网页直接标注:工具比较与使用技巧
A version of this article appears on Aug. 25, 2023 on SSPAI as a member-only post. Learn more or subscribe
The article is permitted to be self-archived in the version as originally submitted for publication on the author’s personal website under CC BY-NC 4.0 pursuant to § 5.2(b) of the SSPAI Fellowship Contributor Agreement.
与先抓取再标注的常见功能相比,「在原始网页上直接标注」效率更高、适用面更广,在不少场合是更有意义的选择。本文分析和比较了 Hypothesis、Raindrop 和 Readwise Reader 三款具有直接标注功能的产品。
如果你用过任何「稍后读」类工具,一定不会对「标注」(annotation)功能陌生。但凡以「全功能」为志向的此类产品,都会不同程度地支持高亮、评论等标注功能。不过,大多稍后读工具所支持的,都是在经过抓取和解析的「清洁版」上标注。
这当然有其好处,例如利于专注、不受原网页断链影响等,但相应的缺点就是不够方便和通用。比如,有时只是想快速标记个别片段,如果搬出稍后读工具先抓取、跳转再标注,就显得过于繁琐。又比如,有的网页的设计使其很难被抓取,或者其内容本来就不属于文章范畴,先保存再标注的方法也就不灵了。
在这些场合,「在原始网页上直接标注」就是更有意义的选择。与先抓取再标注相比,直接标注效率更高、适用面更广;摩擦力小了,人就更有动力多做标注,避免出现那种明知有用却就是懒得动手摘录的情况。
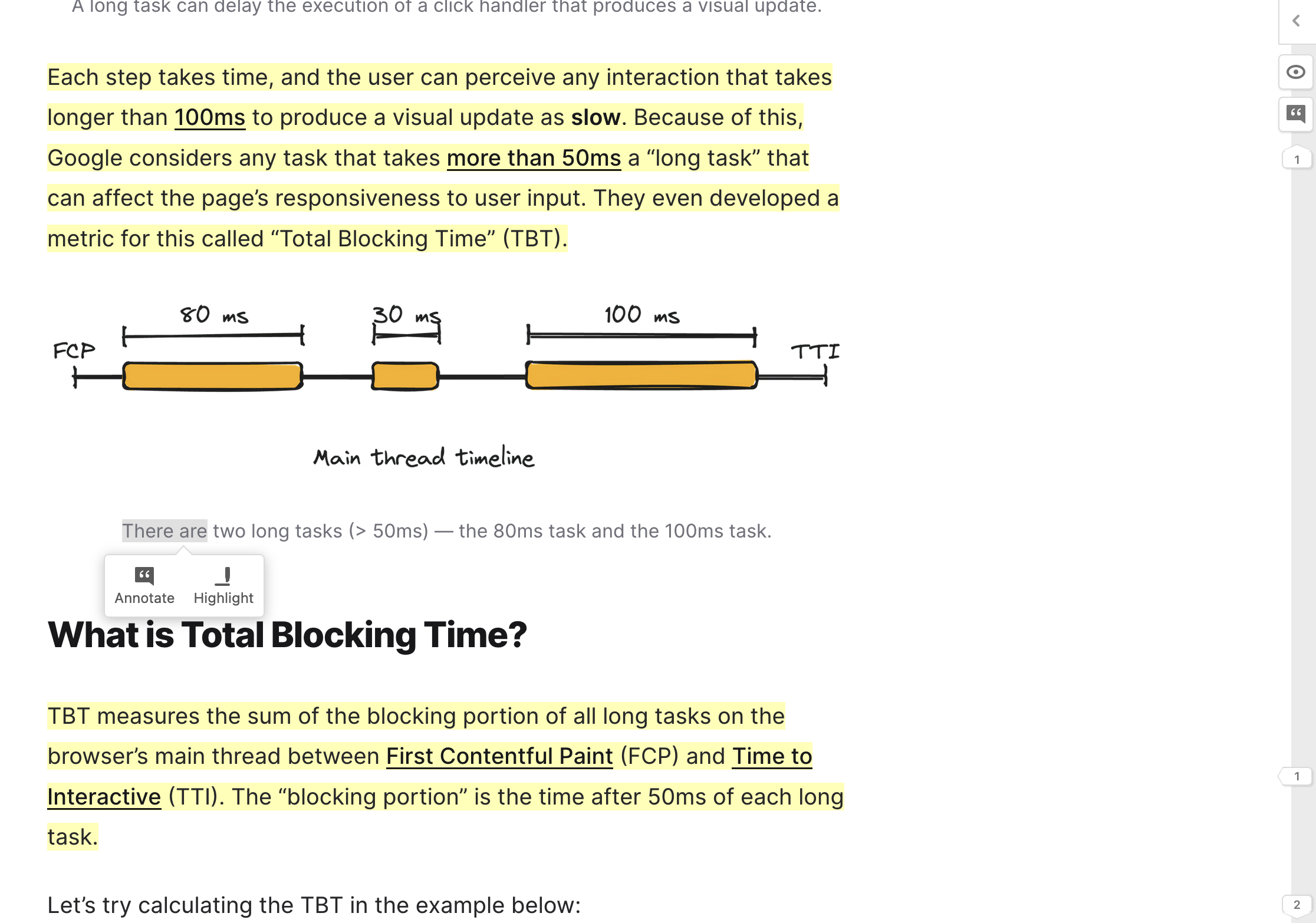
用 Hypothesis 在网页上直接标注
实际上,直接标注功能也算是互联网早期倡导者的一项未竟之志。在他们看来,互联网作为一张知识之网,本就应比实体文档更便于标注和交叉检索。「互联网之父」Tim Berners-Lee 在九十年代的一篇提案中就主张,超文本系统应当支持用户为批注和「节点」(一个信息单元,例如文件或文章)添加个人标注。早期浏览器 Mosaic 曾以直接标注为重点功能之一,Marc Andreessen 本人也大力推广(其投资的 Genius 是为数不多自带标注功能的网站之一)。
不仅如此,万维网联盟(W3C)还曾经成立过专门的工作组,开展网页标注的标准制定工作,并在 2017 年就形成了一套正式推荐标准。根据这套标准,一条规范意义上的「标注」包含标注内容(body)、标注对象(target),以及对两者之间关系的说明。W3C 还研究了如何通过一系列「选择器」(selector)定位标注对象,如何通过一系列「状态」(state)信息识别不同版本和格式的标注对象等问题。
遗憾的是,或许因为技术难度大、商业前景小等综合因素,网页直接标注始终没能流行起来——维基百科上列举着大量已经扑街的产品。

历史上(失败)的网页标注产品(来源:Hypothesis)
两年多前,我通过一款叫做 Hypothesis 的工具接触了网页标注,并写过一篇文章介绍心得。在那之后,我一直持续使用和关注这类工具。尽管属于一个受关注较少的需求,近两年确实也能看到陆续有新的工具支持了网页直接标注。
根据尝试和比较,我认为其中相对优秀、发展前景较好的是 Raindrop 和 Readwise Reader。与 Hypothesis 相比,它们也各有侧重和优劣,值得研究和比较一番。如果你也有兴趣尝试直接标注网页的方法,希望本文能对你的选择有所帮助。
下表是从各个关键维度对三款工具的简要比较,后文则会做细化评论,并提供一些自己发现的使用技巧。
| 服务 | Hypothesis | Read w | Raindrop |
|---|---|---|---|
| 标注稳固性 | 最好(据原文内容、文本偏移量和 XPath 定位) | 较好(据原文内容、文本偏移量和 :nth-child() 定位) | 一般(仅据原文内容定位) |
| 网页兼容性 | 一般 | 较好 | 较好 |
| 摘录富文本格式 | 不支持 | 支持 | 不支持 |
| 评论富文本格式 | 支持 | 支持 | 不支持 |
| 桌面端支持 | 一般(JavaScript bookmarklet) | 最好(浏览器插件或 web app) | 较好(浏览器插件或 web app) |
| 移动端支持 | 较差(JavaScript bookmarklet) | 一般(iOS 或 Android app) | 尚可(iOS app、iOS Safari 插件或 Android app) |
| 数据导出 | 仅 API | 应用内复制(markdown)或 API | 应用内复制(纯文本或 markdown)或 API |
| API 保存 | 支持 | 暂不支持 | 支持 |
| 保存原始内容 | 不支持 | 支持(正文部分) | 支持(原页面) |
| 价格 | 免费(开源) | $96/年(有提价计划) | |
| 中国用户可要求折扣至 $48/年 | 高亮标注等基本功能免费 | ||
| 文本标注等高级功能 $28/年 |
Hypothesis:严谨但难用的「学术派」
对于一款标注工具来说,最关键的技术要素一定是「如何记录标注信息」,这将在很大程度上决定着它的使用体验。而在网页上直接标注的一大技术难点,就是第三方的网页内容不受用户控制,随时可能发生改版和修订,导致难以找回原先的标注位置。
Hypothesis 主要面向教育市场客户,而它的标注技术也可谓「教科书级」,基本就是照着 W3C 的标准来实现的。尽管在本文对比的三款工具中出现最早,它的标注定位能力至今仍然是未被超越的。
我在之前的文章中已经详细介绍过 Hypothesis 的技术原理,有兴趣可以翻看,这里只做一快速回顾。简单来说,Hypothesis 实现了一套称为「模糊锚定」的方案,同时使用三种方法存储标注文本在页面上的位置:
- 范围选择器
RangeSelector:记录标注文本所属 HTML 元素在网页中的位置,以 XPath 表示; - 文本位置选择器
TextPositionSelector:记录标注文本的起始和结尾在全部文本内容中的位置,以字符数偏移量表示; - 文本引用选择器
TextQuoteSelector,记录标注文本的原始内容以及其前后相邻各 32 个字符,以字符串表示。

当用户重新打开一个之前标注过的网页时,Hypothesis 会依次使用上述选择器,按照从精确到模糊的原则,尝试找回标注部分的位置。由于记录信息的冗余量足够多,Hypothesis 表现出极好的容错能力,即使原网页的结构、版式甚至内容顺序发生相当显著的变化,仍然能有很大概率成功定位。
可惜的是,正如很多开源工具一样,Hypothesis 的美好之处主要停留在技术底层,上层的用户体验则仅仅以「勉强能用」为追求。如今,这个工具的易用性跟我当年前发现它时相比,几乎没有任何改进:
- 使用繁琐。每次必须要手动点击一个专用的小书签才能显示工具栏和标注历史(仅 Chrome 有插件,但仅仅是给相同代码打了个包,并无太多额外便利)。兼容性也比较一般,在一些版式复杂网页上运行时,经常无法正常选择和标注,或者干扰网页原有功能和布局。
- 无移动端。虽然小书签理论上也可以在移动端浏览器上运行,但因为并未针对触摸操作优化过,真正能用的几率大概只有五成。
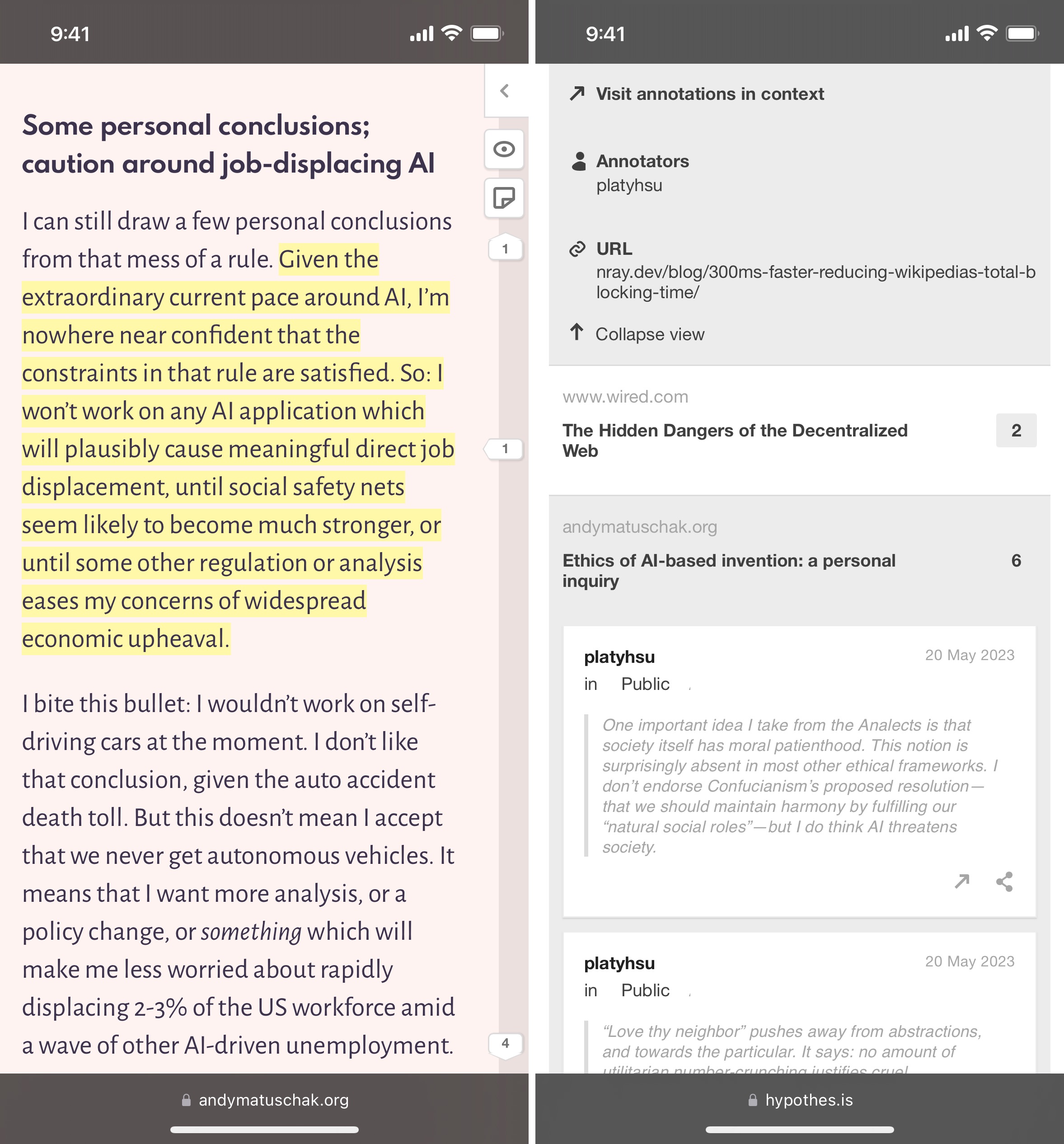
- 管理不便。官方版的网页管理界面只能简单搜索和查阅,不能批量管理和导出,必须依赖另一个由主要维护者个人提供的网页前端 Facet。
- 不能存档。Hypothesis 只专注于网页标注这一个功能,意味着如果网页本身发生删改或断链(在如今越发屡见不鲜),就无法找回当时的上下文,空留零星摘录。
好在,Hypothesis 完善的 API 接口为 DIY 一个更好的体验提供了可能。
我在先前文章中已经举例说明如何使用 API 将特定网页的标注导出为 markdown 格式。基于相同的原理,针对 Obsidian、Logseq 等笔记工具,都有人开发了相应的导出插件;包括后文会提到的 Readwise 在内,很多第三方服务也支持从 Hypothesis 同步标注内容。
另一种我后来发现的 API 用途是在移动端添加标注,比用小书签要顺畅得多。这里的难点在于 Hypothesis 创建标注的 API 语法 [文档] 非常繁琐(拜它的数据结构所赐),以下是经过反复试错发现的最简调用方法:
{
"group": "__world__",
"document": {
"title": "Example Title",
"link": [
{
"href": "https://example.org/test"
}
]
},
"uri": "https://example.org/test",
"target": [
{
"selector": [
{
"type": "TextQuoteSelector",
"exact": "Lorem ipsum dolor..."
}
]
}
]
}
这里:
- 简便起见,我们只使用
TextQuoteSelector保存标注部分原文(记录在.target[0].selector[0].exact中)。 "group": "__world__"表示保存到默认的「公开」(Public)分组;如果想保存到私人(Private)或其他自创分组,可以向https://api.hypothes.is/api/groups端点发送 GET 请求查询其对应id。
得益于晚近版本的 Safari 分享菜单可以一次性输出当前浏览的网页标题、链接和选中部分文本,用一个 iOS 版快捷指令 [下载] 就能按上述格式调用 API。导入这个快捷指令后,在开头填写 API token [查询入口] 和分组 id 即可。之后,在 Safari 中选中任意文本,通过分享菜单传递给该快捷指令,即可保存相应标注到 Hypothesis。
Raindrop:朴实堪用的「经济适用款」
Raindrop 上线于 2013 年末,定位原本是云端书签管理器,随着功能发展逐渐融入了稍后读和标注等附加功能。这也成了它相比 Hypothesis 的一个显著优势:无需另寻方法保存网页内容,在一个工具里就能一站解决。再加上免费起步、年付 28 美元的低廉价格,堪称当下泛知识管理类服务中的性价比之选。(可能因为开发者人在哈萨克斯坦?)

(来源:Raindrop)
但或许同样是受限于书签管理的核心定位,Raindrop 中的标注更像是一个「充话费送的」、锦上添花的功能,从设计到交互都有很多棱角粗糙之处。
首先,从数据结构上看,Raindrop 的标注数据非常简陋。它仅仅只记录标注部分的纯文本内容,也不包含任何文本位置信息。
如果标注的内容都是完整句子,这倒也没有太大问题。但如果标注部分比较简短、又恰好在文中多次出现(常见于高亮小标题、关键词时),只基于文本内容就完全无法准确定位。这时,Raindrop 只会傻愣愣地找到相同内容在文中第一次出现的地方,罔顾事实地认定这就是标注位置,令人捂脸不止。
这种数据结构也严重影响了 Raindrop 的性能。由于每条标注都要通过搜索匹配的方式来确定位置,重新打开有标注历史的页面时,至少要等待好几秒才能看到高亮内容浮现,并且等待时间随着高亮数量的增多而延长。如果网络不好,等个十几二十秒是很常见的。
同时,Raindrop 的标注交互设计也有问题:在新创建一条标注时,按照减少用户等待的原则,本应立即将标注部分高亮,异步地向服务器写入数据;但它实际上做的却恰好相反,先传输数据等待远程反馈,再刷新高亮位置并显示。这种奇葩设计导致从标注到显示高亮之间……也有几秒到十几秒的等待。作为 Raindrop 多年用户,我只能说确实感到自己的耐心随着使用年限而同步增长。
看到这里,你可能认为本文不会推荐用 Raindrop 做标注。但实际上,自从 Raindrop 支持标注以来,我已经将很多日常标注改用它来完成,只有认为值得细读的文章才会保存到稍后读工具里另行处理。
究其原因,对于在快速浏览间隙,零散标注二三要点的用例,追求的无非是留个记号、方便事后找回,上述那些设计问题其实影响有限。相比之下,Raindrop 的更多优点让它成为这种快速标注场景下的首选:

- 内置稍后读功能,标注过的网页会自动创建书签并抓取正文(付费还可以永久存档网页,但不能保存付费墙后的内容),阅读模式中的标注和原始网页上的标注相互同步。
- 标注导出和管理方便。单个页面可以直接从插件或应用中批量复制或导出页面上的所有标注。多个页面则可以通过全文搜索、标签等规则过滤出来,然后同样可以导出为 CSV。
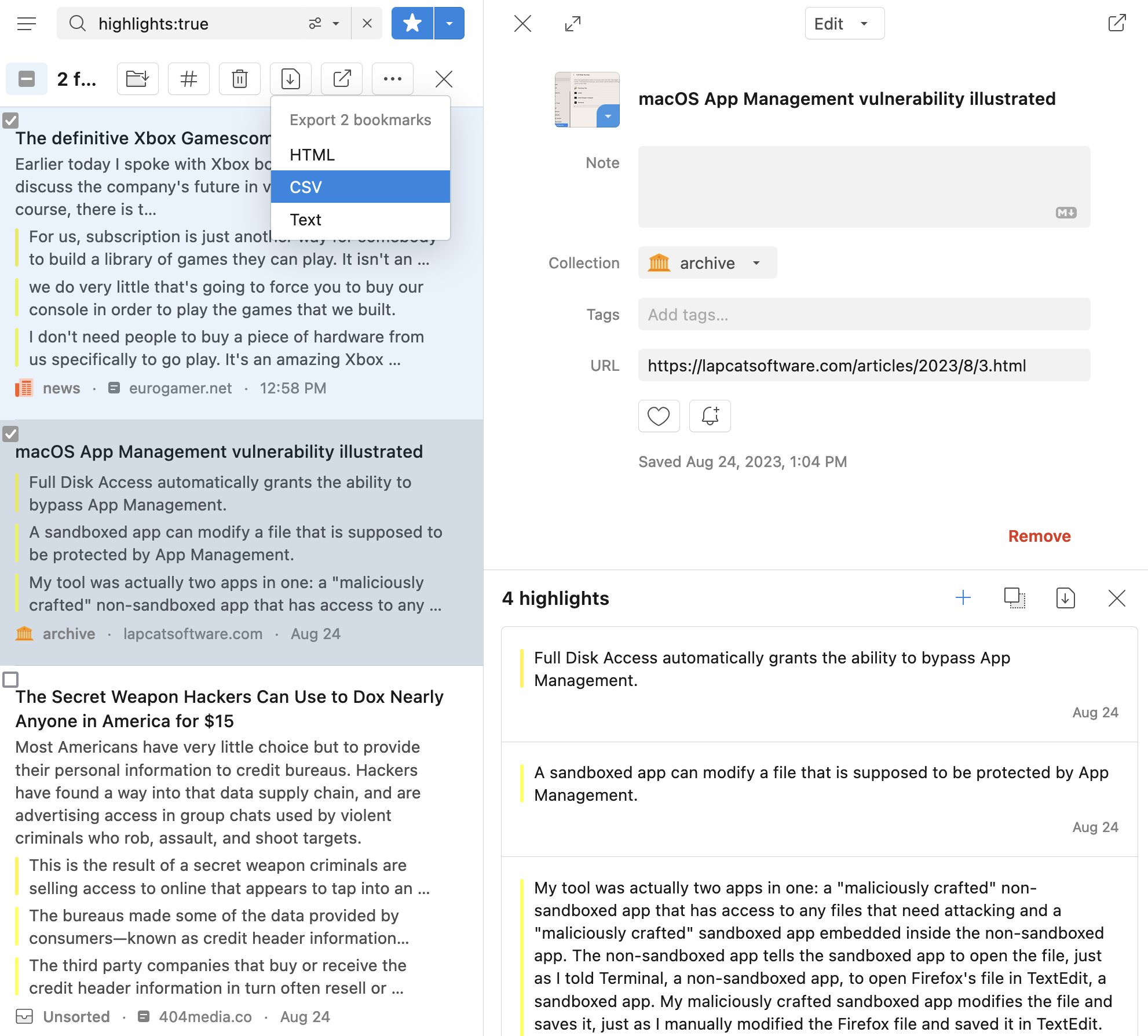
如果你需要更多的自动化空间,Raindrop 也提供了足够全面的 API 支持。事实上,它的网页前端和 app 都是开源的,用的是同一套接口,因此但凡官方有的功能,理论上都可以自己实现。首次调用之前,先到设置页面创建一个新应用,记下生成的 tesk token,就可以按照文档说明操作书签和标注。
仍然以添加一个标注的最简流程为例。首先需要确认该页面是否已经保存过书签或标注,方法是向搜索书签的 API 端点发送 GET 请求:
https://api.raindrop.io/rest/v1/raindrops/0?search={ENCODED_URL}
其中,raindrops 后的数字是 collectionId,0 表示搜索全部书签。search 参数后是经 URL 编码的页面链接。
- 如果返回的
items数组中没有内容,则说明页面还没保存过。此时应当接着用 POST 方法调用创建书签的 API,同时在其中附加标注内容:
{
"link": "https://example.org/test",
"title": "Example Title",
"highlights": [
{
"text": "Lorem ipsum dolor..."
}
],
"pleaseParse": {
}
}
- 如果返回的
items数组中有内容,则说明页面已经保存过。此时应当从中提取书签 ID(位于.items[0]._id),接着用 PUT 方法调用添加标注的 API,同时在其中附加标注内容:
{
"highlights": [
{
"text": "Lorem ipsum dolor..."
}
]
}
我也基于上述思路做好了一个快捷指令供读者使用 [下载]。导入并填入 API token 后,在 Safari 中选中任意文本,通过分享菜单传递给该快捷指令即可保存。
Readwise Reader:待打磨的时尚「潜力股」
最后不得不提的是近两年异军突起的新选手 Readwise Reader。Readwise 原本其实专注于帮用户汇总散落在各个服务中的标注(包括 Hypothesis 和 Raindrop),然后通过间隔复习实现「学以致用」。Reader 则是作为一个给 Readwise 用户的增值功能开发的,但似乎目标逐渐宏大,目前已经向支持阅读网页文章、RSS、PDF 和 EPUB 的「全能」阅读器发展。
但这已经是题外话,我们还是重点看 Reader 的网页标注功能。
先说结论:Readwise Reader 的标注技术也经过精心设计,在数据丰富性和定位能力上,和标杆 Hypothesis 不相上下。具体来说,它也采用了三种方式来定位标注文本,只是都没有完全遵照 W3C 的标准:
- 标注内容:即被标注的原文。与 Hypothesis(也代表着 W3C 规范做法)的
TextQuoteSelector相比,Readwise 没有同时包含上下文。但 Readwise 的一大优势在于它保存的是富文本,在 API 中呈现为 HTML 和 Markdown 两种格式,这使它成为三款工具中唯一可以保留各种格式和链接、并且可以保存图片的。 - 文本偏移量:类似 Hypothesis 的文本位置选择器,但只记录标注起始位置相对于正文开头的偏移量。
- 元素路径:记录标注部分起始和结尾处的位置,格式为
[...]/z/y/x:[offset]。其中,x、y、z、...为位置所在 HTML 元素自身及其每一上级元素在那一级中的出现顺序(从 0 起记),一直上溯到<body>元素为止——说白了就是只用:nth-child()表示的 CSS selector path。冒号后的[offset]指首尾位置在所在元素中的起始字符位数。
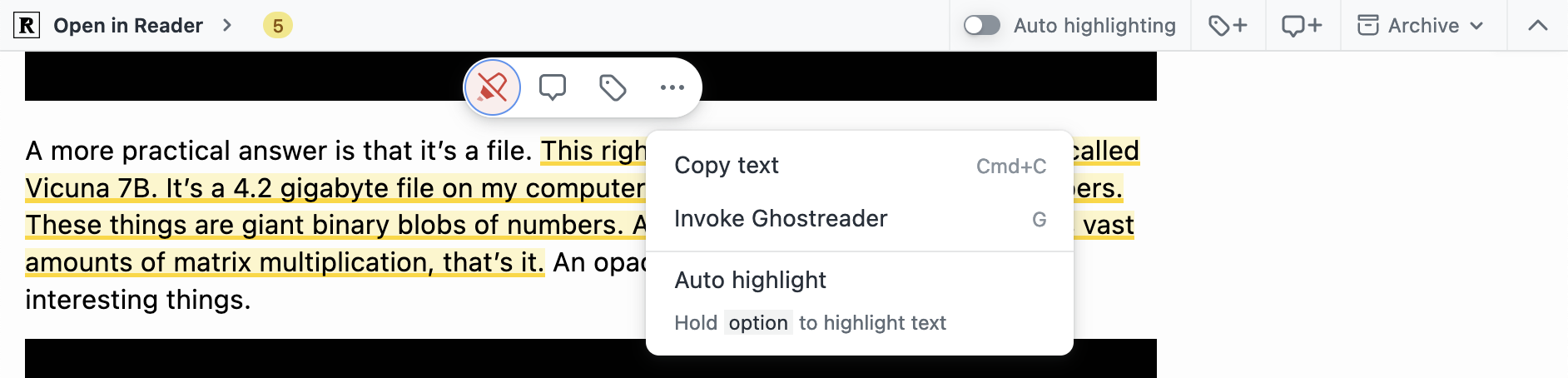
以下图所示这则横跨三段的标注在 Reader 中的记录为例:

- 起始位置的记录为
0/0/1/0/0/0/0/0/0/1/1/0/9/0/1:0。其中,左起数字依次表示标注起始位置所在的 HTML 元素 (1) 其自身位于同级第一位,(2) 其上级元素位于同级第一位,(3) 再上级元素位于同级第二位……直到向上 15 层位于同级第二位。再往上,就到了<body>,追溯结束。冒号后的 0 表示开头是所在元素的第一个字符。 - 结尾位置的记录为
0/3/0/0/0/0/0/0/1/1/0/9/0/1:92,冒号之前的部分也是路径序列,冒号后的 92 表示结束于所在元素内第 91 个字符后。
如果说在标注的核心功能上,Readwise Reader 和 Hypothesis 互有胜负,它在易用性上的优势就大得多了。
与 Raindrop 类似,Readwise Reader 具有全平台的客户端和浏览器插件;标注过的网页会被自动抓取保存,标注项也会在阅读模式和原版网页之间同步;作为 Readwise 主服务的衍生功能,Reader 所做的网页标注自然也会直接进入前者的标注内容库中,可以全文搜索、定期收到回顾提醒,并通过官方插件同步到 Obsidian 等服务。
当然,作为一个尚属年轻(按其团队定义,还没有达到 1.0 状态)的服务,Readwise Reader 的缺点也比较明显:
- 不支持在移动端直接标注网页,只能先保存再标注 app 中的阅读模式版本;
- API 支持很初级,目前只提供保存页面这一个功能,不支持通过 API 添加新标注;
- 过于追求功能全面和设计时尚,网页端和移动端 app 优化情况都很一般,能感到明显卡顿,并且常有 bug。
最后,Readwise Reader 的价格也是三者中最不亲民的。如上所述,Reader 作为 Readwise 主服务的「增值功能」销售,目前已经要价每月 8 美元(需按年付费),并且官方表示待功能完善后,有计划涨价到 10 美元以上。不过,Readwise 提供五折的教育优惠,此外「发展中国家」和「货币汇率下挫国家」用户可以写信要求优惠,实践中似乎中国用户都能拿到五折优惠。如果考虑到这一点,性价比还是可以的。