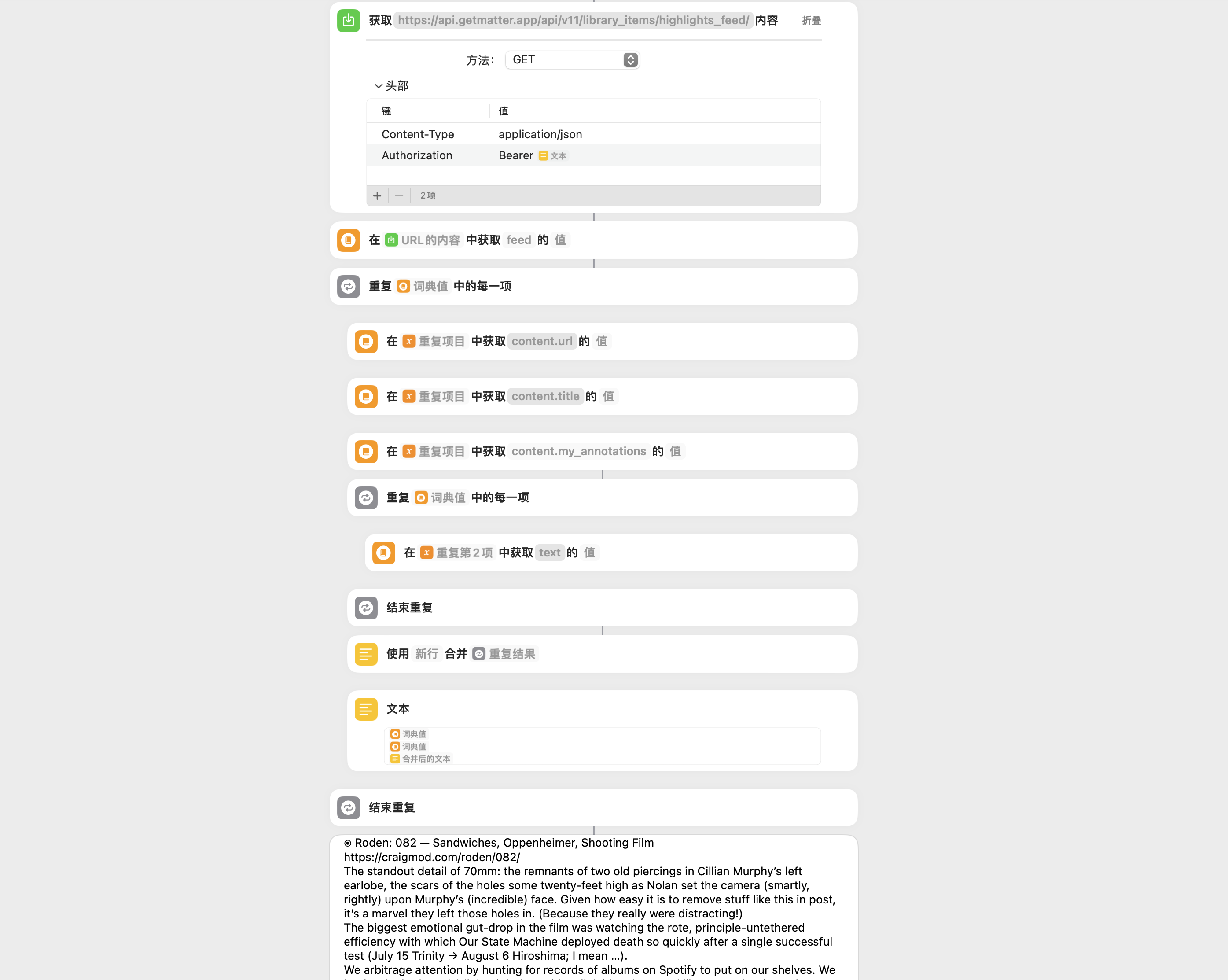
将这些信息整合起来,用其他自动化工具导出 Matter 批注就很简单了。下图演示了一种用快捷指令来导出的简易流程:
用法三:向代码库寻求疑难解答
尽管完善的文档是优秀软件项目的标志之一,但世事难全,很多时候,选择开源软件就意味着要承担一些「自己给自己当客服」的成本。问题是,在文档语焉不详、开发者也不一定有空解答的情况下,还有谁可以求助呢?
答案也是代码库。一般来说,在对功能原理和用法有疑问的情况下,可以界面上的标签文本、报错文本等作为关键词搜索,往往就能找到相关的代码。需要注意的是,对于规模比较大的项目,特别是支持多语言的软件,其界面文本和实际功能代码一般是分开存储的。这种情况下,就需要通过开头部分介绍的交叉搜索思路,在同项目或同组织的代码中比对。
例 3.1:寻求功能的原理解释
例如,我长期以来都使用自建的 RSS 阅读服务,这两年特别喜欢的是简洁但不失强大的 Miniflux。它有一项在很多商业服务中收取高价的功能:可以为订阅的资讯源设置黑白名单规则,按需过滤。
但是,尽管这个功能有文档说明,但看过之后还是有一些疑问,特别是:
- 文档说明过滤规则支持正则表达式,但正则表达式的变种过多,具体支持哪些语法?
- 如果一条资讯同时被黑白名单规则命中,是会被保留还是过滤?
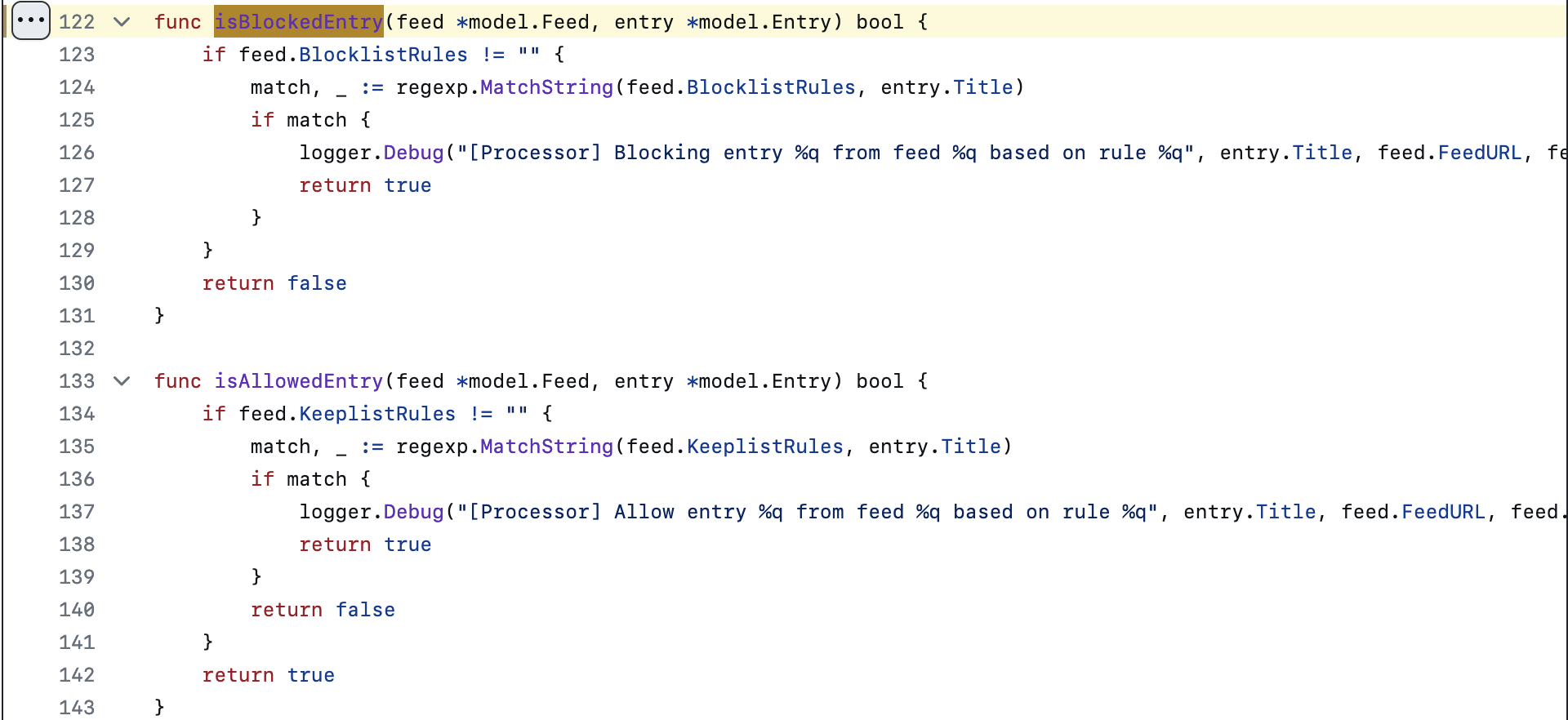
为此,我以 filter 为关键词在代码库中检索,在靠前的位置看到了 processor.go 这个文件。根据注释知道,ProcessFeedEntries 就是负责处理黑白名单的函数。
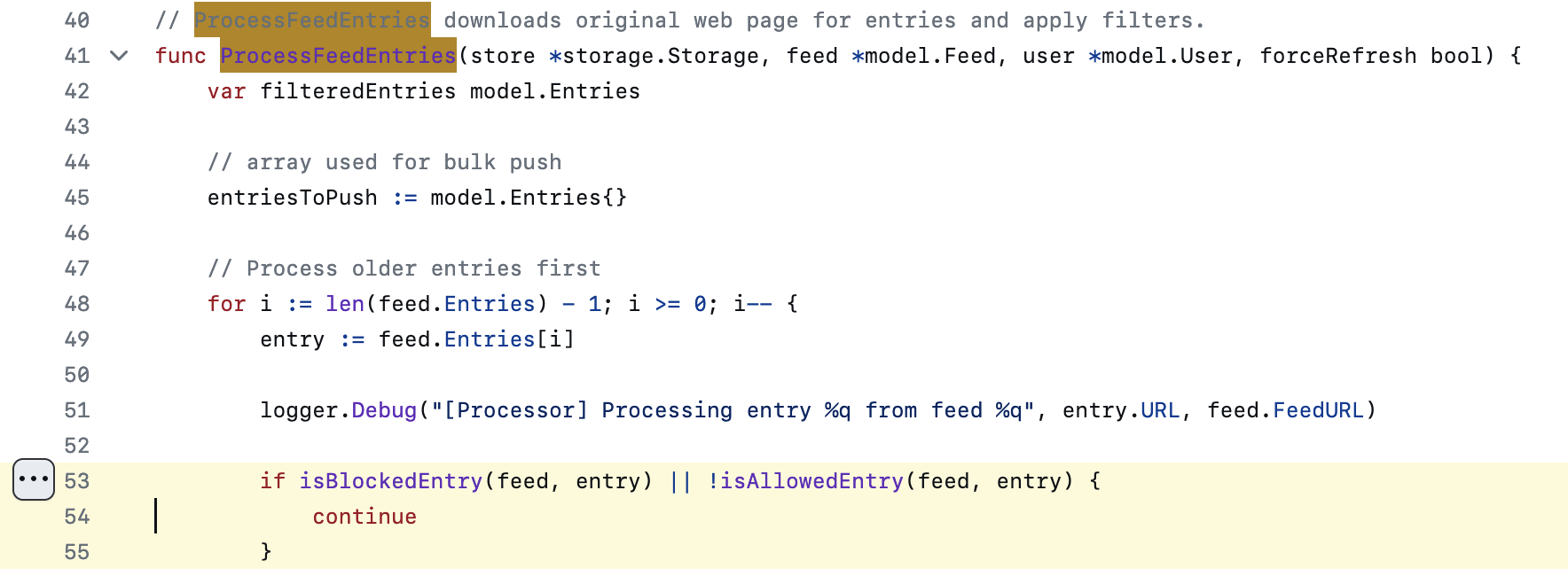
Go 语言我是看不懂的,但发挥大无畏的瞎猜精神,硬着头皮观察 ProcessFeedEntries 的内容,凭借朴素的想象力,大概能看出其处理逻辑是:当且仅当一条资讯 (a) 被黑名单命中,或者 (b) 没有被白名单命中,就停止处理,否则正常放行。这就回答了上述第二个问题:由于这个逻辑是「或」的关系,因此只要被黑名单命中,就会满足 (a),导致被过滤,即时同时被白名单命中也没有区别。
再点击这个逻辑中引用的 isBlockedEntry 和 isAllowedEntry 函数查看其定义,发现两者都直接使用了 Go 语言标准库中的 regexp。
于是查阅 Go 的相关文档,就完全解答了第一个问题:这里使用的是 RE2 语法,属于经典风格 PCRE 的子集,但有意不支持向前/向后断言等扩展语法。(开发者后来已经根据用户建议在文档中补充了相关链接。)
以此为基础,再使用过滤功能就能有的放矢了。
例 3.2:了解设置项的正确格式
另一种常见的疑问是不知道软件的设置该填什么、用什么格式填。这种问题也可以通过看代码得到最权威准确的解答。
例如,我前段时间在 Windows 上配置 Firefox 的字体时,遇到了一个典型的回退错误问题:如果在图形界面设置中为中文网页设置非默认等宽字体,网页上代码部分中的汉字就会变成用衬线字体显示,看起来非常不协调。
WTF
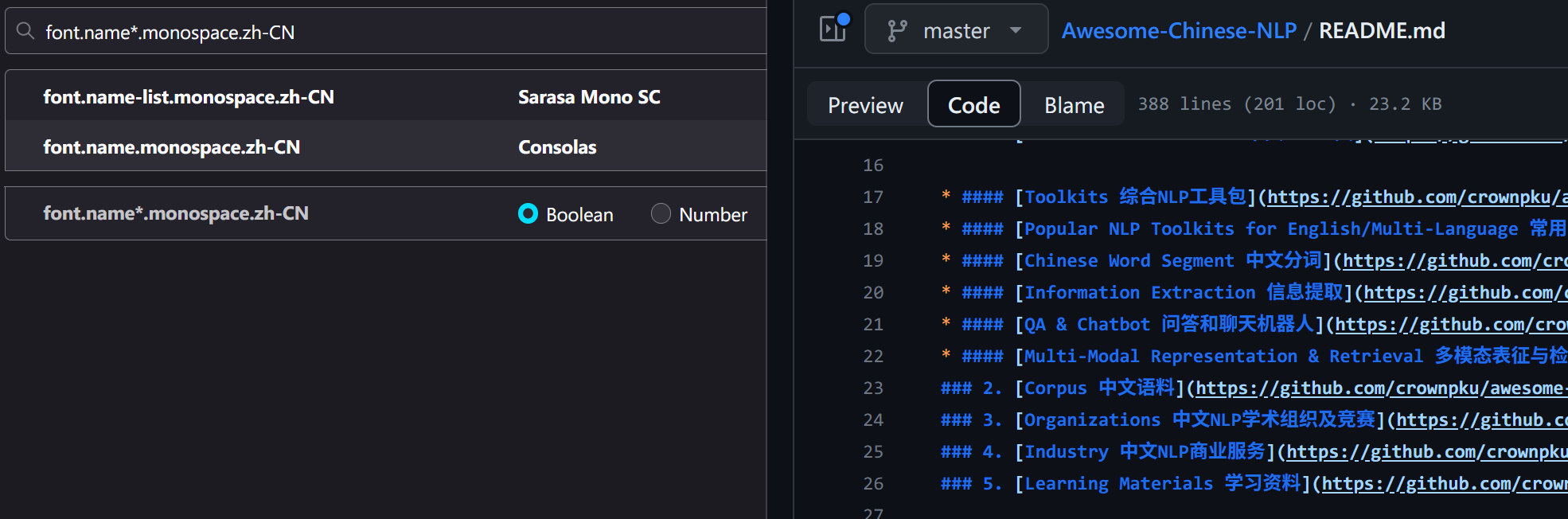
经过初步检索,我得知可以通过在 about:config 页面设置 font.name-list.[generic].[langGroup] 来修改默认的回退顺序。例如,font.name-list.monospace.zh-CN 指的就是简体中文语言下等宽字体的回退顺序。但问题是,这个设置应该按什么格式填,和设置中的字体选单又有什么关系呢?
设置界面和搜索结果都不能提供满意的答案。于是,我在 Firefox 的代码仓库 以 font.name-list 为关键词搜索。虽然对 C++ 一窍不通,但连蒙带猜,还是很快在排名靠前的几个文件中看到了一些有用信息:
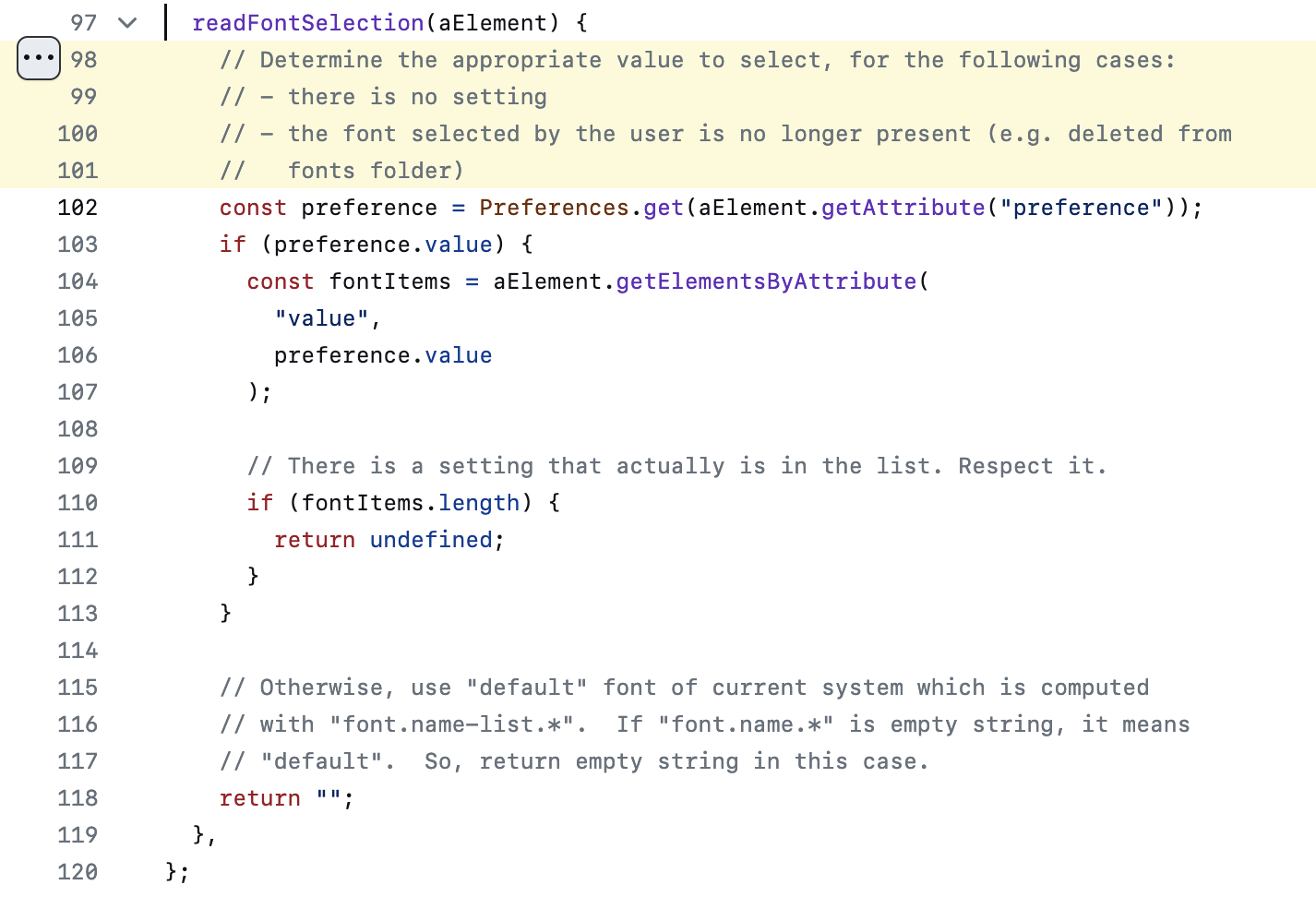
toolkit/mozapps/preferences/fontbuilder.js中readFontSelection函数的内容和注释表明,设置中的字体选单对应的是font.name.*,优先适用。如果没有设置,才会按照font.name-list.*来决定字体。
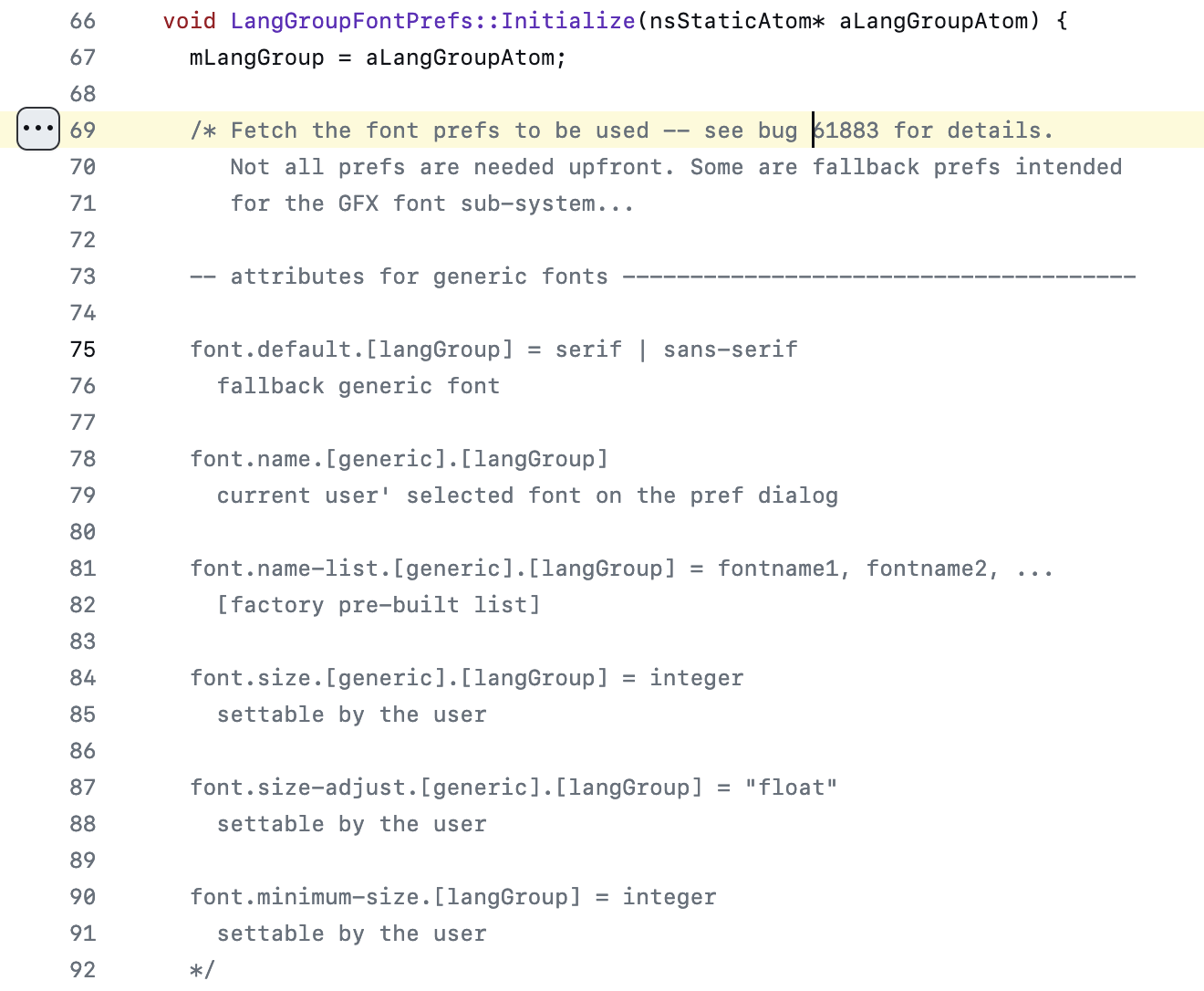
layout/base/StaticPresData.cpp中的注释表明,这个设置应该以逗号分隔的列表格式填写,并且指向了与其相关的、一个有二十多年历史的 Bugzilla 讨论(#61883,如果不是注释我下辈子可能也想不到看这里);其中,一些事无巨细的解答印证了上面的结论,并提供了更多历史背景。
以此作铺垫,设置方法就很明确了:在 font.name.monospace.zh-CN 填写英文等宽字体,在 font.name-list.monospace.zh-CN 中填写中文回退字体,就解决了问题。
结语
受限于个人水平和视野,上文给出的例子肯定不全面,也未必特别有代表性,仅供抛砖引玉,难免见笑于行家,相信读者能探索出更多有趣的「读代码」方式。
此外,篇幅所限,文中对于探索过程的描述有所省略,实际情况有时会更曲折。但相信读者尝试一番后也会同意,「硬着头皮」在代码库中摸索,固然需要一些时间和耐心,但也因此更添几分解谜游戏的趣味,探索的过程和解决问题同样有意义。在我看来,这才是开源软件更大的魅力所在。