付费墙的短与长(二):怎样有效保存已订阅内容
A version of this article appears on Jul. 12, 2023 on SSPAI as a member-only post. Learn more or subscribe
The article is permitted to be self-archived in the version as originally submitted for publication on the author’s personal website under CC BY-NC 4.0 pursuant to § 5.2(b) of the SSPAI Fellowship Contributor Agreement.
在本系列的上篇中,我们讨论了当今付费墙的主流类型,并介绍了付费墙的常见实现机制。但比起这些理论问题,一般读者更关心的一个实际问题可能是:如何有效地保存已经购买的付费内容?这就是本次要讨论的话题。
使用稍后读服务:「为何不行」与「如何才行」
对日常用户来说,最常接触到、门槛最低的付费内容保存方法,大概就是使用各类「稍后读」服务了。但正如你可能已经通过实践发现的,稍后读服务并不总能很好应对这种场景。
因此,这里我们要解决的问题就是 (1) 为什么稍后读抓不到付费墙后的文章,以及更重要的,(2) 怎样才能抓到。
让我们先回顾一下稍后读服务保存网页的一般流程(有「一般」就有「特殊」,但别急我们慢慢来):
- 你告诉稍后读服务一个要保存内容的网址;
- 稍后读服务从自己的服务器访问那个网址;
- 稍后读服务从打开的页面上试图找出文章内容并保存。
很显然,如果你要打开的文章有付费墙,稍后读服务很可能会卡在第 2 步:它的服务器没有你的付费账户登录信息,也就看不到完整的付费内容。
但凡事都有例外。让我们来做一个简单的实验。
在一台有公网 IP(或者设置了内网穿透)的电脑上随便新建一个目录,比如 test;然后在里面放一个 paywall.html 的网页,内容可以看心情随便打两行:
<html>
<p>Thank you for being our valuable customer!</p>
<p>You can check out any time you like, but you can never leave!</p>
</html>
(这个语法显然是缺胳膊少腿的,但我们只是为了「在这个舞台上玩」,所以不要在意。)
现在,在 test 目录运行:
npx http-server --username user --password pass --log-ip
(依赖 npm;我知道可能有一千种方法来起一个简单的 HTTP 服务器,用这个方法只是因为 npx 不用配环境、可以即用即抛,以及 http-server 的默认日志样式比较清楚。)
这样,我们就有了一个位于 http://{your_ip}:8080/paywall 的「付费墙」内容,它受到 HTTP 基本认证的保护,只有输入用户名和密码才能看到「文章」。
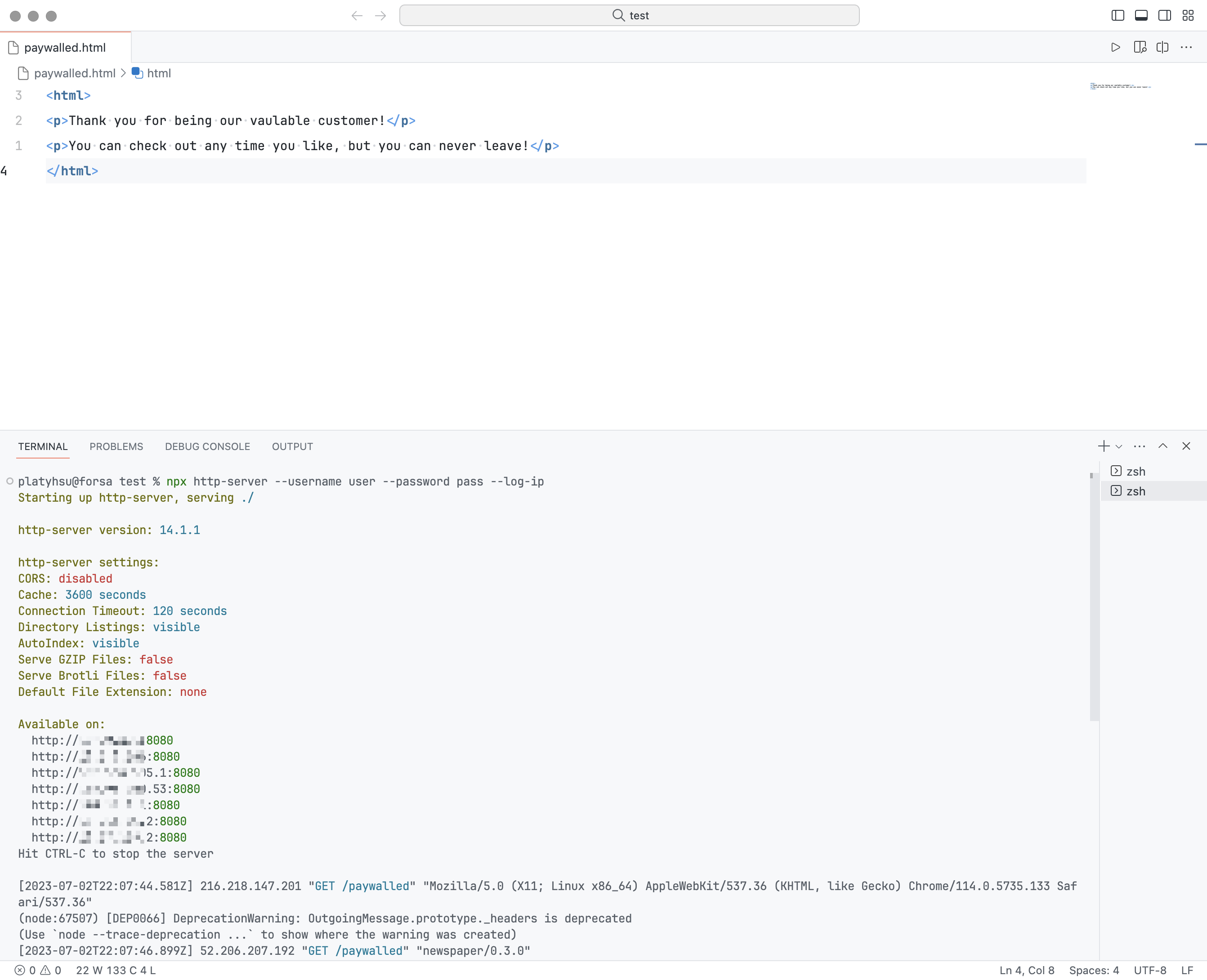
现在,我们尝试在稍后读服务网页版界面中添加并保存这个链接。
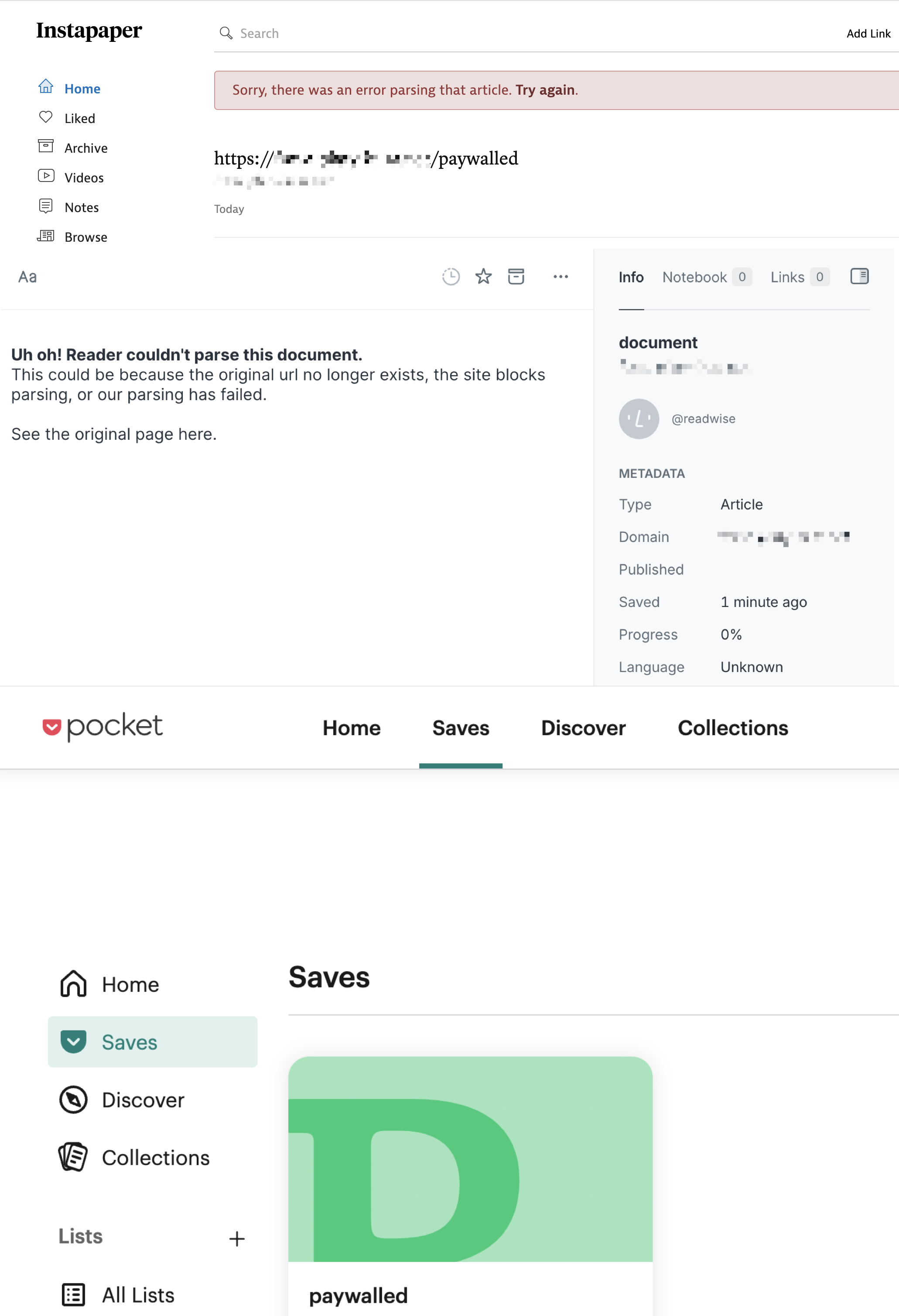
可以看到,Instapaper、Matter、Pocket 和 Readwise Reader 这些主流工具都不能抓取到「正文」内容。这是意料之中的,因为它们的服务器无法绕过我们设置的密码。
现在我们换一种方法。 删掉刚才保存失败的文章,直接在浏览器里访问这篇「付费文章」,输入用户名 user 和密码 pass 解锁,然后用这些稍后读服务各自的浏览器插件来保存。
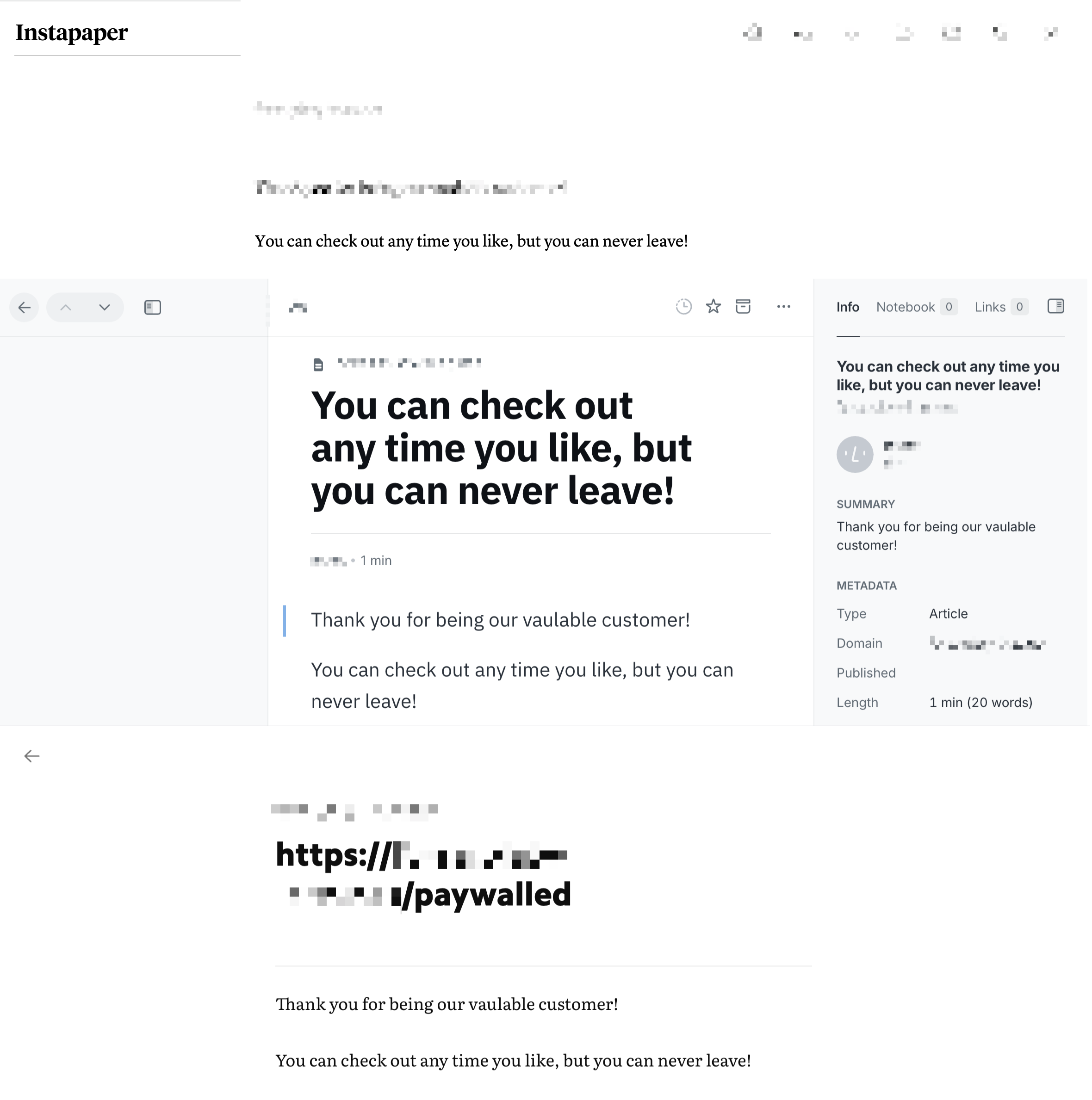
可以看到,Instapaper、Readwise Reader 和 Matter 这回都成功保存了密码保护的内容。(从 Pocket 被 Mozilla 收购后不务正业的记录看,它成为唯一的吊车尾也是可以理解的。)
这是怎么做到的?敏锐的读者从 http-server 的日志就可以看出端倪:在第二次保存的时候,那些稍后读服务的服务器根本没有向我们的「付费文章」发出请求。
其实,当使用很多稍后读服务的浏览器插件保存网页时,网页内容根本不是它们「抓」下来的,而是我们主动「送」上门的:观察网络活动就会发现,点击 Instapaper、Readwise Reader 和 Matter 的浏览器插件按钮时,都会触发一个指向它们各自 API 端点的 POST 请求,其内容正是加载完成的网页全文 HTML。
<figure" data-figcaption="Instapaper 和 Matter 浏览器插件向 API 端点 POST 的网页完整内容">


因此,我们就知道了用稍后读保存付费内容的「正确姿势」:只要先用浏览器加载出完整的付费内容,然后使用稍后读服务的插件保存就行了。相反,在链接上点击右键保存,或者在稍后读服务中使用添加链接功能保存,都不能让稍后读服务「看到」完整的网页,也就不能存下完整的付费内容。
在理解原理的基础上,我们甚至可以利用这个机制,让稍后读不仅能保存下付费内容,而且按照我们想要的格式保存下内容。 例如:
- 对于英文付费内容,可以先用「沉浸式翻译」这样的插件将内容页面翻译一遍,然后再使用插件保存,就能存下经过翻译的内容;

- 对于稍后读服务不能很好处理的复杂页面,可以先用「检查元素」(DevTools)或者广告拦截器删除页面上的内容无关元素,然后再用插件保存,就能避免这些元素混入存下的版本。
类似的机制和用法也适用于 iOS。 你或许没有意识到,当你在 Safari 中使用「分享」菜单连接第三方应用时,它们获得的并不是一个单纯的网址,而是一个称为「Safari 页面」的复合对象,其中包含了 (1) 网址、(2) 网页 HTML 对应的富文本,以及 (3) 从网页中提取的文章(即「阅读器」功能抓取到的结果);被连接的应用可以按需从中提取。
(你可以通过将页面分享给只有一个「内容项目图」(Content Graph)步骤的快捷指令,很清楚地观察到这一点。)

「Safari 页面」通过分享菜单传输的完整内容
包括前面提到的主流稍后读工具在内,很多第三方应用都可以通过读取 Safari 分享页面中的 HTML,获取 Safari 加载完成的网页内容,从而无需再自行抓取、也不受付费墙限制。 当然,实现这个效果的前提是从已打开的 Safari 页面分享(也包括从第三方应用中点击链接打开的 Safari View Controller);长按链接分享、或者用第三方浏览器分享都是不行的。
至于 Android 用户——很遗憾,尽管 Android 在理论上也支持通过分享菜单传输富文本内容,但据我测试,目前还没有哪个浏览器支持「分享」出当前浏览的页面内容,包括「亲生」的 Chrome。
最后需要指出,还有很多其他能让稍后读服务保存到付费墙后内容的方式,只是都不具有普适性。 例如,我们在上篇介绍过很多新闻媒体采用的「软性付费墙」机制:其特点是在访问限制的执行上「睁一只眼闭一只眼」,很多时候只要重置 cookies 或者换个 IP 就会放行,甚至还会直接对机器抓取「开小灶」。对于这种软性付费墙后的内容,稍后读服务不需要任何处理就能获取到。
又比如,稍后读工具可以允许用户输入付费服务的账户信息,或者保存 cookies 等登录凭据,这样也可以在操作上让付费墙变得「无感」。事实上,Pocket 曾经就针对一些主流英文订阅提供过这种功能,但后来不知何故取消了。
使用网页存档插件:SingleFile 和 markdownload
稍后读服务虽然方便,但存下来的东西毕竟还是「寄人篱下」的状态,可用性取决于服务本身持续经营,有的还需要持续付费;如果出了什么变故,并不能很方便地备份和迁移。要追求稳妥和可控,还是得把内容存为本地文件。
但这也是说起来比做起来难。那个网页能像 Word 文档一样随便「另存为」的时代早已离我们远去了。特别是包含付费墙的网站,如我们在上篇中分析,其实现方式大都重度依赖 JavaScript 框架:在很多情况下,网页源文件本身接近一具空壳,实际内容都是在验证权限后,通过脚本实时加载和注入到页面的——一种不好听但有效的比喻是「冬虫夏草」。
因此,即使保存了登录状态下的网页,很多时候也是没什么用的,事后打开只能看到空空如也或者布局错乱的页面。
一些专门为完整保存网页而生的插件可以提供帮助。其中,目前最完善和最好用的恐怕还是 SingleFile。
简单来说,SingleFile 可以帮你把网页保存成一个「自成一体」、可以离线打开、不含 JavaScript 脚本,并且版式效果和原版几乎一致的存档版本。这是通过重整网页结构、将图片和外链资源作为 base64 编码或 data URI 嵌入,以及移除无用元素等一系列处理步骤实现的。
除了保存效果好,SingleFile 特别适合存档付费内容的原因还在于对批量和自动化操作的完整支持。几个我特别喜欢的功能包括:
- 可以通过右键菜单批量保存当前窗口所有打开的标签页,或者当前页面所有选中的链接。这样,我可以先打开订阅内容浏览一遍,留下感兴趣篇目的标签页,然后批量保存;如果是数字版杂志那种有目录页的内容,直接选中目录页就可以批量下载整期。
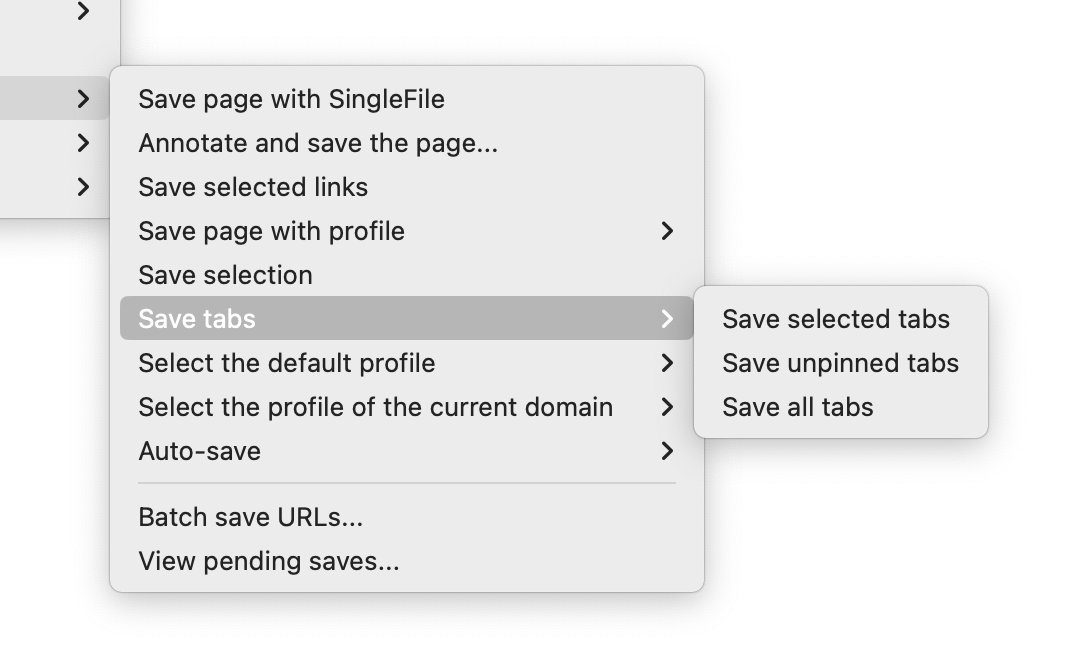
- 可以手动添加一行一个的网址列表,批量保存。这样,如果你用的其他笔记或者书签工具支持 CSV 等导出格式,简单提取后就可以输入给 SingleFile 保存。
- 可以开启「自动保存」模式,让所有打开的标签页被自动保存。这样,你可以在每次浏览订阅内容的同时打开这个模式,等你「检阅」完一遍,内容顺便就都保存下来了。懒人福音。
值得一提,上节讨论用稍后读服务保存付费内容的操作技巧时,曾提到必须先等待网页加载完成,否则稍后读插件就不能保存下完整的内容。这个问题对 SingleFile 是不存在的;如果保存队列里的网页没有打开,它会先自动加载,确认加载完成后才会执行保存步骤。
此外,如果你是对墨水屏阅读器用户,SingleFile 可能对你尤其有用。 原因在于,Android 系统上很多电子书阅读软件(包括 KOReader、Librera、Moon+ Reader,以及文石等品牌自带的阅读器)都支持直接打开 HTML 文件——这并不奇怪,因为 EPUB 本质上就是打包的 HTML 文件集合。同时,SingleFile 在支持扩展的 Android 浏览器(包括 Kiwi、Fennec、Mull 等)上也能很好地运行。
因此,我个人非常推荐的一个读长文方式,就是 (1) 直接在墨水屏设备上访问订阅内容,(2) 用 SingleFile 保存成 HTML 版,然后 (3) 用 KOReader 打开阅读。由于这些 EPUB 阅读软件是专为墨水屏优化的,其效果比只考虑了液晶屏幕的稍后读客户端要好得多。读完之后,还能顺便收获一份付费内容的原样存档,何乐而不为呢?

(注:SingleFile 也可以从命令行运行,理论上这样更方便以脚本方式自动化。但如上面讨论,很多依赖 JavaScript 加载的付费内容需要经过完整加载才能正确保存,而这里的「完整加载」一般也隐含了「在图形环境下渲染」的要求;用「无头」(headless)模式渲染往往是不够的。因此,本文不做推荐和具体展开。)
插曲:关于网页存档格式的选择
尽管 SingleFile 保存完整页面的能力堪称黑魔法,但正如它自己承认,这并不是图书馆、学术研究等专业存档用途的正确选择。之所以这么说,原因不在于实力,而是 SingleFile 并未考虑到专业场景的特殊需求,例如没有完整的格式标准,没有记录完整的、反映存档时间和存档方式的元信息(metadata)。这种需求应当使用 WARC (Web ARChive,前身为 ARC_IA)格式来满足。如果你用过 Internet Archive(互联网档案馆)的网页时光机(Wayback Marchine)功能,其背后使用的格式就是 WARC;它也是美国国会图书馆等专业互联网存档机构推荐的格式。但对于日常用户而言,WARC 的保存和浏览都需要专门工具,比较繁琐,额外能保存的元信息一般也用不到,因此没有必要专门舍近求远去使用。
另外,Chrome 等浏览器的「另存为」对话框还可以选择一种 MHTML 格式。这是一种比较古老的网页存档格式,也可以实现把包括图片在内的完整页面内容保存下来。实际上,MHTML 格式只是换了个扩展名的电子邮件格式(EML),它的开头就是来源、日期、主题等电子邮件抬头信息,资源文件也以类似于邮件附件的形式存储在文件尾部。但是,MHTML 不能很好地应对当前网页上充斥的动态加载元素,保存下来的页面经常会有错位。因此,如果你要保存的网站正好能用 MHTML 相对完整地保存,但用无妨;但如果要追求更好效果,SingleFile 还是正解。
最后,使用 Safari 浏览器的用户或许还知道,它在保存网页时可以选择一种 webarchive 格式;DEVONthink 之类的苹果平台应用程序有的也支持把网页抓取成这种格式。但是,webarchive 格式的最大问题在于它是苹果私有的,既没有公开标准,也不被任何其他主流浏览器支持。与开放格式相比,webarchive 的保存效果一般稍好于 MHTML,但远不及 SingleFile 制作的 HTML 和 WARC。因此,本文不推荐读者使用这种格式。
当然,对于图文类付费内容,我们很多时候也不需要保存完整网页,只需要其中的文章部分就够了;并且相比于比较「笨重」的 HTML 版本,纯文本 markdown 格式可能是更为轻量和易用的选择,也更容易融入现有的各种知识管理流程。
如果这种描述符合你的需求,那么 markdownload 值得一试。它的运行原理是先使用 Readability.js(Firefox 用来产生阅读模式的代码)获取网页上的文章内容,然后转化为 markdown 格式输出。
markdownload 也提供了丰富的定制选项和自动化能力,几乎就像是 SingleFile 的 markdown 版本:可以选择是保存网页局部还是整个网页;保存当前网页还是所有已打开的网页;文中配图是按原样链接还是下载到本地再嵌入;所生成 markdown 的文件名模版、内嵌元信息(frontmatter),以至语法风格也可以按需调整。
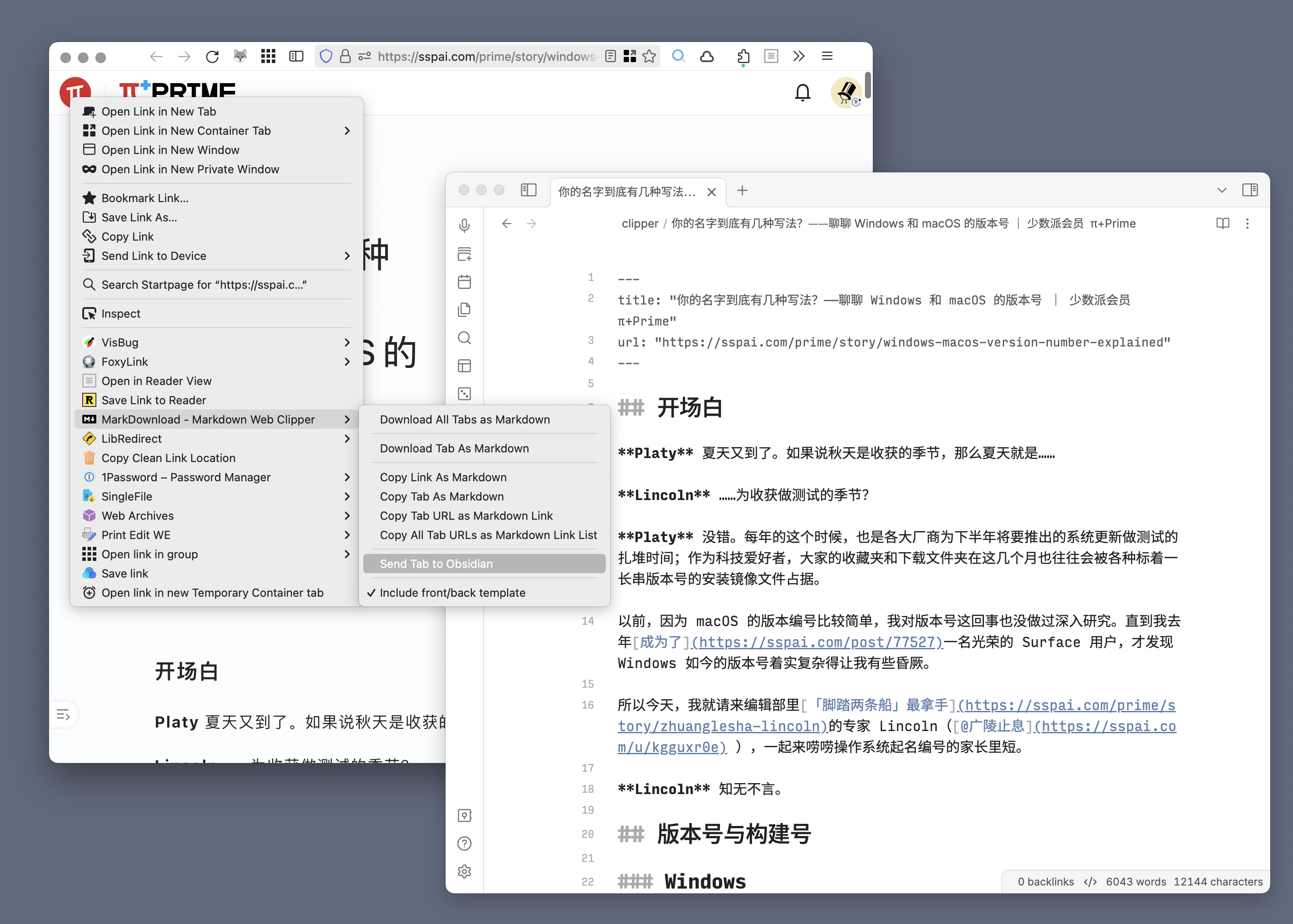
特别值得一提,如果你是 Obsidian 用户,还可以通过它内置的 URL Scheme 支持,直接把文章内容抓取到笔记库(需要先安装 Advanced Obsidian URI 插件)。
代结尾:关于付费内容存档的合理性
(显然,这段中涉及法律问题的部分仅供参考,不构成任何法律建议;IANAL。)
对于保存付费墙后的内容,一个不能回避题就是这么做是否妥当;相关的考虑因素有法律上的,也有「道德」上的。
本文假定读者试图保存的是已经付费订阅的内容,这个前提本身带来了一些正当性基础,但并不能消除所有的模糊。概括和一般意义上,当你付费订阅内容时,其本质是内容方作为受版权保护内容的所有者(或有权传播者),以你支付订阅价格并遵守订阅条款为对价,在订阅期内授予你一项访问这些内容的有限许可。
因此,对于内容保存是否合适的问题,首先应当查阅的是你与内容方的协议,然后再看版权保护相关法规作为补充。
相对理想的情况是协议中直接规定可接受的保存方式。例如,《华尔街日报》的订阅协议允许用户「偶尔从服务中下载和存储文章供个人使用」(§ 8.2.3);《纽约时报》的服务条款允许用户「下载或复制服务上展示的内容和其他可下载项目,且仅供个人使用」(§ 2.3)。
但能在条款中明确提到这一点的毕竟还是少数;现实中,很多内容方或是因为起草能力不够,直接搜一个宽泛模板,抄抄改改就当成自己的协议,根本没考虑到内容保存的问题;或是以自己解释起来方便为优先,有意略去了明确规定。
(如果你是在少数派会员内容中看到这篇文章,欢迎拿这篇文章做实验道具:会员服务条款允许在合理范围内下载或复制会员服务包含的内容,包括在合理范围内与他人分享。条款正好是我写的;我正好比较烦让我猜。)
如果遇到这种规定不明的情况,用户还可以从版权法的合理保护原则中找到依据。根据伯尔尼公约和国内的著作权法,因「个人学习、研究或者欣赏」而使用受保护作品,可以不经许可且不付报酬,前提是「不得影响该作品的正常使用,也不得不合理地损害著作权人的合法利益」。
(读者或许也会接触很多美国订阅服务;美国版权法也有类似制度,但明确规定在判断是否构成「合理使用」时考虑四个方面:使用的目的和性质、作品的性质、使用部分占作品的比重,以及对作品潜在市场或价值的影响。)
这里我们可以认为,保存已经购买的内容供个人使用,性质上不是为了营利,也不影响内容方的服务稳定和向他人销售,因此可以解释为无须特别许可的「合理使用」。
当然,这只是一种比较简单的讨论。如果在保存过程中使用自动化工具,那么可能和使用条款里一般都会有的「禁止爬虫」之类的条款发生抵触;如果为了完整保存页面而使用了屏蔽、改写付费墙脚本之类的技术手段,可能还会涉及是否构成版权法禁止的「绕过技术保护措施」的问题;此外,一篇内容可以保存几份副本、一次可以存几篇不同内容、能以多高的频率与多少人分享保存的内容,也没有明确标准。这些问题在实际案例和学术讨论中都没有定论,本文也无法给出一个简单的「行」或「不行」作为答案。
但无论如何,任何付费墙都是收益能力和传播能力之间的权衡,也是付费用户对免费用户(包括会「搭便车」和「耍机灵」的用户)的交叉补贴。一方面,内容方如果把尺度收得太紧,只会让内容见不到光,对自己也没有好处。但另一方面,如果人人都选择搭便车或者薅羊毛,最终的结果也是人人无内容可看。因此,比起硬性的规则,付费墙两侧的双方能彼此理解、在力所能及的范围内互行方便,才是变隔阂为桥梁的正道。