用「快捷短语」提高搜索效率
A version of this article appears on Oct. 3, 2023 on SSPAI as a member-only post. Learn more or subscribe
The article is permitted to be self-archived in the version as originally submitted for publication on the author’s personal website under CC BY-NC 4.0 pursuant to § 5.2(b) of the SSPAI Fellowship Contributor Agreement.
有大量研究检索需求的用户,大概都会收藏一批搜索引擎链接。这不仅包括 Google、Bing 等主流通用搜索引擎,也包括 Google Scholar、Wolfram Alpha 等用于特定领域或功能的垂直搜索引擎,通过图书馆或内网代理访问的数据库搜索引擎,以及平台类网站的站内搜索引擎等。
从更广义的角度理解,任何可以通过形如 GET 请求的形式调用,在相关使用场景下只有一个待填参数的 API,都不妨看作是一个「搜索引擎」,例如 iOS 上直接跳转到应用内搜索的诸多 URL Scheme。
即使在 AI 问答来势汹汹的当下,这种「直通车」式的信息获取方式仍不失其优势,值得继续沿用。
但随着收藏积累的增多,如何管理和记忆的问题也随之而来。将搜索入口页面存为书签固然是一种方法,但调用起来显然过于繁琐。相比之下,一种更方便的做法是为常用搜索引擎各自分配一个「快捷短语」,例如用 g 代表 Google、用 w 代表维基百科等,然后通过「快捷短语 + 搜索语句」的方式快速调用。
实现这种功能的方法很多,包括浏览器自带功能、外部自动化工具、搜索引擎的特殊语法等,各有优劣。本文将先对这些工具做一概述,然后说明如何自己动手做一个支持自定义快捷短语的搜索引擎「转发器」,并通过 Vercel 或 Docker 部署到网上,从而实现「一次配置、随处可用」。
传统方法回顾与比较
借助浏览器
几大主流浏览器都不同程度地支持快捷短语。
支持最好的是 Chromium。遇到过的搜索引擎都会显示在设置页面的「搜索引擎」>「管理搜索引擎和网站搜索」底部。
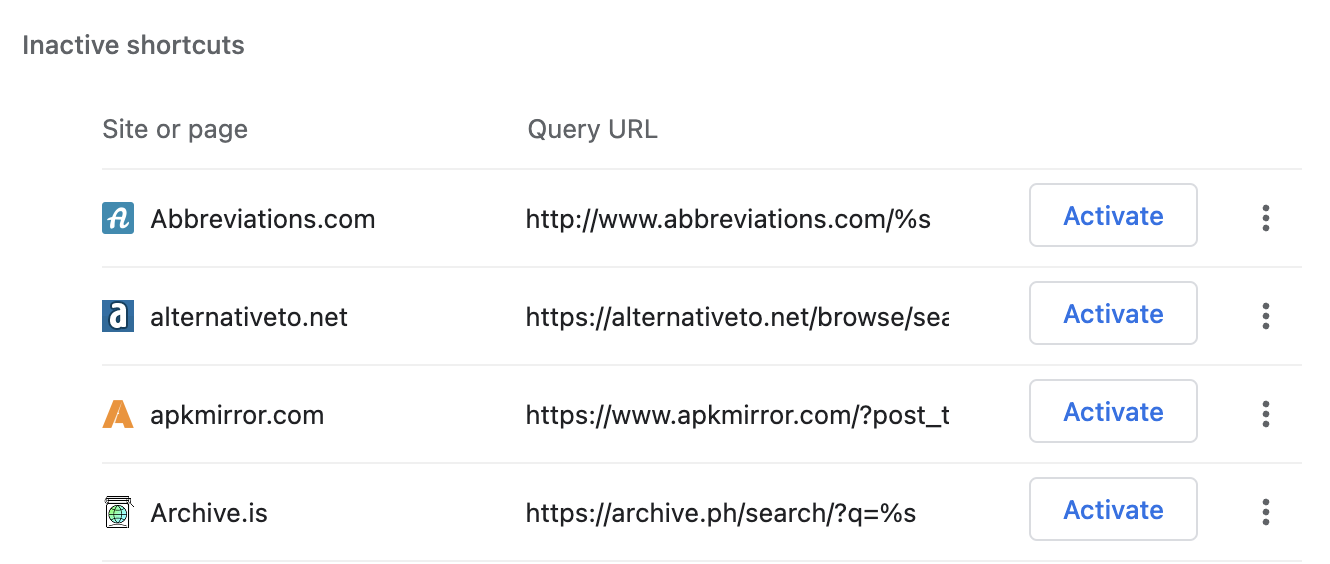
单击右侧的「激活」按钮将其启用,然后再点击铅笔形状的「修改」图标,编辑窗口中的「快捷字词」即可。
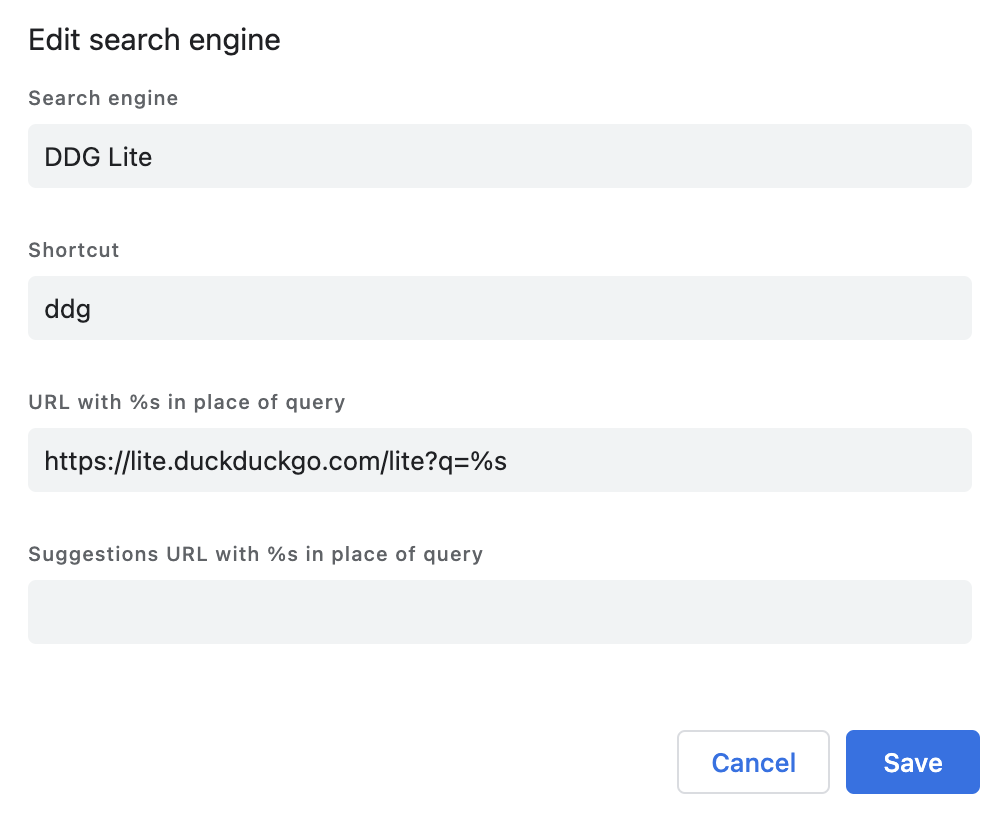
如果 Chromium 没有记住你需要的搜索引擎,也可以自己手动添加。(官方帮助)
其次是 Firefox。虽然不能主动记住搜索引擎,但可以手动在想收藏的搜索框中点击右键,选择「为此搜索添加关键字」,然后即可在存为书签的同时设定一个快捷短语。(官方帮助)
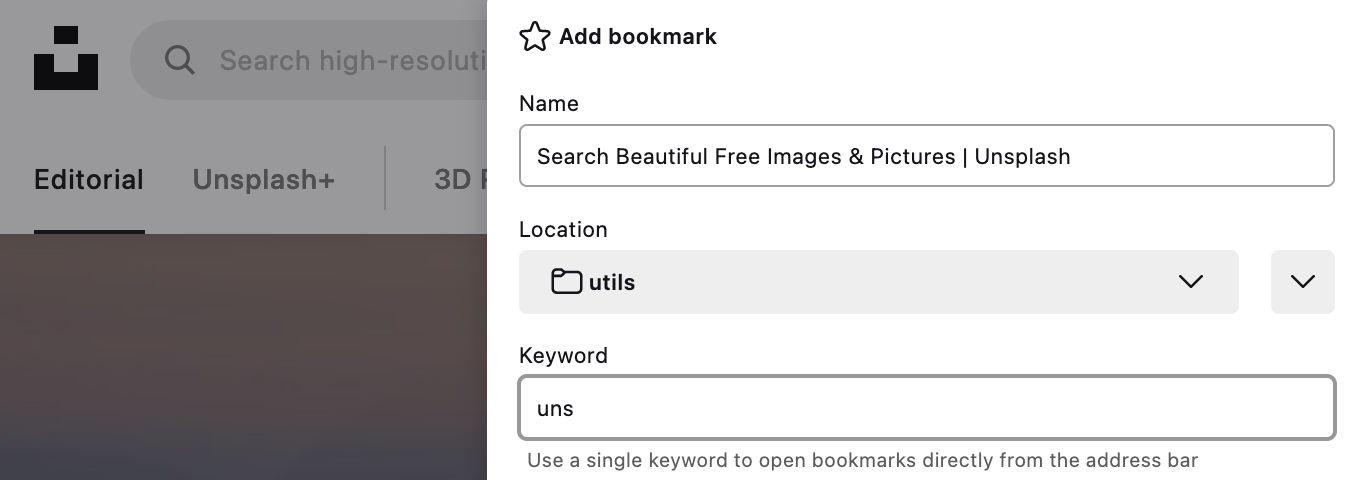
事实上,Firefox 会将所有地址中包含 %s 的书签视作一个「搜索引擎」,通过「快捷短语 + 搜索语句」的格式调用时,会自动将 %s 替换为搜索语句再跳转。
此外,「设置」>「搜索」中通过安装而添加的搜索引擎也可以双击列表中的「关键字」一列添加关键字。(官方帮助)
不过,Firefox 一个非常令人困惑的设计在于,通过书签创建的搜索引擎和「设置」中的搜索引擎是两套互不相关的体系,只有通过特定方式(具体说是下文介绍的 OpenSearch 协议)安装的搜索引擎能进入「设置」,并有资格被设置为默认搜索引擎。
灵活性最低的是 Safari。虽然也能自动发现并记住搜索引擎,但不支持任何形式的自定义,能不能记住、用什么快捷短语全凭 Safari 自作主张。具体列表则要通过「设置」>「搜索」页面下,「启用快速网站搜索」开关右侧的「管理网站」按钮查看。(官方帮助)
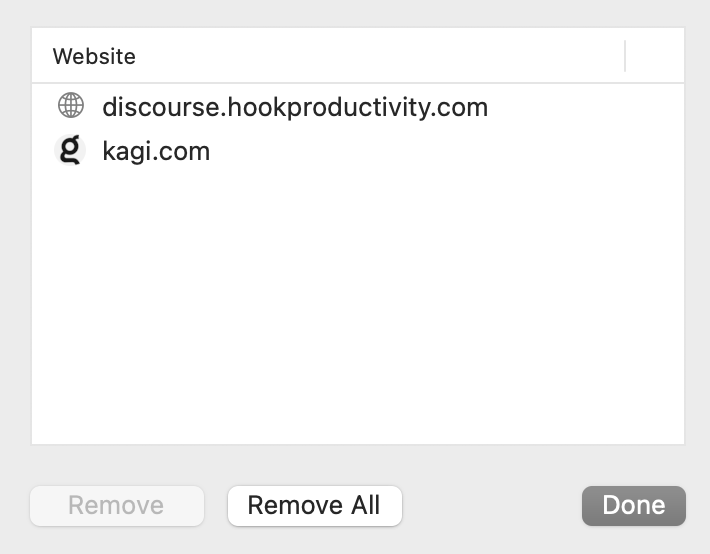
问题在于,Safari 自己提取的关键短语非常冗长——大多直接使用次级域名——并无「快捷」可言。好在有一个历史悠久的第三方插件 Safari Keyword Search 可以补充自定义快捷短语的能力(代码开源,上架版本有象征性收费)。
总的来说,通过浏览器自带功能设置搜索引擎快捷短语,好处在于离使用场景最近,缺点则在于大多不能跨设备同步(只有 Firefox 以书签形式添加的搜索引擎能通过 Firefox 账号同步),而且互不相通。换一个浏览器、换一台设备就要重新设置一遍,数量一多就难以维护。
插曲:浏览器如何「发现」搜索引擎
浏览器是如何知道一个文本框是不是搜索框呢?
传统上,这是由网站通过一个叫做 OpenSearch 的标准告知浏览器的。OpenSearch 原来是由亚马逊在 2005 年牵头制定的,根据这个标准,网站可以在 HTML 的 <head> 部分链接到同一域名下的 OpenSearch 描述文件(通常命名为 opensearch.xml),并在其中说明搜索相关的各项信息。浏览器通过查找和读取 OpenSearch 描述文件,就能「认识」新的搜索引擎。
以 DuckDuckGo 的 OpenSearch 描述文件 http://duckduckgo.com/opensearch.xml 为例:
<?xml version="1.0" encoding="utf-8"?>
<OpenSearchDescription xmlns="http://a9.com/-/spec/opensearch/1.1/">
<ShortName>DuckDuckGo</ShortName>
<Description>Search DuckDuckGo</Description>
<InputEncoding>UTF-8</InputEncoding>
<LongName>DuckDuckGo Search</LongName>
<Image height="16" width="16">data:image/x-icon;base64,...</Image>
<Url type="text/html" method="get" template="https://duckduckgo.com/?q={searchTerms}"/>
<Url type="application/x-suggestions+json" template="https://duckduckgo.com/ac/?q={searchTerms}&type=list"/>
</OpenSearchDescription>
可以看到,其中提供了简称(<ShortName>)、全称(<LongName>)、描述(<Description>)、默认编码(<InputEncoding>)、图标(<Image>)、搜索结果地址(<Url type="text/html">)和搜索建议地址(<Url type="application/x-suggestions+json">)等信息。
浏览器就是通过这些信息自动发现和填充搜索引擎信息的。特别是在 Firefox 中,只有适配了 OpenSearch 的网站才能被添加为「设置」中的默认搜索引擎(通过在地址栏上点击右键选择「添加 [搜索引擎名称]」),否则在就要借助插件或在线服务,而其原理都是构造出一个 OpenSearch 描述文件供 Firefox 读取。
当然,实践中,很多网站并不会花额外功夫适配 OpenSearch 协议。随着时间推移,OpenSearch 也有逐渐被淡化和遗忘的趋势(连这个名字都被亚马逊挪作他用了)。为此,作为补充,主流浏览器也各有一套检测算法(heuristics),不依赖于网站主动说明,而是根据页面的内容和结构特征,「推测」出哪些输入框可能就是搜索框。
例如,无版权图库 Unsplash 虽然没有关联的 OpenSearch 描述文件,但上述三大浏览器都能检测到它首页的搜索框,并提供添加为自定义搜索引擎的选项。
借助外部工具
大多数「启动器」(launcher)类工具都将自定义搜索作为基础功能之一,包括 macOS 上的 Alfred、LaunchBar、Raycast,Windows 上的 Quicker、Listary、Fluent Search 等。(链接均为相应官方帮助页面。)
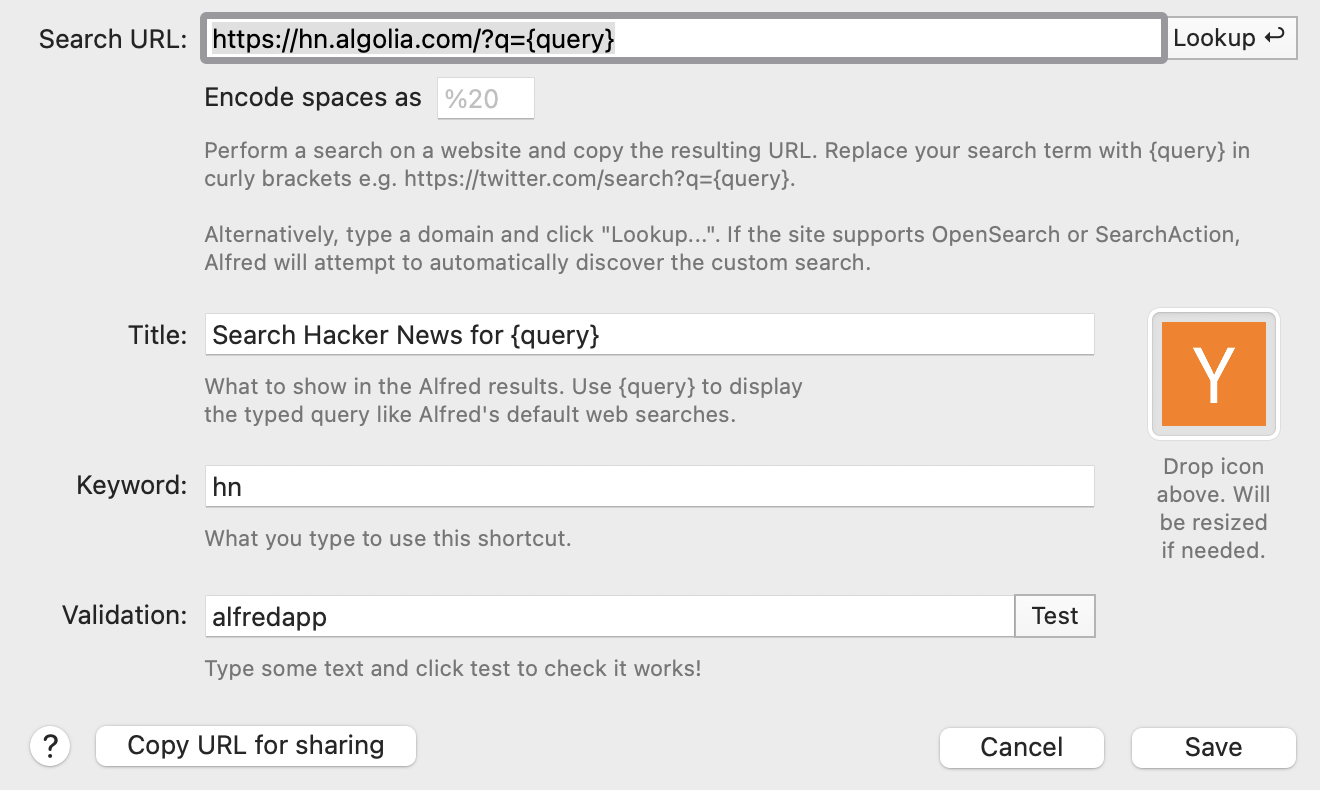
Alfred 的自定义搜索引擎界面
通过外部工具设置搜索引擎快捷短语,好处在于不依赖于特定浏览器,而且通常能通过工具自带的同步功能跨设备同步。但这些工具只能用于桌面系统,无法兼顾移动端的快捷搜索需求。
借助搜索引擎语法
这个称为「bang」的功能据我所知是由 DuckDuckGo 首创的,几年前在介绍 DuckDuckGo 时也特别推荐过。
简单来说,使用 DuckDuckGo 时,通过在搜索语句开头加入一个感叹号,后接一个快捷短语(称为一个「bang」),就能跳转到这个 bang 所指向的搜索引擎或网站进行搜索。
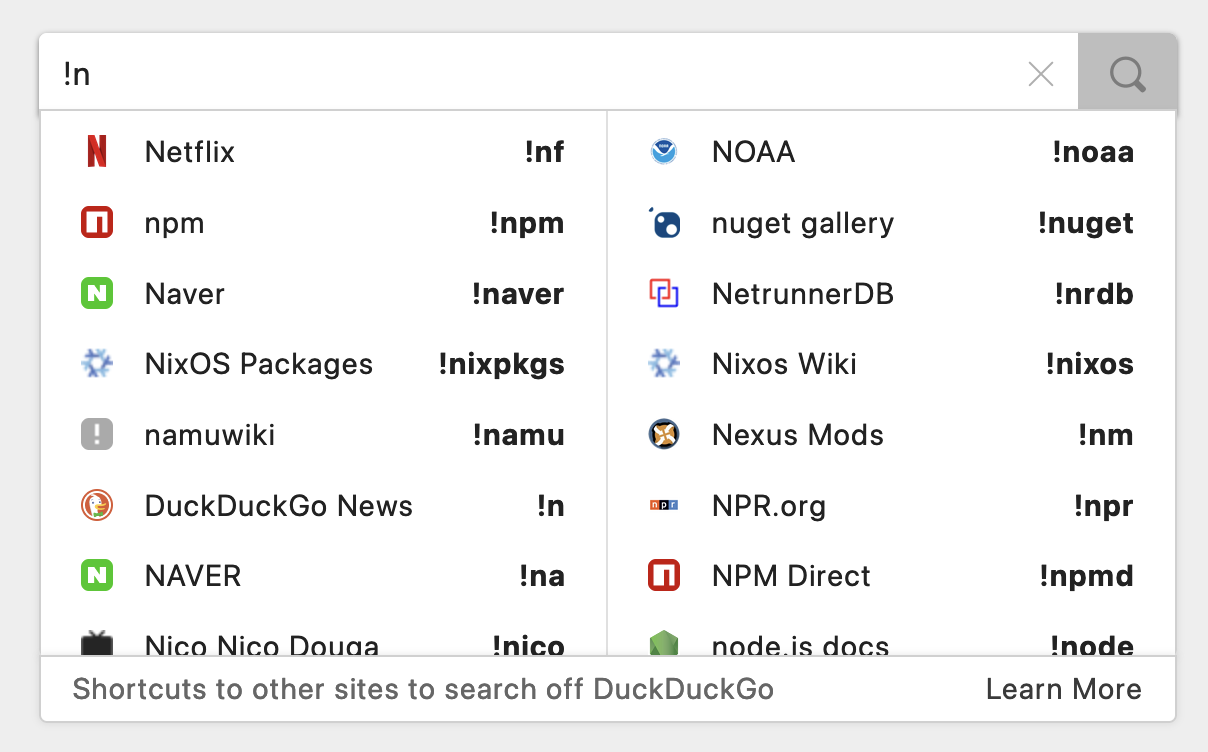
例如,如果你搜索 !g Wikipedia,就会被跳转到 Google 搜索 Wikipedia 这个关键词。通过 bang 转发的搜索是完全匿名的,因此非常适合用作「跳板」来调用那些隐私保护堪忧的搜索引擎。
bang 功能后来也被 Brave、Kagi、SearX(NG) 等后辈效仿,但 DuckDuckGo 做的仍然是最好的:除了支持的 bang 数量最多外,还贴心地考虑到了用户的输入便利,!bang 无论出现在搜索语句的开头还是结尾,甚至将英文感叹号换成中文感叹号,都仍然可以识别。
通过 bang 语法实现快捷搜索既不依赖于特定浏览器或系统、也无需考虑同步的问题,但前提是愿意将 DuckDuckGo 设置为默认搜索引擎——对于大多数中文用户可能并非一个理想选择。此外,bang 的搜索引擎目录是由用户自主提交维护的,无法设置更符合自己习惯的快捷短语(例如用 tb 而非 taobao 搜索淘宝);目录的质量也比较平庸,其中存在很多重复、过时或失效的条目。
插曲:DuckDuckGo 的 bang 数据
即使你不准备将 DuckDuckGo 用作主力搜索引擎,它的 bang 目录也是一个很不错的搜索引擎资料库。在前端,DuckDuckGo 提供了两个入口来浏览和检索 bang,分别是 https://duckduckgo.com/bangs 和 https://duckduckgo.com/bang_lite.html,区别在于前者带有搜索和分类功能,后者是一个纯静态页面。
但最适合程序化检索和抓取的还是源文件 https://duckduckgo.com/bang.js。这个后缀名是误导性的,其内容实际上是一个 JSON 数组,格式如下:
[
// omitted
{
"c": "Tech", // 分类
"d": "hn.algolia.com", // 域名
"r": 3591, // 被使用次数
"s": "Hacker News", // 名称
"sc": "Startups", // 次级分类
"t": "hn", // 快捷短语
"u": "http://hn.algolia.com/?={{{s}}}" // 搜索链接模板
},
// omitted
]
自己做一个快捷搜索跳转服务
可以看出,无论借助浏览器自带功能、外部自动化工具还是特定搜索引擎的特殊语法,都有各自的局限性,不能充分覆盖各种可能的使用场景。对于搜索这种效率为先、依赖肌肉记忆的任务来说,并不理想。
其实,如果能做一个类似于 bang、但支持快捷短语自定义的搜索引擎「转发器」,然后将其他工具的搜索地址都指向它,不就能实现一次配置、随处可用的目的了吗?
这听起来还挺复杂,但其实完全在个人用户力所能及的范围内。因为我们并不需要真的去做一个搜索引擎,只需要做一个具有关键词识别和跳转功能的文本框,根据识别到的关键词,自动打开相应的搜索页面就行了。
可行的实现方法很多,经验丰富的读者自可各显神通。考虑到方便在线部署,这里选择 Node.js 来演示。完整的代码放在 GitHub 上,你可以直接查阅复制使用,也可以跟随下文一步步搭建自己的版本。

制作好并部署的效果
脚本编写与测试
首先来编写发挥核心功能的 search.js:

(原始代码)
这段脚本的工作方式是:
首先,接收从 /search 路径传来的 GET 请求,读取其中的 q 参数为搜索语句(第 9 行);
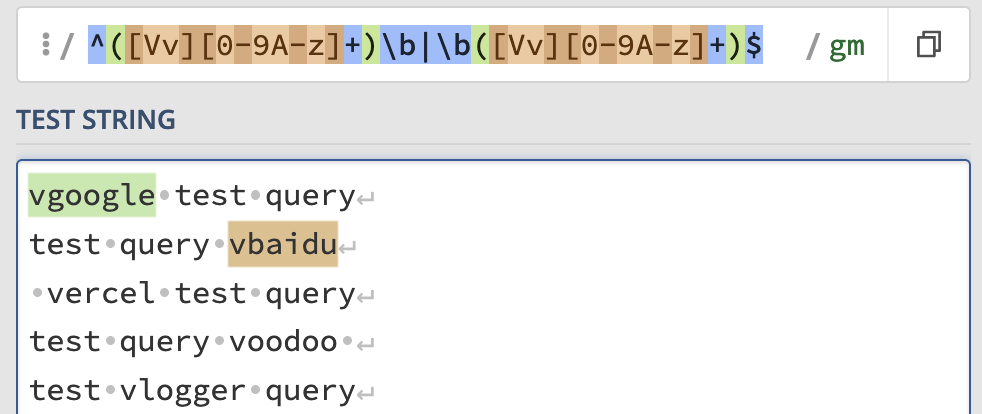
然后,用正则表达式 ^([Vv][0-9A-z]+)\b|\b([Vv][0-9A-z]+)$ 匹配搜索语句(第 10 行)。这是指行首或行尾以字母 v(大小写均可)开头,后接一串字母或数字的组合,且与相邻内容以单词边界隔开。
这大体上模仿了 bang 的语法,但把开头的 ! 换成了 v,目的是输入起来更方便(允许大写是考虑到 iOS 键盘的行首自动大写),并且排除了一些含特殊字符、过于生僻的 bang。如果搜索语句的开头或结尾正好是一个 v 开头的单词,只要在开头或结尾多打一个空格就不会被当作 bang 了,而这个多出的空格后续会被去除(第 18 行)。
如果匹配到了 bang,就继续从自定义配置文件 user.json 里查找是否有对应的快捷短语定义,进而重定向到填充了关键词的搜索链接(第 22—25 行)。这里,user.json 的设计采用和上文提到的 DuckDuckGo 所用 bang.js 兼容的结构(偷懒的话甚至可以直接全文粘贴过来),但只用到了 t 和 u 两个必要的键。
例如,下面的配置片段分别定义了搜索少数派的 ssp 和在苹果设备上搜索 App Store 的 app:
[
// omitted
{
"t": "ssp",
"u": "https://sspai.com/search/post/{{{s}}}"
},
{
"t": "app",
"u": "itms-apps://search.itunes.apple.com/WebObjects/MZSearch.woa/wa/search?media=software&term={{{s}}}"
// omitted
]
重定向使用 303 (See also) 状态码,以表明跳转结果是对原请求「间接」、不等价的响应。
如果匹配到了 bang,但 user.json 中没有相应的自定义快捷短语,就把搜索请求重定向到 DuckDuckGo,以便利用它更完整的 bang 目录(第 27 行)。如果完全没有匹配到 bang,就调用大路货 Google 搜索,但通过 DuckDuckGo 的 !g 匿名转发(第 30 行)。如果你希望以其他搜索引擎为后备方案,将其搜索路径换上即可。
将这段 search.js、编辑好的 user.json 和描述文件 package.json(下载)共三个文件放在同一个目录下,依次运行:
npm install
npm start
这时,测试用浏览器访问 http://localhost:3000/search?=<keyword>,应该就能按上述逻辑跳转到对应的搜索页面。
制作前端页面
如果你嫌只能通过路径调用不够方便,还可以为它做个前端页面。虽然如今有无数框架号称可以帮你「几分钟搭建一个前端」,但这点功能用框架无异于环保犯罪。所以,这里是一个手打也只要十分钟的乞丐版:

(原始代码)
除了文案和装饰性的样式(我脸滚键盘做的粗犷版),这里主要就是搭建了一个 <form> 作搜索框(第 18—30 行),将输入内容作为参数 q 发送到同目录下的 /search,也就是先前步骤制作的 search.js 的侦听路径。
为了方便,在搜索框下方放置了几个快捷方式(第 31—38 行),点击后会调用网页内置的一个小脚本(第 63—67 行)将相应 bang 追加到当前输入内容开头,然后触发搜索。你可以根据自己的使用习惯更换常用快捷方式。
此外:
- 为了让浏览器可以自动发现并保存这个「搜索引擎」,这里运用上面介绍的 OpenSearch 协议,链接到了同目录中的
opensearch.xml描述文件(第 6 行)。你可以下载模板并按照需求修改其中的图标、域名、关键词建议服务等内容。 - 为了更好地保护隐私,这里将整个页面的
Referrer-Policy设置为no-referrer(第 12 行),从而使得跳转后的搜索引擎无法通过请求头部的referer字段得知用户从何跳转而来。
云端部署
脚本写好了,怎么放到网上随时使用呢?因为今年是 2023 年,所以大概有——我不知道,一万种?——不同的方法可以免费在云端跑一个 Node 脚本。
简便起见,我在代码库中预留了一个针对 Vercel 的一键配置 vercel.json,点击项目主页里的 Deploy 按钮(或者复制项目到本地后在终端运行 vercel)即可自己部署一份。
显然,如果你更习惯 Netlify、Cloudflare Workers 或者 Fly.io 之类其他选择也是完全可以的,具体可以参阅相关文档,这里就不一一演示了。
如果你更习惯用 Docker 在局域网或者 VPS 上部署,这里也提供了一个 Dockerfile 模板。复制项目到本地后,依次在其目录中构建镜像:
docker build . -t platyhsu/vbang2
再运行容器:
docker run -p 10086:3000 -d platyhsu/vbang2
即可在 localhost:10086 访问到这个页面。你可以随意按自己的需求更换上例的镜像名称、外部端口,并为容器绑定域名和证书等。
最后,将浏览器和其他支持自定义搜索工具的默认搜索引擎设置为这个自制引擎即可(Safari 不支持自定义搜索引擎,可以使用 Redirect Web 等插件将默认搜索引擎重定向到服务部署的地址)。