Kimi 长上下文试用
DISCLOSURE: A version of this article appears on Apr. 3, 2024 on SSPAI, where I am a staff editor. SSPAI received early access to the feature discussed below at no cost and before it was made available to the general public. However, the article was written independently and there were no other conflict of interest.
引言
如果将大语言模型比作大脑,那么「上下文窗口」(context window)就衡量着它的「记忆容量」。这个重要的参数代表模型一次性可以读取的最大文本长度。上下文窗口越大,模型在「思考」时能调用的素材就越多,理解对话和任务背景就越充分,由此生成的答复也就会更加准确和相关。
在过去两年的快速发展中,大语言模型的上下文窗口已经见证了长足的进步,也成为厂商之间比拼激烈的参数之一。以最流行的 GPT 系列模型为例,两年前的早期版本 GPT-3 还只能支持 2048 tokens 的上下文窗口。(token [令牌] 是大语言模型处理文本的最小单元;按照 OpenAI 的切分方式,一个 token 平均相当于四分之三个英文单词。)经过历次更新,目前版本的 GPT-3.5 Turbo 可以支持 16K [16,385 tokens],GPT-4 Turbo 可以支持 128K。
OpenAI 的主要竞争对手中,Anthropic 的 Claude 系列模型一向以长上下文支持为特色,在 2023 年 5 月就率先支持了 100K 上下文,今年初发布的 Claude 3 系列模型还进一步提升到了 200K。Google 的 Gemini 系列模型从 32K 起步,目前还在小范围内测的 1.5 Pro 则达到了 1M。
上个月,国内模型厂商月之暗面宣布实现将旗下 Kimi 智能助手的上下文窗口从 20 万字提高到 200 万字,并开启申请内测。经过联系,我们获得了提前体验资格,并有机会直接向 Kimi 团队提出一些问题。
(根据 Kimi 团队的说明,Kimi 中的 200 万字相当于 1M tokens;这与 GPT 模型的换算比例有所不同,是底层算法不同导致的。)
Kimi 团队告诉我们,之所以将长上下文作为一个优先研发方向,有一定战略上的考虑。首先,在 Kimi 团队看来,在通往通用人工智能(AGI)的过程中,无损的长上下文将会是一个很关键的基础技术;历史上所有的模型架构演进,本质上都是在提升有效的、无损的上下文长度。同时,他们认为,更长的上下文窗口可以进一步打开对 AI 应用场景的想象力。
效果实测
那么,Kimi 长上下文支持的效果究竟如何呢?
之前,国外厂商在介绍具有长上下文能力的模型时,经常会选择使用一种称为「大海捞针」(Needle in a Haystack, NIAH)的基准测试。这项测试的方法是:将随机事实或陈述(「针」)放在文本中,然后向模型提问,考察其能否从文本中找到那根「针」;然后,将针的位置(「深度」)不断后移,文本不断加长,从而得到一个成绩矩阵。Gemini 1.5 和 Claude 3 的技术报告均援引了大海捞针的成绩。
Kimi 团队没有针对此次更新的长上下文能力做大海捞针测试。他们表示,这项测试刚出现时是个很好的测试指标,但随着这项测试的流行,任何模型只要稍加优化就可以做到「全绿」,也就是通过所有深度和长度组合条件下的测试,因此已经失去了对照意义;此外,大海捞针对大模型而言,实际上也是一项比较简单的任务,不能全面体现模型的能力。不过,Kimi 团队仍然表示对于相比竞品的效果很有信心。
因此,在测试和体验 Kimi 的长上下文能力时,我也没有采用基准测试的方法,而是根据过去想到过、但囿于上下文长度限制未能实现的几个需求,设计了几个具体场景来评估 Kimi 的表现。
市场分析
今年以来的 IPO 中,比较引起市场关注的事件肯定包括年初蜜雪冰城、古茗同时递表,随后也出现了大量分析和对比两家公司招股书的文章。招股书属于典型的篇幅冗长、结构固定的八股文本,本身就很适合交给 AI 辅助分析;但之前囿于长度限制,一份都难以容纳,更不用说对比。
首先从港交所下载两份文件(蜜雪冰城、古茗),确认一下文件长度:
pdftotext mixue.pdf - | wc -m
# 369351
pdftotext goodme.pdf - | wc -m
# 420975
(这里的 pdftotext 命令用来从 PDF
中提取纯文本;你可以通过习惯的包管理器安装 poppler 来获得这个程序。)
即两份文件加起来字符数约 80 万。将文件上传到 Kimi,简单交代背景和一般要求。
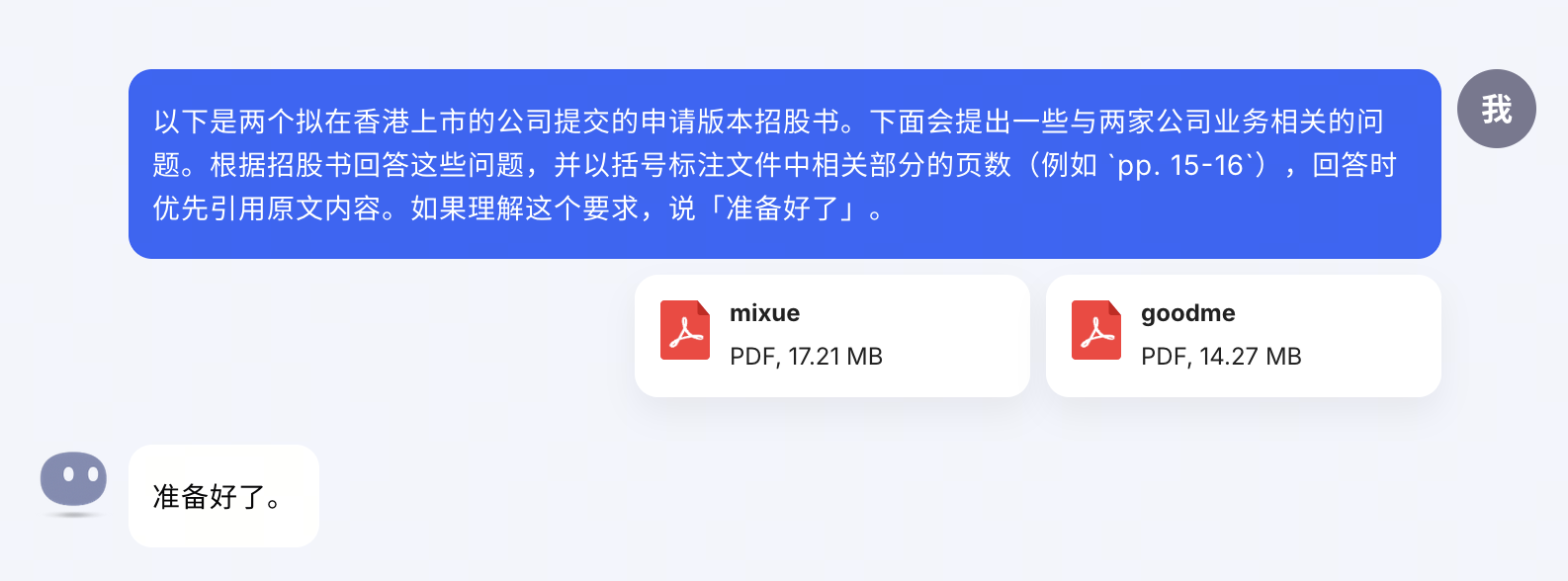
首先问两者在品类和价格段上的区别,以及取得的成绩。这些一般会写在开头的序言部分和中间位置的「业务」一章。Kimi 找的也是比较全面的。

再看一个稍微进阶的例子:分析两家公司在供应链和物流方面的异同。

可以看到,古茗部分的总结是比较准确的,蜜雪冰城部分则稍有瑕疵:前半段的「门店网络广」并不属于「供应链」的特点,更合适的引用应当是其配送网络的相关数据。此外,原因总结部分提到业务模式和市场定位是正确的,但没有能进一步考虑这是为了适应不同类型主推饮品的需要。作为对比,晚点的文章就分析道,「蜜雪冰城的物流配送服务的特点是覆盖广、深入。[…] 古茗则拥有更强大的冷链物流能力,这和其菜单上的水果茶占比有关。」
(提示词中的「客观、中立」等要求是根据 Kimi 团队的提示添加的。如果没有这句话,Kimi 容易过于依赖公司自己的描述,导致回答有些「广告味」。另一个小瑕疵是,从这里开始,Kimi 也没有记住最初提示词中「标注页码」的要求,需要重新在后续提示词中要求一次。)
接下来关注招股书里比较重要的风险披露部分。这一部分可能是最能反映「天下文章一大抄」的,很多时候你能看到同样一段轱辘话在十几年间代代相传。但就是因为套话太多,那些真正原创的片段往往就更显重要。显然,几十页的篇幅靠人眼对比是很痛苦的,而 AI 显然比较擅长于此:

最后问的是两个法律角度会比较关心的问题:历史沿革和公司架构。

Kimi 的回答不是特别切题,主要问题在于过于宽泛地理解了「历史沿革」的含义——它在招股书语境下指的主要是集团公司历史上的设立、变更和股权交易情况,而不是「公司的发展史」(即使特别在提示词中做出了解释仍然如此)。公司架构方面则基本没有提供有效的信息,例如一般会关注的境外公司架构、老股东情况等都没有提及。
辅助编程
生成式 AI 辅助编程是一个非常热门的应用。但是,现有方案往往不能充分反映现有代码库的情况。即使是 GitHub Copilot 这样基于插件的方案,也只能从代码库中挑选一些片段发送给模型参考。更长的上下文窗口给送出更全的现有代码提供了可能。
这里以 GitHub 上的 oduwsdl/CarbonDate 项目为例,这是一个通过提取多种元信息,试图推测网页发布时间的有趣工具,我曾在之前的文章中以它为例说明如何从他人代码库中「取经」。下面来看看 Kimi 对它的理解程度如何。
插曲:如何让 Kimi 处理整个目录的文件
测试这个场景时遇到的一个小问题:虽然 Kimi 支持批量上传文件,但不支持上传文件夹,从而无法反映路径层级中包含的信息。因此,我写了一个简单的脚本,将指定目录中的所有文件(不含隐藏文件和隐藏目录中的文件)及其路径都汇总到一个 JSON 文件中(本例中的长度为 150 万字符,你可以自己下载测试),然后再输入给 Kimi:
#!/bin/bash
DIR=$1
echo "[" > output.json # open the outer array
find "$DIR" -type f \( ! -regex '.*/\..*' \) -print0 |\
while IFS= read -r -d $'\0' file; do
jq -n \
--arg path "$file" \
--arg content "$(cat "$file")" \
'{path: $path, content: $content}' >> output.json
echo "," >> output.json
done
sed -i '' '$ s/,$//' output.json # remove the dangling comma
echo "]" >> output.json # close the outer array
(用 shell 是因为……我只会这个。)
首先问几个简单的问题:语言、依赖项、readme 文件内容,以及稍微进阶的工作原理分析。
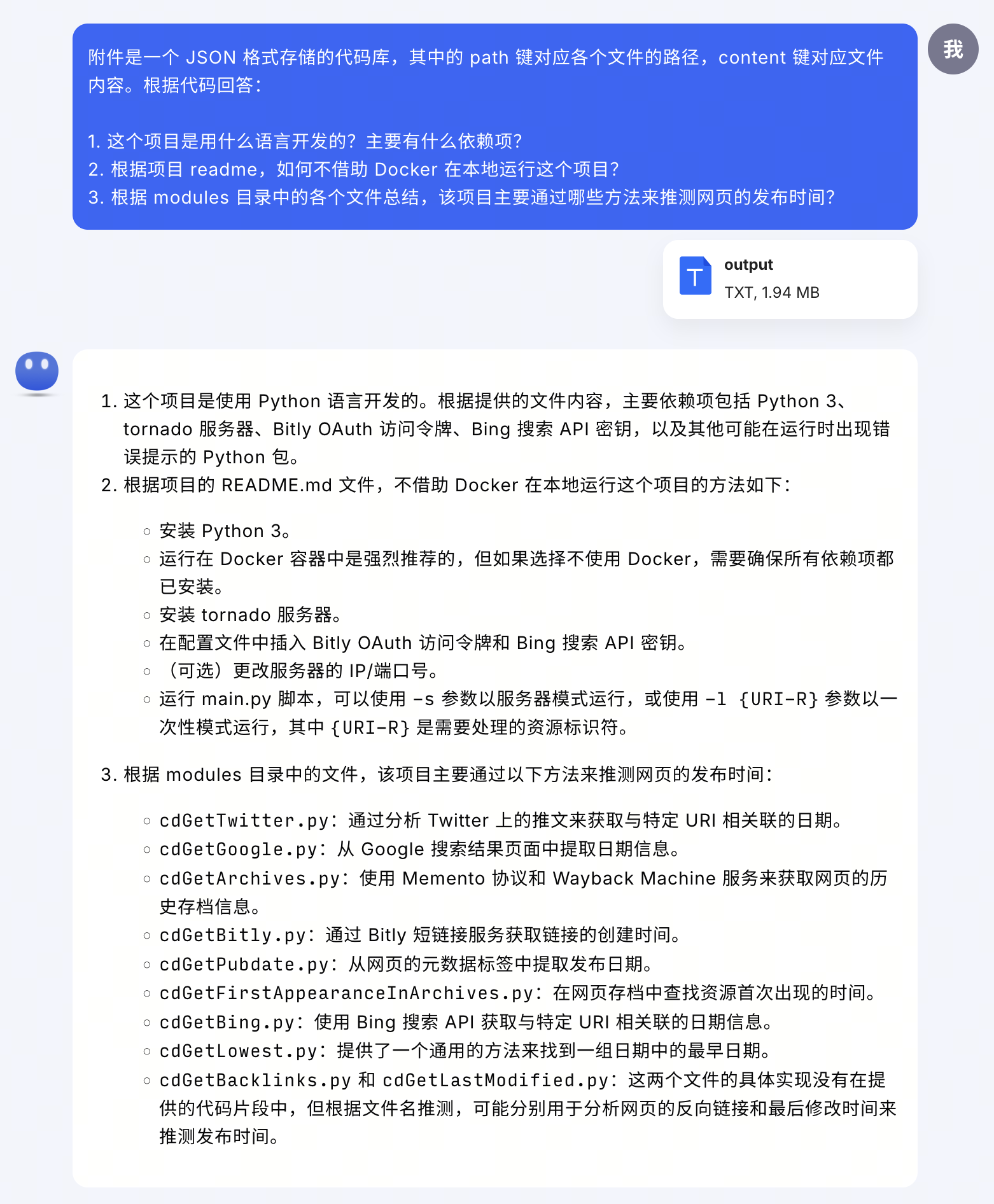
应该说 Kimi 的回答总体上是令人满意的。特别是第 3
问,可以看出不仅充分理解了问题,而且能根据不同程度的可用信息做合理推断。反倒是第
1 问中的依赖项总结有些瑕疵,这本来可以通过查看 requirements.txt
的内容快速找到答案,但 Kimi 似乎更多依赖于 readme
中的信息,并且杂糅了一些本质上是运行要求(prerequisites)的说明。
接着再尝试一个编程任务:额外提供另一个搜索引擎 Kagi 的 API 文档,要求仿照现有模块写一个从 Kagi 搜索结果页提取网页发布日期的新模块,并分析需要修改哪些其他文件来整合这个新模块。
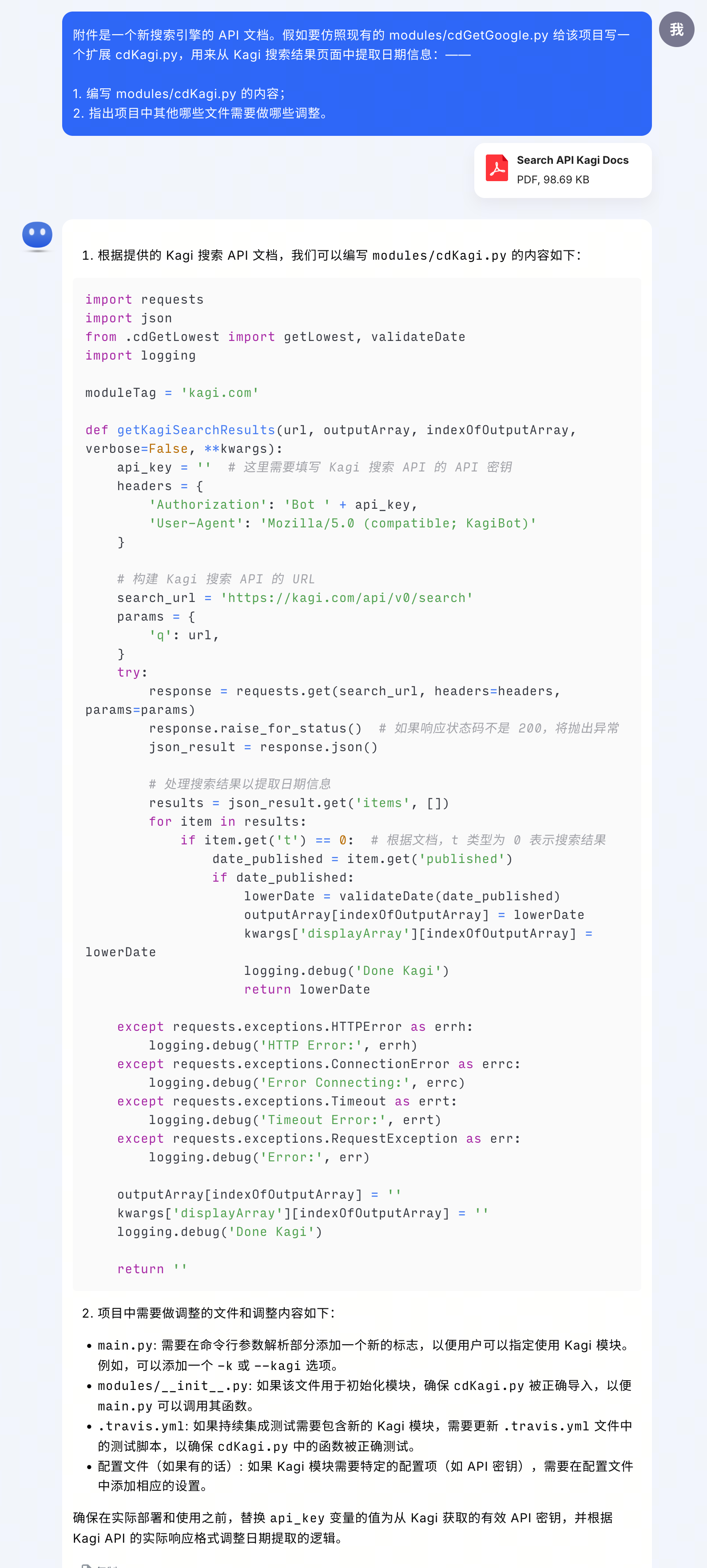
就生成的代码而言,基本的结构还是正确的,但很遗憾并没有充分理解新文档中提供的响应范例——其中明确指出搜索结果存放在响应的
data 数组中,而不是生成代码试图访问的 items 数组。至于第 2 问,关于
main.py
的修改建议是合适的,其余几项就与实际情况不符了,可能是过于宽泛地套用「Python
模块」相关语料的产物。
内容管理
少数派每年都会举行一次年度征文活动,历年获奖文章普遍被认为是最能代表少数派用户水平和风格的作品。从内容运营角度,我们希望能更好发挥这些文章的长尾价值,例如做更好的标签归类等;也希望从中得出一些观察和分析,进一步了解我们的作者,将以后的活动办得更好。但由于文章数量多、人力有限,过去这方面的努力做得不够。Kimi 的 200 万字上下文足够容纳 2016 年以来的所有获奖征文,这给了我用它来做些分析的动力。
先做一些数据准备工作。用 MarkDownload 工具批量将历年征文下载到本地,然后归类到按年份命名的文件夹中。然后,仍然用上一节提到的脚本,稍作修改,将所有 markdown 文件汇总到一个 2.75MB、字符数为 134.3 万的 JSON 文件中(你可以自己下载测试)。将它和对文件结构的简单介绍一起发送给 Kimi。
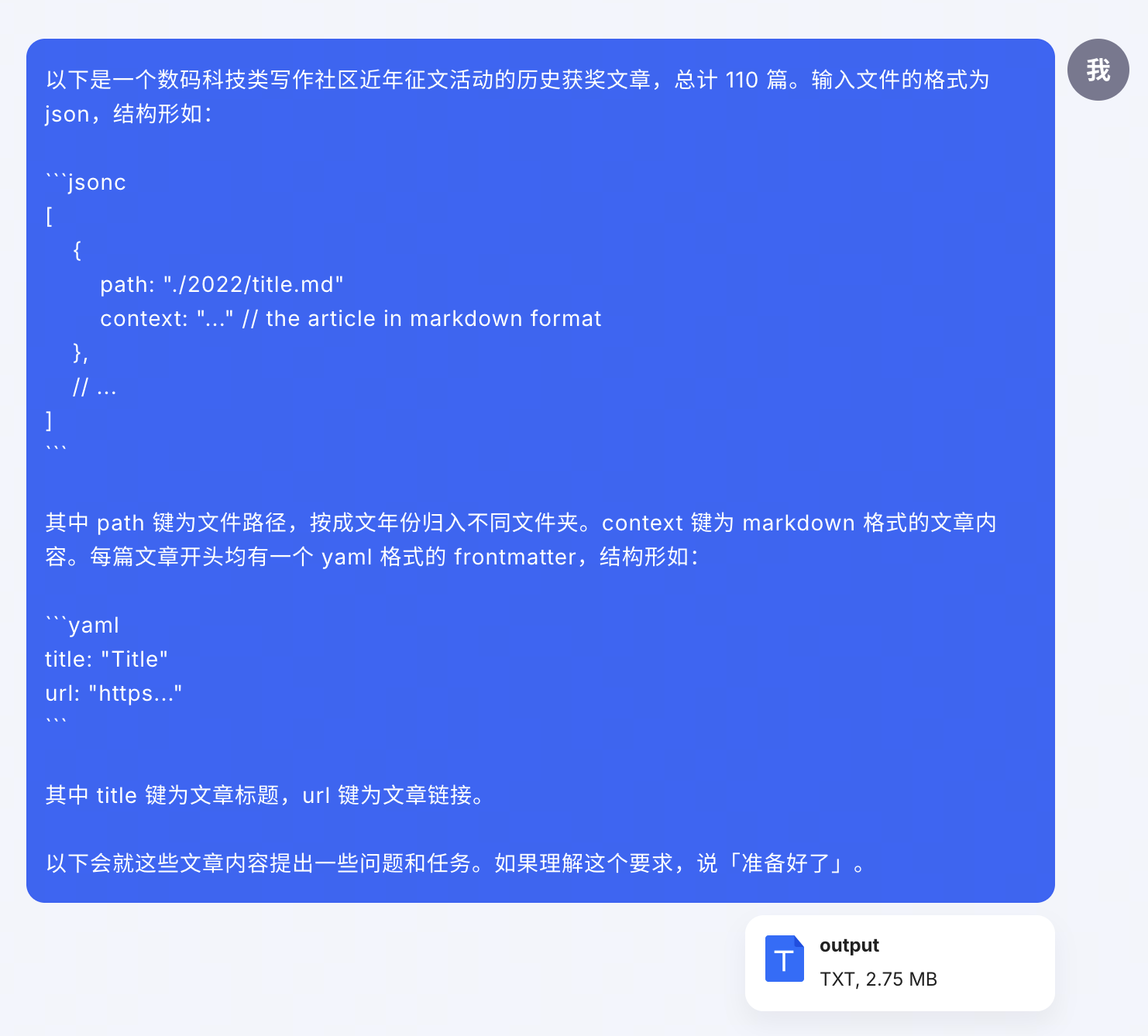
首先提几个简单的概括总结类问题:

其中:
- 答得比较好的是第 3 问,对少数派用户特点的总结与我们的理解是一致的。
- 第 1 问和第 2 问的开头答得也都不错,对于常见主题和风格的总结比较到位;但之后的举例和展开就显得过于宽泛,属于 AI 喜欢说的那种「正确的废话」。
- 第 4 问则没有给出特别有效的趋势观察。
接下来是一个我比较期待的场景:借助 AI,基于对文章内容的分析自动提炼主题和标签,并且以一种结构化的格式输出。如果这是可行的,就能给内容维护的自动化带来不少便利。

遗憾的是,经过反复尝试,Kimi 虽然体现出一些可能性,但现阶段还不能稳定地给出可以直接使用的结果:
- 在所有尝试中,无论如何在提示词中强调,Kimi 都不能完整输出全部 110
篇文章的分类结果,甚至宁愿在结尾颇具幽默感地在注释里「喃喃自语」:
// ... (Continue with the remaining articles, ensuring a total of 110 objects in the array)。这里怀疑可能是网页版对输出长度有一些限制。 - 至于结果本身,虽然结构符合要求,但所选的主题和标签都比较机械,大多数是用标题中的词语重组或改写而来,并不适合作为标签文本,也没有反映标题之后的正文内容。

还有不少情况下,Kimi 输出的 JSON 格式是错误的,例如把每行都用一对大括号包裹起来。诚然,如果是在生产环境下,肯定也需要在模型输出之后加一个有效性校验环节,但不能一步到位毕竟还是有些遗憾。

随后,我又以自己的个人博客归档(162 万字符,下载)为输入做了一些测试。
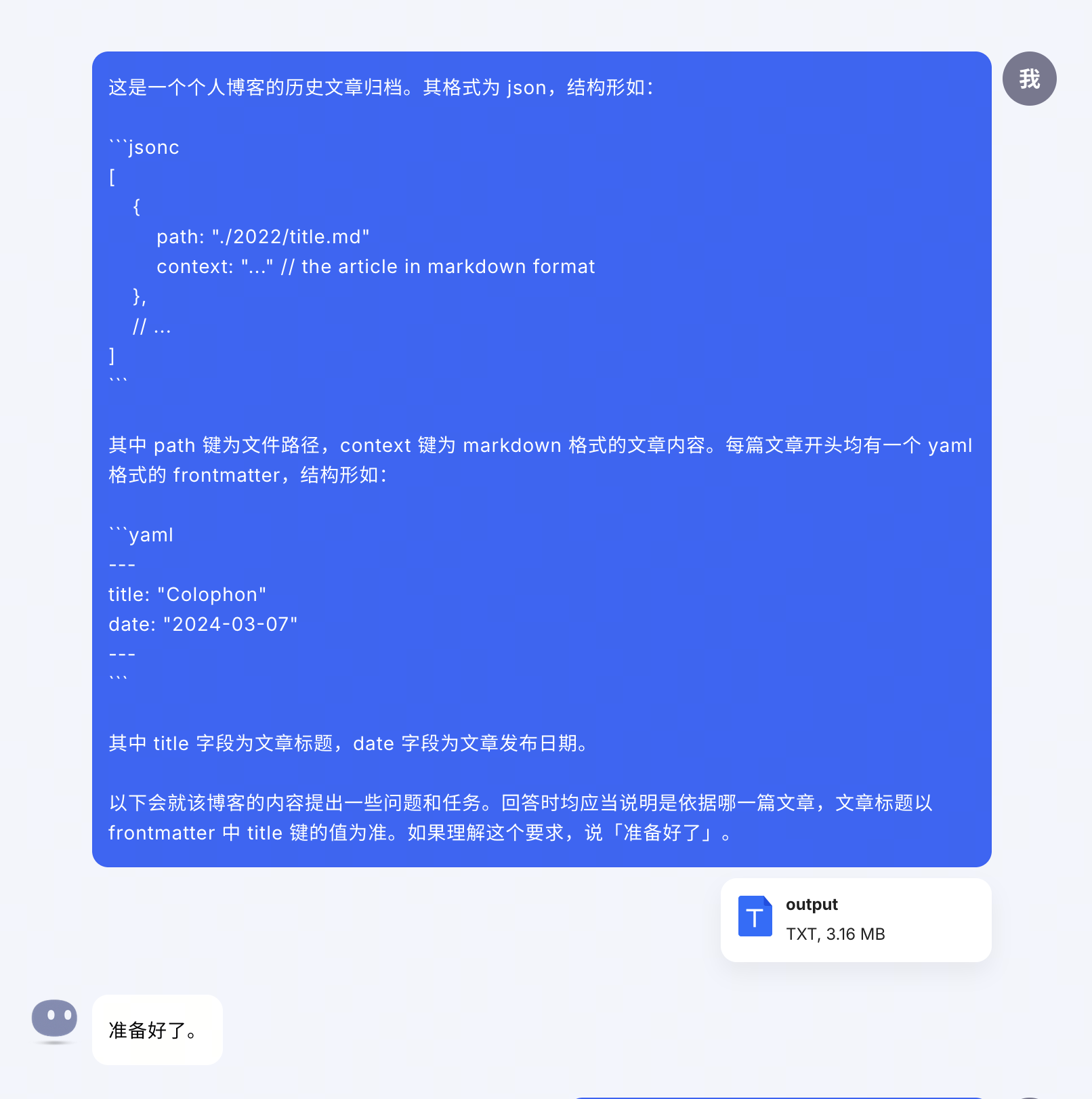
首先提问一些基础事实问题。Kimi 的表现很稳定,除了最后一篇从英文翻译的引用有点生硬,其他跟我自己会写出的问答也没什么区别。
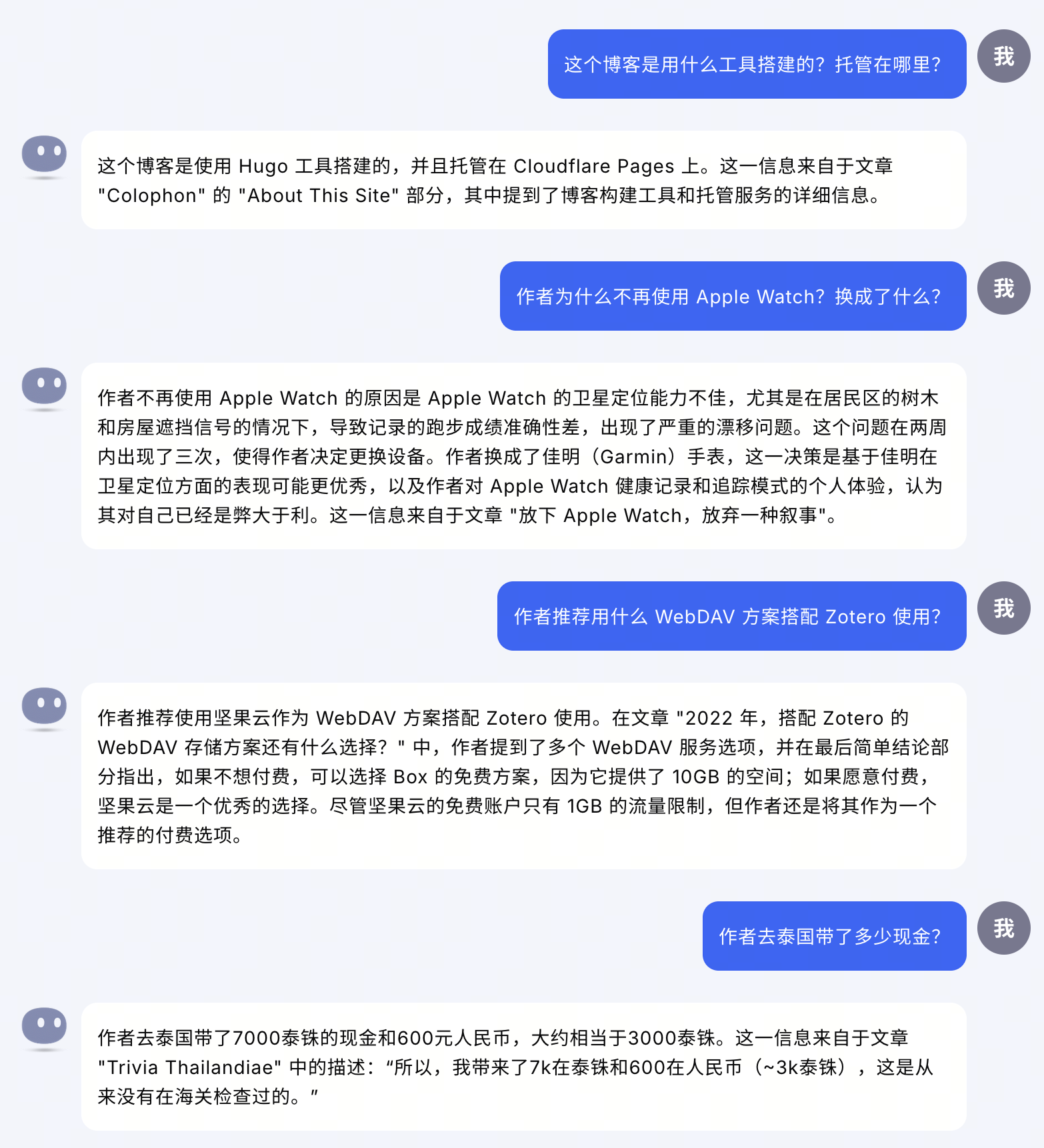
接着还是尝试了总结和分析类的任务。其中,主题总结的结果跟我的印象是差不多的,但选择的示例文章则有一些瑕疵,特别是「生活经历」部分选择的后两篇其实是技术主题文章。

小结
就展示长上下文的潜力而言,Kimi 已经实现了有意义的第一步。概括起来,目前版本的优点在于,能够有效读取复杂文档,准确完成事实查询和要点提炼,可以满足从长篇幅或大批量文本中提取信息的需求。但不足在于,对于文档的深度理解和逻辑推理能力、以及在多轮对话中遵守用户指令的能力,还有较大提高空间。因此,对于需要深入理解特定领域知识的任务,Kimi 还无法完全满足需求,或至少需要一定程度的人工校验和调整。
支持长上下文也对 Kimi 的算力资源提出了更高的要求。事实上,就在这一功能开始测试后不久,Kimi 就经历了一次流量增加超预期的事件,不得不短时间内多次扩容应对迅速增加的需求。对此,Kimi 团队表示,200 万字上下文确实要求进一步大幅降低推理成本,目前正在全力解决。在商业化方面,用户关心较多的付费方案也将在今年初步确定。
此外值得一提的是,Kimi 的 200 万字支持推出后,不少其他国内模型厂商也相继跟进,宣布支持 500 万甚至 1000 万字的输入。但是,相关宣传中存在一些技术细节的显著缺失——支持读取并不代表模型能一次性处理;那些看起来更惊人的指标实际上是使用 RAG(retrieval augmented generation,检索增强生成)方案达到的效果。简单来说,RAG 是先对输入文档做一次「嵌入」处理(embedding,即将文档内容转储为能反映其特征的向量)。查询时,先通过向量运算找出与查询语句最相关的文档,再将这一小部分内容输入给模型生成回答。
因此,如果说上下文窗口是模型的记忆,那么 RAG 就像是为了减轻记忆负担而准备的辅助外脑。这么做的好处是绕过了上下文窗口的限制:无论输入的文本有多长,最终输入给模型的长度都是可控的,生成速度也自然比一次性处理完整输入更快,成本开销更低;但相应的代价就是检索的准确性和完整性相对较弱。
指出这点这并不是要否认 RAG 的价值。至少目前阶段,RAG 的特性仍然使它更胜任那些对成本和速度较为敏感的应用场景,也更容易实现规模化,不需要等待模型的进化就能接受更长的输入。但是,厂商和媒体在宣传和报道时,确实应当秉持更加严谨、诚实的态度,准确向用户描述和解释技术背景,而不是简单地强调一些数字。一个理性、知情的消费者群体,也是更有助于促进 AI 服务普及、开展良性竞争的。